
大数据-spark理论(2)算子,shuffle优化
导读目录
第一节:代码层面
1:RDD创建
2:算子
3:数据持久化算子
4:广播变量
5:累加器
6:开发流程
第二节:Shuffle优化层面
1:Shuffle
2:调优
第一节:代码层面
(1)RDD创建:
Java:
sc.textfile
sc.parallelize()
sc.parallelizePairs(得到KV格式的RDD)
Scala:
sc.textfile
sc.parallelize //如果不指定分区数,用的是系统的默认分区数
makeRDD //如果不指定分区数,会为每个集合对象创建最佳分区
窄依赖:
一个Partition中的数据,或多个Partition中的数据放在一个Partition中。
宽依赖:
一个Partition中的数据分发到多个Partition中。
(2)算子:Transformation(转换算子)与 Action(执行算子)
32个算子:https://blog.csdn.net/Fortuna_i/article/details/81170565
(3)数据持久化算子:
3.1 意义:
对于迭代计算,交互运算之类的,应用可以不用再运行之前的RDD,这样效率会大大提升。
即:源数据---经过操作--->action A
源数据---经过操作--->action B
如果在经过操作之后把数据持久化了,那么后面的action B就不用从源数据再走一遍了。
3.2 概念:
控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化,持久化的单位是partition。cache和persist都是懒执行的。
必须有一个action类算子触发执行。checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系
3.3 使用:
3.3.1 cache:
直接将数据保存到内存,相当于无参数的persist():
cache()=persist()=persist(StorageLevel.memory_only)
例子:
JavaRDD<String> lines = jsc.textFile("./NASA_access_log_Aug95");
lines = lines.cache(); //使用cache()算子。
long count = lines.count(); //count是action算子,到这里才能触发cache执行,所以这一次coun加载是从磁盘读数据, 然后拉回到drive端。
long countrResult = lines.count(); //这一次是从内存中读数据。
3.3.2 Persist:
可以设置数据保存的级别
1.MEMORY_ONLY
使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个RDD执行算子操作时,
那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用cache()方法时,实际就是使用的这种持久化策略。
2.MEMORY_AND_DISK
使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,
持久化在磁盘文件中的数据会被读取出来使用。
3.MEMORY_ONLY_SER
基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,
从而可以避免持久化的数据占用过多内存导致频繁GC。
4.MEMORY_AND_DISK_SER
基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,
从而可以避免持久化的数据占用过多内存导致频繁GC。
5.DISK_ONLY
使用未序列化的Java对象格式,将数据全部写入磁盘文件中。
6.MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等
总结:对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制
主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。
如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。
1、MEMORY_AND_DISK 意思是先往内存中放数据,内存不够再放磁盘
2、最常用的是MEMORY_ONLY和MEMORY_AND_DISK。”_2”表示有副本数。
3、选择的原则是:首先考虑内存,然后考虑序列化之后再放入内存,最后考虑内存加磁盘。
4、尽量避免使用“_2”和DISK_ONLY级别。
5、deserialized是不序列化的意思。
3.3.3 Checkpoint:sc.setCheckpointPath(“持久化的路径”)
应用:
将数据保存到制定的目录中,使用于非常长的RDD迭代的情况
原理:
1.Spark job执行完之后,spark会从finalRDD从后往前回溯。
2.当回溯到对某个RDD进行了checkpoint,会对这个RDD标记。
3.回溯完成之后,Spark会重新计算标记RDD的结果,然后将结果保存到Checkpint目录中。
优化:
1.因为最后是要触发当前application的action算子,所以在触发之前加一层cache操作,一样会往前执行cache操作,实现对数据的cache ,
所以考虑将cache优化到checkpoin的优化流程里。
2.对RDD执行checkpoint之前,最好对这个RDD先执行cache,这样新启动的job(回溯完成之后重新开的job)只需要将内存中的数据
(cache缓存好的checkpoint那个点的数据)拷贝到HDFS上就可以。
3.省去了重新计算这一步,不需要重头开始来走到checkpoint这个点了。
以上持久化算子的不同:
Cache
内存中,如果数据丢失,可以依靠前面的RDD血统关系恢复;
属于懒执行,需要action算子才能触发;
cache算子的返回值可以赋值给一个变量,在其他job中直接使用这个变量就是使用持久化的数据了。单位是partition。
cache算子后面不能直接跟执行算子
rdd.cache().count()(因为cache算子返回的是一个RDD,直接跟执行算子返回值就变了,Persist同是)。
Persist
有级别,可以持久化磁盘,但是实际是持久化到了blockManager中,如果执行结束,数据将会消失;
属于懒执行,需要action算子才能触发;
Persist算子的返回值可以赋值给一个变量,在其他job中直接使用这个变量就是使用持久化的数据了。单位是partition。
Persist算子后面不能直接跟执行算子。
Checkpoint
磁盘中,永久保存在hdfs文件系统中,只有手动删除;
懒执行;
Checkpoin不仅存储结果,还会存储逻辑,还可以存储元数据;
切断了RDD之间的依赖关系;
(4)广播变量:
4.1 定义:
一个变量,大家要用,那么就要每个节点都要有一份,这样不好,所以广播一下,这样就只会有一份,大家共用一份。
4.2 语法:
broadcast:广播变量
broadcast.val:获取广播变量的值
4.3 例子:
val list = List("hello java")
val broadcast = sc.broadcast(list) //广播
broadcast.value //调用
4.4 注意:
1:只有变量值才会被广播,RDD不会
2:广播的变量在Driver生成,只有修改了driver的变量才会生效,如果executor端修改了,不会产生影响。
(5)累加器:
5.1 定义:因为executor值的变化,不会对driver产生影响,所以有了累加器,可以统计所有executor上值的和
5.2 语法:
accumulator:定义
accumulator.val:获取值
5.3 例子:
val accumulator = sc.accumulator(0); //创建accumulator并初始化为0 accumulator.add(1) //有一条数据就增加1 accumulator.value //获取值
(6)开发流程
6.1 Jar包引入:spark-assembly-1.6.0-hadoop2.6.0
6.2 创建:main:
SparkConf() //配置 .setAppName(“wc”) //api名称 .setMaster(“local”) //运行模式:local本地(用于测试),standalone自身的分布式,yarn,mesos不用 SparkContext() //上下文 SQLContext() //启动sparksql Sqlc.read().format(“json”).load(“path”) //读取json格式文件,生成dataframe HiveContext() //读取hive中的数据 Sc.stop() //关闭上下文对象
第二节:优化层面
1、Shuffle:
源码阅读:https://blog.csdn.net/weixin_41705780/article/details/79399192
2.0可以用sparkRDMA,优化shuffle
(1)shuffle寻址 https://blog.csdn.net/LHWorldBlog/article/details/80822717
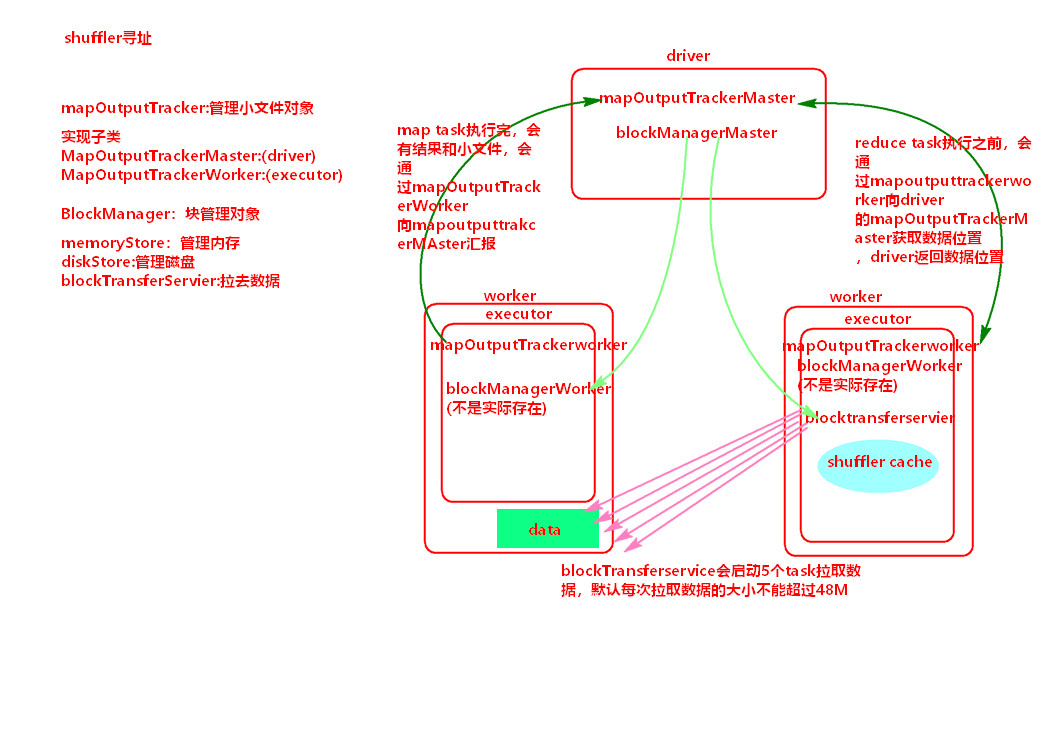
(2)内存管理
静态内存管理(将被淘汰)
统一资源管理

(3)方式
HashShuffle //已经淘汰,内存比例固定,容易导致OOM,也会导致内存浪费
SortShuffle
普通模式:
Bypass模式:partition个数小于200时候触发,触发这个是不需要进行聚合操作
2、调优:
1:sparkconf.set("spark.shuffle.file.buffer","64K") --不建议使用,因为这么写相当于硬编码 --最高
2:在conf/spark-defaults.conf ---不建议使用,相当于硬编码 --第三
3:./spark-submit --conf spark.shuffle.file.buffer=64 --conf spark.reducer.maxSizeInFlight=96 --建议使用 --第二
spark.shuffle.file.buffer
默认值:32k
参数说明:该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如64k),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,
进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.reducer.maxSizeInFlight
默认值:48m
参数说明:该参数用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。
在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.shuffle.io.maxRetries
默认值:3
参数说明:shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。
如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败。
调优建议:对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。
在实践中发现,对于针对超大数据量(数十亿~上百亿)的shuffle过程,调节该参数可以大幅度提升稳定性。
shuffle file not find taskScheduler不负责重试task,由DAGScheduler负责重试stage
spark.shuffle.io.retryWait
默认值:5s
参数说明:具体解释同上,该参数代表了每次重试拉取数据的等待间隔,默认是5s。
调优建议:建议加大间隔时长(比如60s),以增加shuffle操作的稳定性。
spark.shuffle.memoryFraction 静态 |统一 spark.memory.storageFraction 0.5
默认值:0.2
参数说明:该参数代表了Executor内存中,分配给shuffle read task进行聚合操作的内存比例,默认是20%。
调优建议:如果内存充足,而且很少使用持久化操作,建议调高这个比例,给shuffle read的聚合操作更多内存,以避免由于内存不足导致聚合过程中频繁读写磁盘。
在实践中发现,合理调节该参数可以将性能提升10%左右。
spark.shuffle.manager
默认值:sort|hash
参数说明:该参数用于设置ShuffleManager的类型。Spark 1.5以后,有三个可选项:hash、sort和tungsten-sort。HashShuffleManager是Spark 1.2以前的默认选项,
但是Spark 1.2以及之后的版本默认都是SortShuffleManager了。tungsten-sort与sort类似,但是使用了tungsten计划中的堆外内存管理机制,内存使用效率更高。
调优建议:由于SortShuffleManager默认会对数据进行排序,因此如果你的业务逻辑中需要该排序机制的话,则使用默认的SortShuffleManager就可以;而如果你的业务逻辑
不需要对数据进行排序,那么建议参考后面的几个参数调优,通过bypass机制或优化的HashShuffleManager来避免排序操作,同时提供较好的磁盘读写性能。
这里要注意的是,tungsten-sort要慎用,因为之前发现了一些相应的bug。
spark.shuffle.sort.bypassMergeThreshold----针对SortShuffle
默认值:200
参数说明:当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作,
而是直接按照未经优化的HashShuffleManager的方式去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
调优建议:当你使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些,大于shuffle read task的数量。那么此时就会自动启用bypass机制,
map-side就不会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件,因此shuffle write性能有待提高。
spark.shuffle.consolidateFiles----针对HashShuffle
默认值:false
参数说明:如果使用HashShuffleManager,该参数有效。如果设置为true,那么就会开启consolidate机制,会大幅度合并shuffle write的输出文件,
对于shuffle read task数量特别多的情况下,这种方法可以极大地减少磁盘IO开销,提升性能。
调优建议:如果的确不需要SortShuffleManager的排序机制,那么除了使用bypass机制,还可以尝试将spark.shffle.manager参数手动指定为hash,
使用HashShuffleManager,同时开启consolidate机制。在实践中尝试过,发现其性能比开启了bypass机制的SortShuffleManager要高出10%~30%。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号