
大数据-hbase理论
前言:随着数据量的不断增大,传统数据库的存储查询出现瓶颈,比如mysql采用分库分表的形式。
一:简介
1. 概念:分布式的列式数据库。
2. 基本概念:
2.1 RowKey:一行数据的唯一标识(主键)。
2.2 Column Family(列族):在定义表时候就定义完成,代表一个文件夹下的数据(可以认为是一个表,其实这个是不准确的,只是单纯的为了理解)。
2.3 Qualifier(列):列族下的数据单元(可以认为是表中的字段)。
2.4 Timestamp(时间戳):记录一列数据的版本号(可以认为是表中数据的行号)。
2.5 Cell(单元格):存储数据的最小单元,即我要获取的一个时间戳下的一组数据。
比如:有字段数据nage,age。会有很多的数据存在。我要获取某一个时间戳下的name和age数据,那么获取出来的这个就是 cell。
2.6 HLog:记录着操作信息,可以用来恢复数据。
3. 结构
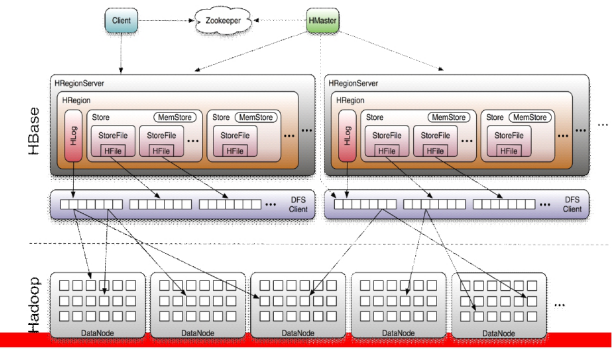
3.1 图解注释
3.1.1 zk:
保证任何时候,集群中只有一个master。
实时监控Region server的上线和下线信息,并实时通知Master。
存贮所有Region的寻址入口。
存储HBase的schema和table元数据。
3.1.2 HMaster:(管理regionServer)
为RegionServer分配region
发现失效的RegionServer并重新分配其上的region
负责RegionServer的负载均衡
管理用户对table的增删改操作
3.1.2 RegionServer:(HBase集群的一个节点)
RegionServer维护region,处理对这些region的IO请求
RegionServer负责切分在运行过程中变得过大的region
3.1.2 Region:(里面有store,hlog)
HBase自动把表水平划分成多个区域(region),每个region会保存一个表里面某段连续的数据。
裂变:每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region;
当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个Regionserver 上。
(开始就一个region,后来裂变之后变成多个,被分配到不同的Regionserver上)。
3.1.2 Store:(里面有memStore,storeFile)对应着列族,存数据的地方
一个region由多个store组成,一个store对应一个CF(列族)
包括下面两种:
MemStore(位于内存)一个store中有一个
StoreFile(位于磁盘)一个store中有0个或多个
数据的存储,合并,裂变过程:
写操作先写入memstore,当memstore中的数据达到某个阈值,regionserver会启动flashcache进程写 入 storefile,每次写入形成单独的一个storefile
当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、major compaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile
当一个region所有storefile的大小和数量超过一定阈值后,会把当前的region分割为两个,并由master分配到相应的regionserver服务器,实现负载均衡
客户端数据的检索过程:
先在memstore找,找不到再找storefile
3.1.2 HFile(存储在hdfs中)
StoreFile文件的存储形式
3.1.2 HLog
hbase的表信息
3.2:读取流程
写:
Client ---> zookeeper
Client ---> regionServer ---> Hlog(先写日志) ---> store ---> Memstore ---> storeFile ---> HFile(这里HFile是因为把文件存在hdfs,可以存在别处)
读:
Client --->zookeeper
Client --->regionServer ---> store ---> memStore(如果这个里面没有,说明数据已经溢写)---> blockCache(读缓存块)---> storeFile
二:集群搭建
(1) :前提:
1、同步系统时间:ntpdate : yum install -y ntpdate ntpdate ntp1.aliyun.com
2、相互免秘钥(rsa免秘钥形式)
ssh keyqen
ssh-copy-id -i .ssh/id_rsa_pub node01
3、Hadoop集群正常运行(把数据存储在HDFS)
4、ZooKeeper集群正常运行
5、zookeeper与HBase不能在一个节点,会有2181端口冲突
以下都是在conf目录下
(2):配置RegionServers(最好跟datanode在一个节点,存储在hdfs的数据在一个节点减少网络IO)
node02
node03
node04
(3):配置backup-masters(备机节点)
node03
(4):配置hbase-env.sh
配置JAVA_HOME
配置HBASE_MANAGERS_ZK=false //hbase是否管理自己的zk
(5):添加hdfs-site.xml到conf目录下(要把数据存储在HDFS,需要告知集群hadoop集群在哪)
(6):配置hbase-site.xml
<property>
<name>hbase.rootdir</name>
<value>hdfs://hdfs的集群名称(mycluster)/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node-a.example.com,node-b.example.com,node-c.example.com</value>
</property>
(7) :启动Hbase
start-hbase.sh
(8):Web访问Hbase:端口是60010
三:优化
(1) 表优化
1. 预分区
1.1 概念:通常情况下建表时候会创建一个region,这个region的rowkey是没有startkey和endkey,当数据量增大达到阈值会进行切分。
1.2 存在的问题:
split会消耗I/O资源,且rowkey无边界。
热点写:split之后的region,再写入数据,会将数据写入切割之后startkey的region。
1.3 实现:预分区是在创建表时候先创建多个region,并且指定region的rowkey的startkey与endkey,当数据量增大时候会根据规则进入不同region,实现数据的负载均衡。
private static byte[][] getSplitKeys() { String[] keys = new String[] { "10|", "20|", "30|", "40|", "50|", "60|", "70|", "80|", "90|" }; //分割点|的ascll是124,~的是126很大,所以加了| byte[][] splitKeys = new byte[keys.length][]; TreeSet<byte[]> rows = new TreeSet<byte[]>(Bytes.BYTES_COMPARATOR); //升序排序 for (int i = 0; i < keys.length; i++) { rows.add(Bytes.toBytes(keys[i])); //转字节数组并排序 } Iterator<byte[]> rowKeyIter = rows.iterator(); int i=0; while (rowKeyIter.hasNext()) { byte[] tempRow = rowKeyIter.next(); rowKeyIter.remove(); splitKeys[i] = tempRow; i++; } return splitKeys; } //创建预分区表 admin.createTable(tableDesc ,splitKeys); //数据插入 byte[] rowkey = Bytes.toBytes("随机数"+rowkey); Put put = new Put(rowkey);
2. Rowkey设计(最大长度64kb)
row key是按照字典序存储,因此,设计row key时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块
3. 列族:列族不超过2~3个
4. 数据缓存:HColumnDescriptor.setInMemory(true)
应用:缓存级别顺序(single,multi,in-memory)这个较高,所以应用在被经常访问的。
5. 最大版本数:HColumnDescriptor.setMaxVersions(int maxVersions)
例子:如果只需要保存最新版本的数据,那么可以设置setMaxVersions(1)
6. 生命周期:HColumnDescriptor.setTimeToLive(int timeToLive)
设置表的生命周期,过来周期数据自动删除。
例子:保存两天的数据setTimeToLive(2 * 24 * 60 * 60)
7. 合并与切割
Memstore(大小64mb) ---flush---> 磁盘,形成storefile,此时在zk中记录redo point,进行小范围合并,即minor compact;
满足一定条件时候,将磁盘中的所有storefile进行何必,即major compact;
Storefile达到一定阈值将会对等切割,放在不同的regionServer上,即split;
1、major compact条件及优化策略:
触发条件:major_compact 命令、majorCompact() API、region server自动运行;
自动运行的条件:
hbase.hregion.majoucompaction 默认为24 小时
hbase.hregion.majorcompaction.jetter 默认值为0.2 防止region server 在同一时间进行合并
hbase.hregion.majorcompaction.jetter参数的作用是:对参数hbase.hregion.majoucompaction 规定的值起到浮动的作用,假如两个参数都为默认值24和0,2,
那么major compact最终使用的数值为:19.2~28.8 这个范围。
优化:
关闭自动major compaction:
hbase.hregion.majoucompaction=0
手动编程major compaction:
http://hbasefly.com/2016/07/13/hbase-compaction-1/
2、minor compact条件及优化策略:
触发条件:
hbase.hstore.compaction.min
默认值为 3,表示至少需要三个满足条件的store file时,minor compaction才会启动
hbase.hstore.compaction.max
默认值为10,表示一次minor compaction中最多选取10个store file
hbase.hstore.compaction.min.size
表示文件大小小于该值的store file 一定会加入到minor compaction的store file中
hbase.hstore.compaction.max.size
表示文件大小大于该值的store file 一定会被minor compaction排除
hbase.hstore.compaction.ratio
将store file 按照文件年龄排序(older to younger),minor compaction总是从older store file开始选择
(2) 写表
1. 多表并发写:同时对多个表进行写操作
2. 参数设置
2.1 Auto flush(默认客户端来一条数据就put一下,设置之后在put满客户端缓存时候才发送请求。)
HTable.setAutoFlush(false)
2.2 Write buffer(设置客户端缓存大小)
HTable.setWriteBufferSize(writeBufferSize)
2.3 WAL log(对不重要的数据可进行关闭写日志。如果机器宕机,则无法恢复数据。)
Put.setWriteToWAL(false)或Delete.setWriteToWAL(false)
3. 批量写(减少IO)
HTable.put(List<Put>)
4. 多线程
慎用
(3) 读表
1. 多表并发读
同时对多个表进行读操作
2. 参数设置
2.1 Scanner cache
hbase.client.scanner.caching
从服务端抓取的数据条数,默认一次一条。设置合理的值,则会减少scan的next()时间。但是需要客户端的内存维持这些cache的数据。
配置方式(三者的优先级越来越高):
1、Conf配置中;
2、HTable.setScannerCaching(int scannerCaching);
3、Scan.setCaching(int caching);
2.2 Scan attribute selection
scan时指定过滤条件: 指定列族;指定范围;
2.3 Close resultScanner
用完之后关闭ResultScanner
3. 批量读
HTable.get(List<Get>)
4. 多线程
慎用
5. 缓存查询结果
6. blockCache
有两种缓存一个是写缓存memstore,一个是读缓存blockcache。
一个regionserver上有一个blockcache和N个memstore,他们的大小和不能大于等于heapsize*0.8,
Blockcache大小默认是0.2,memstore是0.4,所以可以设置blockcache大一些,加大缓存的命中率。
例如:
Blockcache=0.4
memstore=0.39
(4) 比较HTable与HTablePool
使用HTable的注意事项:
1、htable对象在构造时候就创建
2、非线程安全
在多线程情况下,不同的线程不要使用同一个HTable对象
3、HTable之间应共享conf
使用HTablePool形式
Configuration conf = HBaseConfiguration.create();
HTablePool pool = new HTablePool(conf, 10);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号