
java-filebeat+elk的数据传输
概述:本章进行filebeat --> kafka --> logstash --> es的数据传输过程,及kibana对es数据的显示控制。
1:搭建filebeat读取日志文件信息,写入kafka。(版本与es一致)
1.1:配置文件
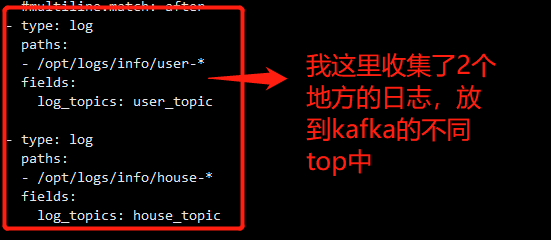

1.2:启动
./filebeat -e -c filebeat.yml
后台启动:nohup ./filebeat -e -c filebeat.yml &
2:logstash读取kafka信息,解析数据,写入es集群。(版本与es一致)
2.1:配置(将logstash.conf文件 cp 改名为logs.conf,名称自定义)
主要分3个部分:
1.读取kafka数据。
2.解析数据,我的数据是按照规则写入的,所以免去了正则匹配之类的处理,我这里写的主要是怎么存储我的经纬度数据的测验。
3.将解析好的数据存入es集群,我写的案例是读取的不同的数据根据type不同存入es不同的index中。
注意:es的index中可以存多个type,但是最好一个index对应一个type。总之一切的设计都为最快效率工作。
以下配置仅供参考:
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
#output {
# elasticsearch {
# hosts => ["http://localhost:9200"]
# index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
# }
#}
input {
kafka {
bootstrap_servers => "node01:9092,node02:9092,node03:9092"
topics => ["house_topic"]
group_id => "group-house"
codec => "json"
# consumer_threads => 1
decorate_events => true
type => "house"
}
kafka {
bootstrap_servers => ["node01:9092,node02:9092,node03:9092"]
topics => ["user_topic"]
group_id => "group-user"
codec => "json"
# consumer_threads => 1
type => "user"
decorate_events => true
}
}
filter {
json {
#// 以JSON格式解析
source => "message"
#解析到doc下面
# target => "doc"
#移除message
remove_field =>["message"]
}
mutate {
convert => {"lon" => "float"}
convert => {"lat" => "float"}
}
mutate {
rename => {
"lon" => "[location][lon]"
"lat" => "[location][lat]"
}
}
}
#output {
# elasticsearch {
# hosts => ["node01:9200","node02:9200","node03:9200"]
# index => "user"
# }
#}
output{
stdout{
codec=>json
}
if[type] == "user"{
elasticsearch {
hosts => ["node01:9200","node02:9200","node03:9200"]
index => "user"
document_type => "user-info"
}
}
if[type] == "house"{
elasticsearch {
hosts => ["node01:9200","node02:9200","node03:9200"]
index => "house"
document_type => "house-info"
}
}
}
2.2:启动
后台启动:nohup bin/logstash -f config/logs.conf &
3:配置kibana,查询es集群中的数据信息。(版本与es一致)
3.1:配置
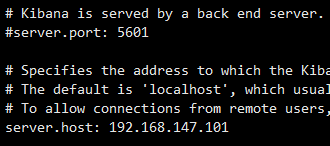

3.2:启动
后台启动:nohup /bin/kibana &
3.3:浏览器展示,访问 http://192.168.147.101:5601/ 可以看到es集群的情况及数据
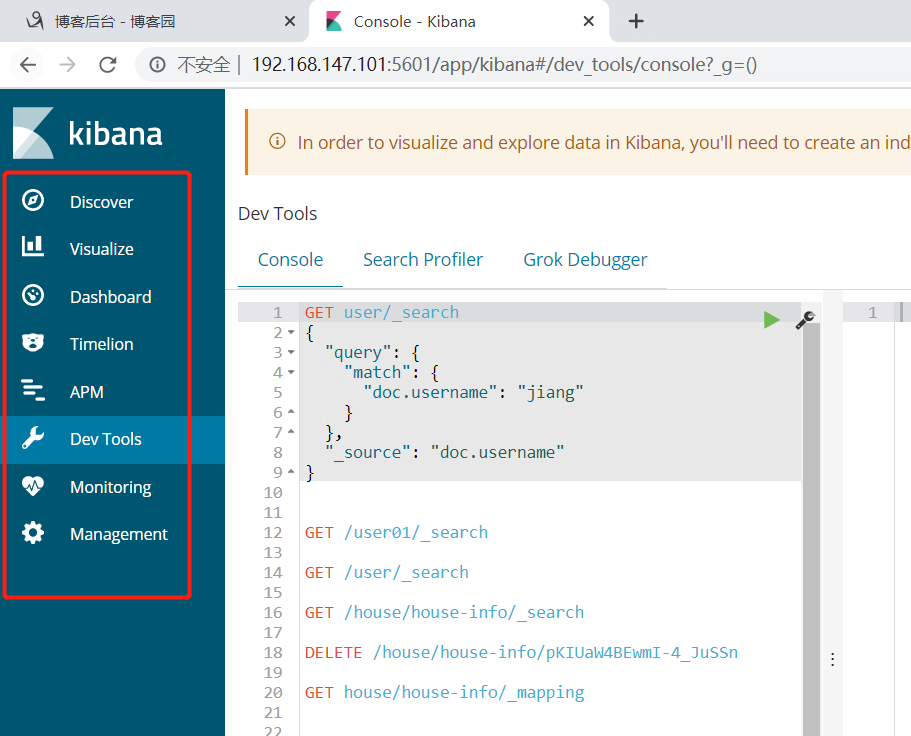
4:心得。
还是需要自己具体实现,多思考发现及解决问题。且做好笔记,当时实现时候其实还是比较曲折的,有不少的疑惑然后找解决办法,可惜过了一段时间了,回顾之前的笔记已经不是很详细了。
所以想起写博客园。
比如我需要什么样的数据好解析,java存储的就是直接的数据还是json的形式,如果不同的情况logstash要怎么解析。
再比如,整体的搭建我们要如何调试,怎么确定日志数据filebeat已经收集并写入kafka了?logstash读取并解析出来的就是我们想要的数据?不同的类型数据是否写入了es?
写入es的数据我们要先建立索引还是在logstash中做处理?等等......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号