
大数据-storm理论
导读:
第一节:基础架构
1:编程模型
2:架构
3:数据传输
4:高可靠性
5:高维护性
6:数据处理方式
7:对比MR,SPARK
第二节:计算模型
1:spout
2:bolt
3:stream grouping
4:构建拓扑与提交
第三节:架构
第四节:部署
第五节:数据处理
1:同步计算
2:并发机制
第六节:flume+kafka+strom
1:kafka
2:strom兼容kafka
3:flume兼容kafka
第七节:容错机制
1:ACK
2:事务
第一节:基础架构
1、编程模型
DAG (Topology)
Spout(tuple)----->bolt(tuple)--->bolt(tuple)
Spout(数据推送源)
Bolt(数据处理源)
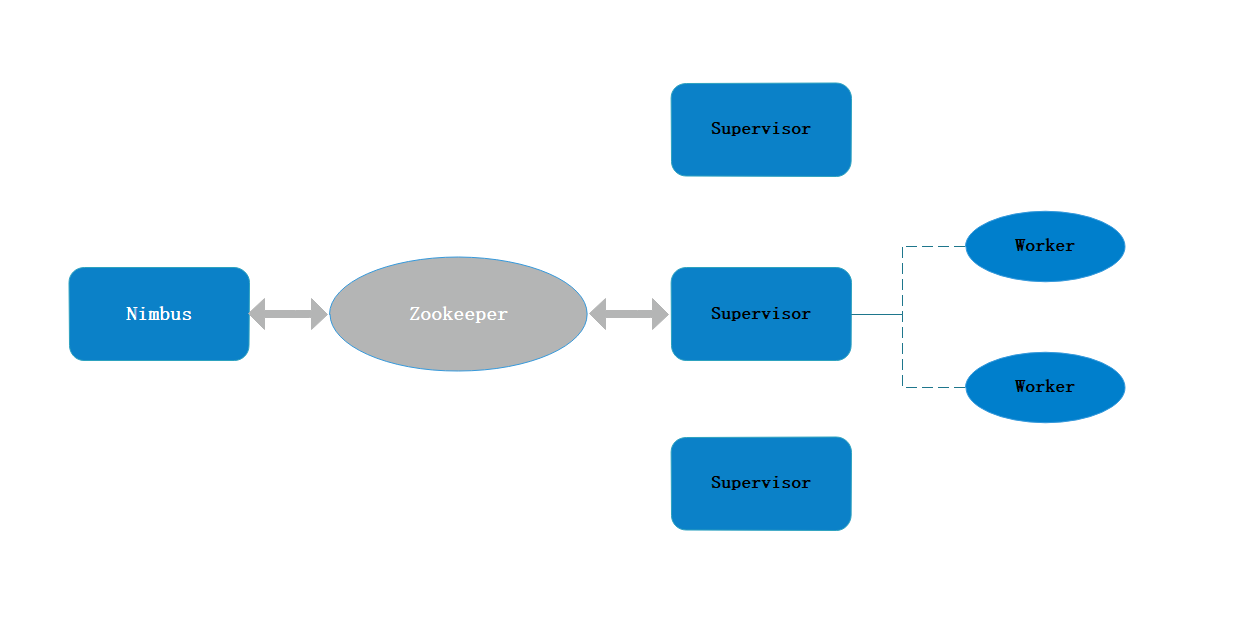
2、架构
Nimbus //主节点上的守护进程
资源管理
任务分配
Jar包任务的上传
Supervisor //从节点上的监督进程
接收nimbus分配的任务
启动、停止自己管理的worker进程(当前supervisor上worker数量由配置文件设定)
Worker //从节点上的工作进程
运行具体处理运算组件的进程(每个Worker对应执行一个Topology的子集)
worker任务类型,即spout任务、bolt任务两种
启动executor
(executor即worker JVM进程中的一个java线程,一般默认每个executor负责执行一个task任务)
3、数据传输
ZMQ(twitter早期产品)
Netty(现用的)
4、高可靠性
异常处理
消息可靠性保障机制(ACK):
不管在哪个bolt中出现问题,都会回到spout再次走流程,但是有问题,这个情况可以忽略。
5、可维护性
StormUI 图形化监控接口
6、数据处理方式
(1)、异步:无应答
client--->消息队列(kafka等)--->strom--->结果源(mysql,hbase,redis等)
(2)、同步:有应答,需要调用内置的drpc服务器才会是同步的
Client--->DRPC--->strom--->DRPC--->client
7、比较:
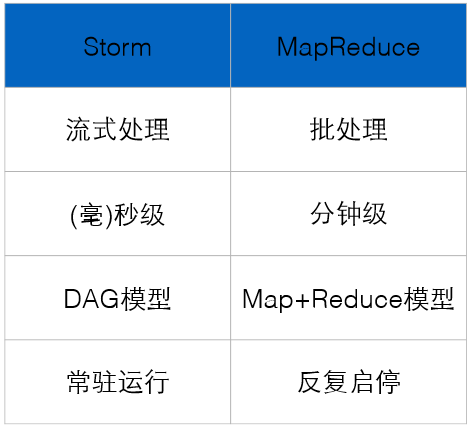
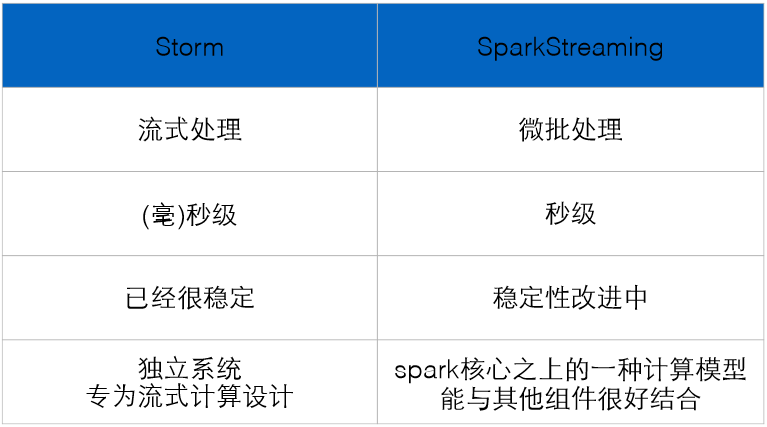
第二节:计算模型
Java写,所以不管是sport还是bolt都是类,业务的处理也就是对类中方法的实现
(1)Spout:继承BaseRichSpout或实现IRichSpout
open: //对象创建
This.conf = conf;
This.context= context;
This.collector= collector;
declare方法:声明定义,即定义要向后发送的是什么数据,declare英文注释:声明
可先通过DeclarerOutputFields中的declare方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector中的emit方法指定数据流Id(streamId)参数将数据发送出去
例子:
DeclarerOutputFields
Declarer.declare(new Fields(“num”));
nextTuple方法:数据拉取,数据推送
Spout中最核心的方法是nextTuple,该方法会被Storm线程不断调用、主动从数据源拉取数据,再通过emit方法将数据生成元组(Tuple)发送给之后的Bolt计算
例子:
nextTuple
i++;
List tuple = new Values(i);
This.collector.emit(tuple);
(2)Bolt:继承BaseRichBolt或实现IRichBolt
prepare: //同上面的open一样创建
declare方法:声明定义,即定义要向后发送的是什么数据
可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector中的emit方法指定数据流Id(streamId)参数将数据发送出去
execute方法:业务处理
Bolt中最核心的方法是execute方法,该方法负责接收到一个元组(Tuple)数据、真正实现核心的业务逻辑
例子:
Excute
Input.get...byField(“num”);
(3)Stream Grouping – 数据流分组(即数据分发策略)将tuple发送给哪个bolt task来处理
1. Shuffle Grouping 随机分发(常用)
随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同。
轮询,平均分配
例子:.shuffleGrouping(“sport1”);
2. Fields Grouping按字段分组(常用)
按字段分组,比如,按"user-id"这个字段来分组,那么具有同样"user-id"的 tuple 会被分到相同的Bolt里的一个task, 而不同的"user-id"则可能会被分配到不同的task。
例子:.fieldsGrouping(“sport1”,new Fields(“w”));
3. All Grouping所有的节点都获取到全量的(不用)
广播发送,对于每一个tuple,所有的bolts都会收到
4. Global Grouping(不用)
全局分组,把tuple分配给task id最低的task 。
5. None Grouping(同shuffle grouping,不用)
不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shuffle grouping是一样的效果。 有一点不同的是storm会把使用none grouping的这个bolt
放到这个bolt的订阅者同一个线程里面去执行(未来Storm如果可能的话会这样设计)。
6. Direct Grouping(指定哪个接收,首先声明Direct Stream指向流,emitDirect用这种的方式发送)
指向型分组, 这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为 Direct Stream
的消息流可以声明这种分组方法。而且这种消息tuple必须使用 emitDirect 方法来发射。消息处理者可以通过 TopologyContext 来获取处理它的消息的task
的id (OutputCollector.emit方法也会返回task的id)
7. Local or shuffle grouping(限制在一个工作进程中的随机分发,不用)
本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发送给这些同进程中的tasks。否则,和普通的Shuffle Grouping行为一致
8. customGrouping(不用)
自定义,相当于mapreduce那里自己去实现一个partition一样。
(4)构建拓扑及提交
Main
topologyBuilder tb = new topologyBuilder();
Tb.setSport(“sport1”,new Sport1());
Tb.setBolt(“bolt1”,new Bolt1(),2).shuffleGrouping(“sport1”); //这里的2是并行度,可以不设;shuffleGrouping是分发策略。
If(args.length > 0){ //集群形式运行
StormSubmitTopology.submitTopology(args[0],new conf(), tb.creatTopology());
}else{ //本地形式运行
localCluster lc = new localCluster();
Lc.submitTopology(“wc”, new conf(), tb.creatTopology());
}
第三节:架构设计
对比:
|
|
Hadoop |
Storm |
|
主节点 |
ResourceManager |
Nimbus |
|
从节点 |
NodeManager |
Supervisor |
|
应用程序 |
Job |
Topology |
|
工作进程 |
Child |
Worker |
|
计算模型 |
Map/Reduce(split,map,shuffle,reduce) |
Spout/Bolt |
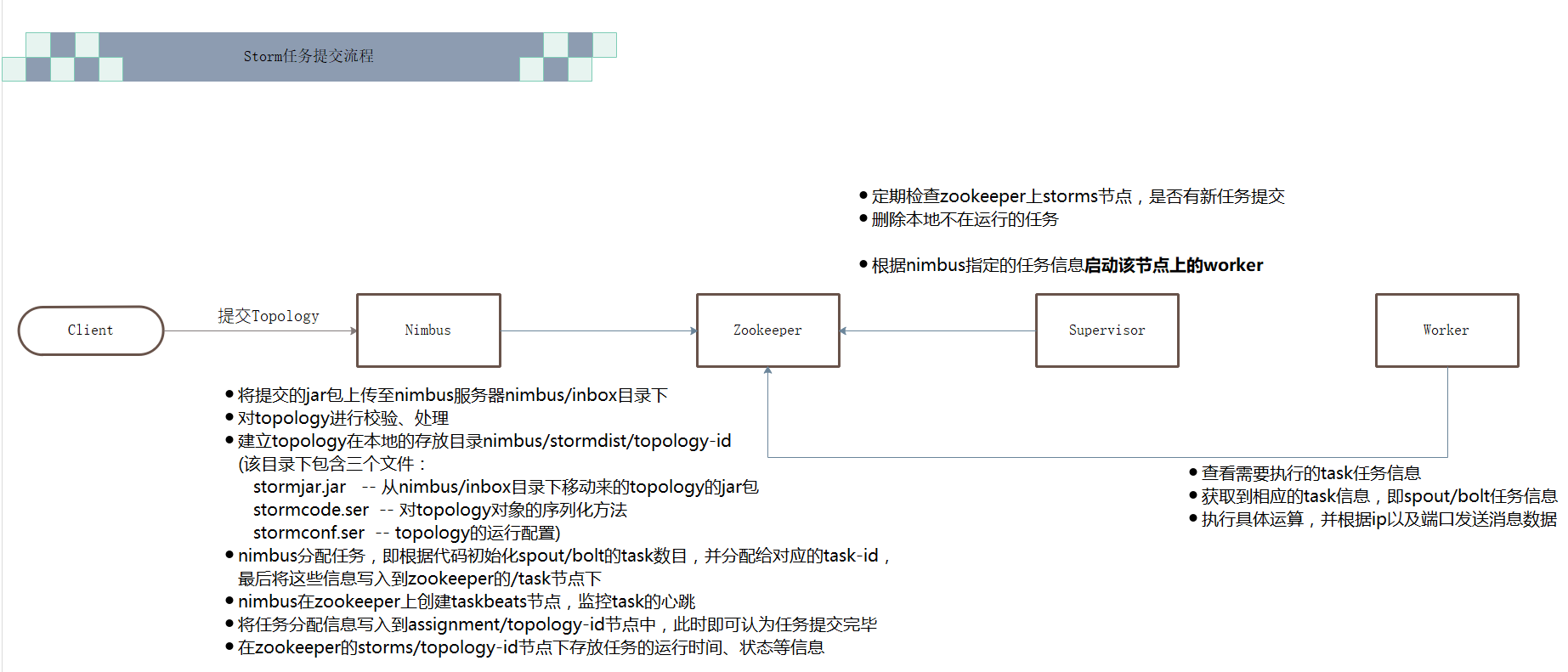
任务提交流程:
第四节:环境部署
1、在storm目录中创建logs目录,出现问题时候存放日志
mkdir logs
2、解压
通讯端口是8080
3、修改配置文件 https://blog.csdn.net/l1028386804/article/details/51924272
storm.yaml
storm.zookeeper.servers:
- "node1"
- "node2"
- "node3"
storm.local.dir: "/tmp/storm"
nimbus.host: “node1"
supervisor.slots.ports: //supervisor上运行workers的端口列表.每个worker占用一个端口,且每个端口只运行一个worker.通过这项配 - 6700 置可以调整每台机器上运行的worker数.(调整slot数/每机)
- 6701
- 6702
- 6703
4、查看帮助信息
./storm help
5、启动Zookeeper
./bin/storm dev-zookeeper >> ./logs/zk.out 2>&1 &
6、在node1上启动Nimbus,UI
./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
./bin/storm ui >> ./logs/ui.out 2>&1 &
7、在node2、node3上启动Supervisor(按照配置每个Supervisor上启动4个slots)
./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
8、启动Logviewer(可以在浏览器上查看日志)
./bin/storm logviewer &
9、提交jar包到集群:
strom help jar(查看如何提交jar到storm集群)
第五节:数据处理方式
1、同步计算(DRPC):实现一个demo
集群:
修改配置文件conf/storm.yaml
drpc.servers:
- "node1”
启动:
启动 drpc
storm drpc >> ./logs/drpc.out 2>&1 &
代码:
1、自动方式:不建议使用,比较死板
LinearDRPCTopologyBuilder
2、手动方式:

2、并发机制:
Worker – 进程
一个Topology拓扑会包含一个或多个Worker(每个Worker进程只能从属于一个特定的Topology)
这些Worker进程会并行跑在集群中不同的服务器上,即一个Topology拓扑其实是由并行运行在Storm集群中多台服务器上的进程所组成
Executor – 线程
Executor是由Worker进程中生成的一个线程
每个Worker进程中会运行拓扑当中的一个或多个Executor线程
一个Executor线程中可以执行一个或多个Task任务(默认每个Executor只执行一个Task任务),但是这些Task任务都是对应着同一个组件(Spout、Bolt)。
Task
实际执行数据处理的最小单元
每个task即为一个Spout或者一个Bolt
注意:
Task数量在整个Topology生命周期中保持不变,Executor数量可以变化或手动调整
(默认情况下,Task数量和Executor是相同的,即每个Executor线程中默认运行一个Task任务)
代码中设置数量:
设置Worker进程数
Config.setNumWorkers(int workers)
设置Executor线程数
TopologyBuilder.setSpout(String id, IRichSpout spout, Number parallelism_hint)
TopologyBuilder.setBolt(String id, IRichBolt bolt, Number parallelism_hint)
设置Task数量
ComponentConfigurationDeclarer.setNumTasks(Number val)
例:
Config conf = new Config() ;
conf.setNumWorkers(2);
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("spout", new MySpout(), 1);
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout);
调整worker与excutor的数量:
Rebalance:命令行动态调整,可以多设置task,以后再发生扩充的时候,就可以直接调整worker与excutor数量来实现迁移
第六节:Flume+kafka+strom
(1)Kafka(Kafka的优势)
简介:
1、角色:
Producers ---topic----consumers
在一个分区中的生产与消费是有序的
2、搭建集群的节点:
Broker //编号
3、如何保证消费的有序性:
消费的偏移量
4、优势
高吞吐量:零拷贝,Netty的网络传输。
数据默认保存7天。
offset会更新到一个kafka自带的topic【__consumer_offsets】
安装:
解压:
Tar gz -C 目录
配置:
config/server.properties:
Broker.id
Log.dirs=真实数据存储路径
Zookeeper.connect=node01:2181,node02:2181
启动:
bin/kafka-server-start.sh config/server.properties //启动kafka,且指定要读取哪个配置文件
测试:
查看帮助手册:
bin/kafka-console-consumer.sh help
查看topic列表:
bin/kafka-topics.sh --zookeeper node06:2181,node07:2181,node08:2181 --list
查看“test”topic描述:
bin/kafka-topics.sh --zookeeper node06:2181,node07:2181,node08:2181 --describe --topic test
Topic创建
bin/kafka-topics.sh --zookeeper node06:2181,node07:2181,node08:2181 --create --replication-factor 2 --partitions 3 --topic test
(参数说明:
--replication-factor:副本个数,默认1个
--partitions:指定当前创建的topic分区数量,默认1个(向几个分区中分发数据,此时一个分区有序,整体无序)
--topic:指定新建topic的名称
)
Producer创建(往主题中生产数据)
bin/kafka-console-producer.sh --broker-list node06:9092,node07:9092,node08:9092 --topic test
Consumer创建(消费某主题的数据)
bin/kafka-console-consumer.sh --zookeeper node06:2181,node07:2181,node08:2181 --from-beginning --topic test
(参数说明:
--from-beginning 从头消费
)
(2)strom兼容kafka
kafkaSpout 消费kafka数据

kafkaBolt 生产kafka数据


(3)Flume兼容kafka
1、flume安装
(1)解压
(2)配置flume-env.sh
配置Java的环境变量位置
(3)在conf/下 创建配置文件fk.conf
#取别名
a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = avro //客户端连接source源的协议 a1.sources.r1.bind = node06 //flume所在节点(如果是集群呢???????????????) a1.sources.r1.port = 41414 //与flume连接的端口 # Describe the sink 对输出源的规定 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink //往哪里推送 a1.sinks.k1.topic = testflume //主题 a1.sinks.k1.brokerList = node06:9092,node07:9092,node08:9092 a1.sinks.k1.requiredAcks = 1 //数据完整保障机制,1:主节点告诉消息已传递即可,0:只管推送,-1:所有的都反馈 a1.sinks.k1.batchSize = 20 a1.sinks.k1.channel = c1 # Use a channel which buffers events in memory 内存区设定 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000000 a1.channels.c1.transactionCapacity = 10000 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
(4)启动flume
bin/flume-ng agent -n a1 -c conf -f conf/fk.conf -Dflume.root.logger=DEBUG,console
//agent是代理
//Dflume.root.logger=DEBUG,console 日志输出格式,控制台打印debug日志
第七节:容错机制
1、容错机制(消息的完整性:速度降低了,完整度提高):
(1) 怎么判断消息是否完整传递:
传递数据的同时,带有16位二进制的ID,数据传递到下一个点时候,将新的ID进行xor运算,如果是全0,则说明数据正常传递。
如果有问题,则通知spout重新发送。
(2) Ack
保证数据至少一次发送,但是不保证会重复。
2、事务:
要解决的问题:
事务解决让数据有且仅有一次被处理。
Transcation:
tuple传递时候带着transcationID,且这个ID是线性增长,数据的处理也是强有序性的。
将tuple存入库时,那么可根据ID判断,如果有这个ID的数据了,那么就是代表数据被处理过了,就不做处理了。
弊端:每次的tuple频繁的与数据库交互。所以衍生出:
Design2:
现在是多个tuple组成batch,这个批里面带着一个transcationID,以批处理形式,进行数据传递与数据库交互。
弊端:一个batch在运行时候,其他的是在阻塞状态,不仅影响速度,还有资源浪费。
Design3:
在前面的bolt阶段,所有的batch是自由竞争阶段,但是在要入库时候还是要保持强有序性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号