
源码分析 | ClickHouse和他的朋友们(5)存储引擎技术进化与MergeTree
本文首发于 2020-06-22 21:55:10
《ClickHouse和他的朋友们》系列文章转载自圈内好友 BohuTANG 的博客,原文链接:
https://bohutang.me/2020/06/20/clickhouse-and-friends-merge-tree-algo/
以下为正文。
21 世纪的第二个 10 年,虎哥已经在存储引擎一线奋战近 10 年,由于强大的兴趣驱动,这么多年来几乎不放过 arXiv 上与存储相关的每一篇 paper。
尤其是看到带有 draft 的 paper 时,有一种乞丐听到“叮当”响时的愉悦。
看paper这玩意就像鉴宝,多数是“赝品”,需要你有“鉴真”的本领,否则今天是张三的算法超越xx,明儿又是王二的硬件提升了yy,让你永远跟不上节奏zz,湮灭在这些没有营养的技术垃圾中,浪费大好青春。
言归正传,接下来的3篇,跟 ClickHouse 的 MergeTree 引擎有关:
上篇介绍存储引擎的技术演进史,从”远古”的 B-tree 出发推演到目前主流的技术架构。
中篇会从存储结构介绍 MergeTree 原理 ,对 ClickHouse MergeTree 有一个深入的认识,如何合理设计来进行科学加速。
下篇会从MergeTree代码出发,看看 ClickHouse MergeTree 如何实现读、写。
本文为上篇,先来个热身,相信本篇大部分内容对大家来说都比较陌生,很少人写过。
地位
存储引擎(事务型)在一个数据库(DBMS)中的地位如何呢?
MySQL 的商业成功可以说大部分来自于 InnoDB 引擎,Oracle 收购 InnoDB 比 MySQL 早好几年呢!
20年前,能亲手撸一套 ARIES (Algorithms for Recovery and Isolation Exploiting Semantics) 规范引擎,实力还是相当震撼的,相信 Oracle 收购的不仅是 InnoDB 这个引擎,更重要的是人, InnoDB 作者在哪里,在干什么?!
Fork 出来的 MariaDB 这么多年一直找不到自己的灵魂,在 Server 层磨磨蹭蹭可谓是江河日下,只能四处收购碰碰运气,当年 TokuDB 战斗过的 commit 依在,但这些已经是历史了。
另,WiredTiger 被 MongoDB 收购并使用,对整个生态所起的作用也是无可估量的,这些发动机引擎对于一辆汽车是非常重要的。
有人问道,都已经 2020 年了,开发一个存储引擎还这么难吗?不难,但是造出来的未必有 RocksDB 好用?!
如大家所见,很多的分布式存储引擎都是基于 RocksDB 研发,可谓短期内还算明智的选择。
从工程角度来看,一个 ACID 引擎要打磨的东西非常之多,到处充斥着人力、钱力、耐心的消耗,一种可能是写到一半就停滞了(如 nessDB),还有一种可能是写着写着发现跟xx很像,沃茨法克。
当然,这里并不是鼓励大家都去基于 RocksDB 去构建自己的产品,而是要根据自己的情况去做选择。
B-tree
首先要尊称一声大爷,这个大爷年方 50,目前支撑着数据库产业的半壁江山。
50 年来不变而且人们还没有改变它的意向,这个大爷厉害的很!
鉴定一个算法的优劣,有一个学派叫 IO复杂度分析,简单推演真假便知。
下面就用此法分析下 B-tree(traditional b-tree) 的 IO 复杂度,对读、写 IO 一目了然,真正明白读为什么快,写为什么慢,如何优化。
为了可以愉快的阅读,本文不会做任何公式推导,复杂度分析怎么可能没有公式呢!
读IO分析
这里有一个 3-level 的 B-tree,每个方块代表一个 page,数字代表 page ID。
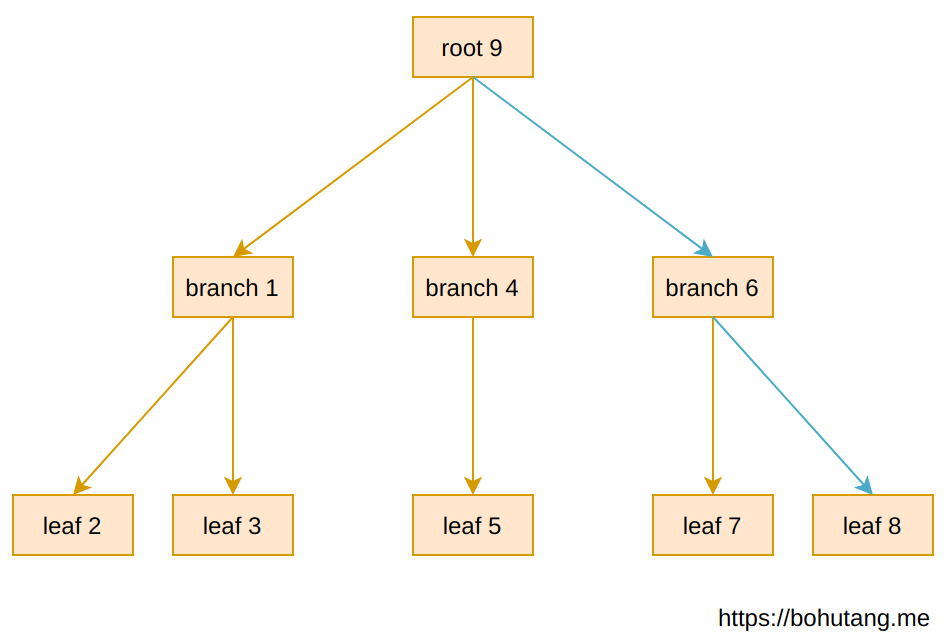
上图 B-tree 结构是内存的一个表现形式,如果我们要读取的记录在 leaf-8上,read-path 如蓝色箭头所示:
root-9 –> branch-6 –> leaf-8
下图是 B-tree 在磁盘上的存储形式,meta page 是起点:

这样读取的随机 IO (假设内存里没有 page 缓存且 page 存储是随机的)总数就是(蓝色箭头):
1(meta-10)IO + 1(root-9)IO + 1(branch-6)IO + 1(leaf-8)IO = 4次 IO,这里忽略一直缓存的 meta 和 root,就是 2 次随机 IO。
如果磁盘 seek 是 1ms,读取延迟就是 2ms。
通过推演就会发现,B-tree 是一种读优化(Read-Optimized)的数据结构,无论 LSM-tree 还是 Fractal-tree 等在读上只能比它慢,因为读放大(Read Amplification)问题。
存储引擎算法可谓日新月异,但是大部分都是在跟写优化(Write-Optimized)做斗争,那怕是一个常数项的优化那就是突破,自从 Fractal-tree 突破后再无来者了!
写IO分析
现在写一条记录到 leaf-8。
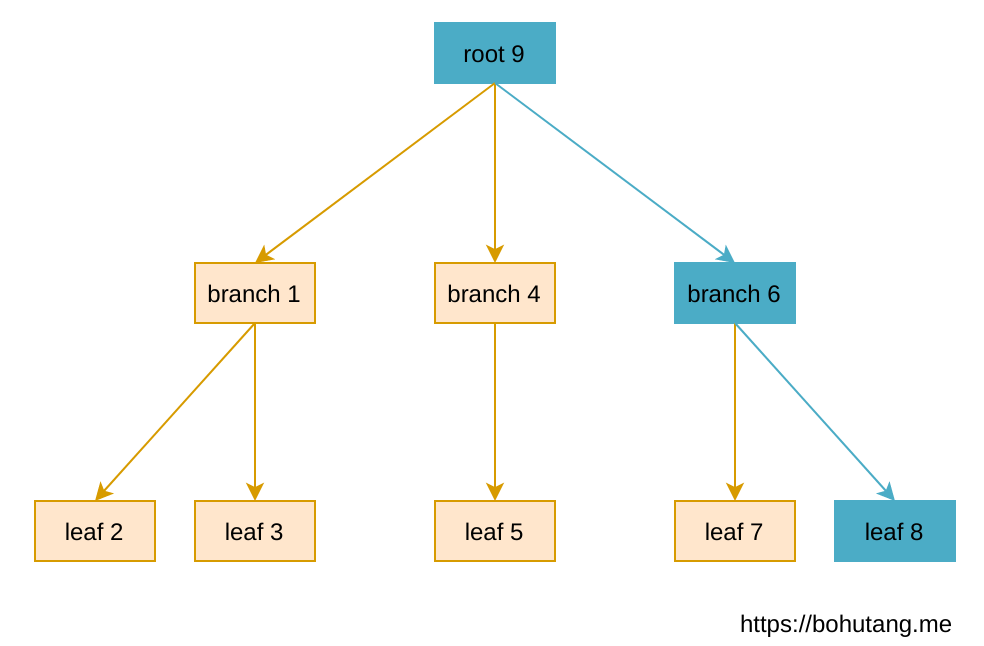
可以发现,每次写都需要先读取一遍,如上图蓝色路径所示。
假设这次写入导致 root, branch 都发生了变化,这种 in-place 的更新反映到磁盘上就是:

基本是 2 次读 IO和写 2 次写 IO+WAL fsync,粗略为 4 次随机 IO。
通过分析发现,B-tree 对写操作不太友好,随机 IO 次数较多,而且 in-place 更新必须增加一个 page 级的 WAL 保证失败回滚,简直是要命。
Write-Optimized B-tree
说到写优化,在机械盘的年代,大家的方向基本是把随机 IO 转换为顺序 IO,充分发挥磁盘的机械优势,于是出现一种 Append-only B-tree:
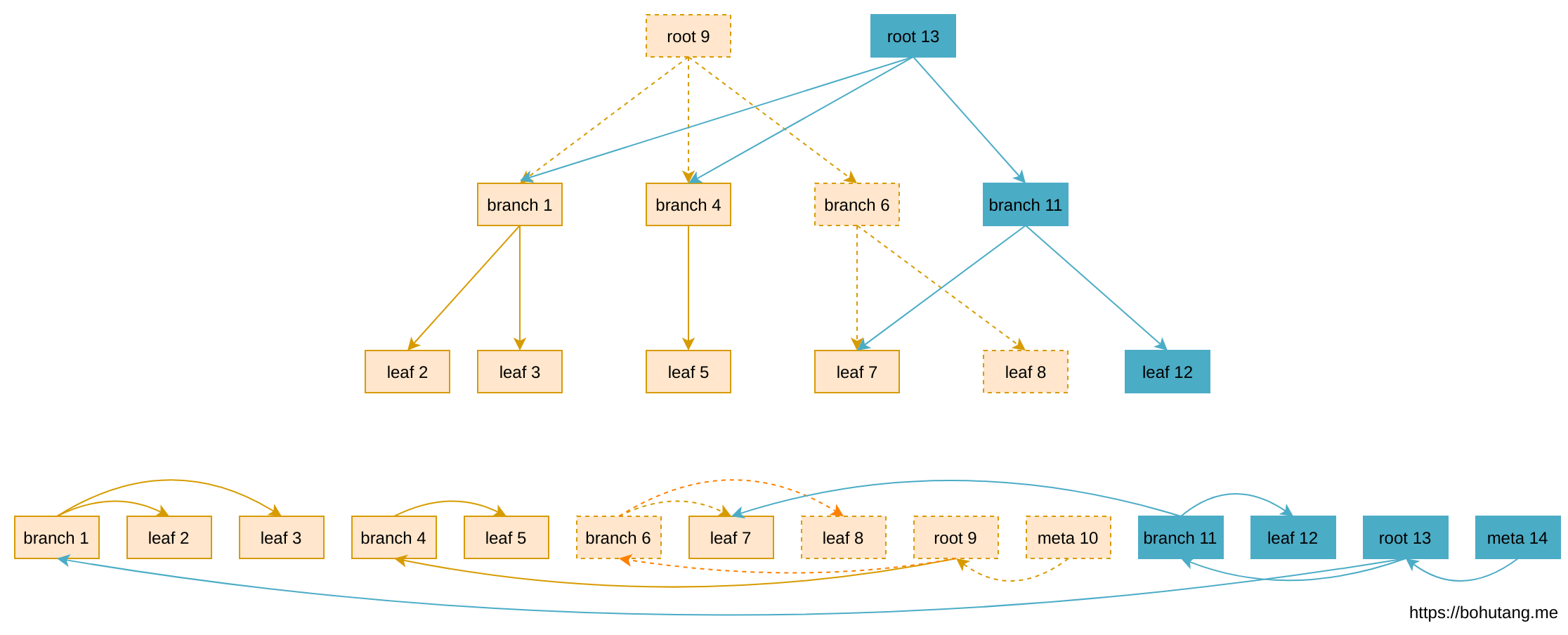
- 更新生成新的 page(蓝色)
- page 回写磁盘时 append only 到文件末尾
- 无需 page WAL,数据不 overwrite,有写放大(Write Amplification)问题,需要做空洞重利用机制
Append-only B-tree 节省了回写时的 2 次随机 IO,转换为常数级(constant)的1次顺序 IO,写性能大幅提升,总结起来就是:
随机变顺序,空间换时间
LSM-tree, Fractal-tree 等写优化算法的核心思想也是这个,只不过其实现机制不同。
LSM-trees
随着 LevelDB 的问世,LSM-tree 逐渐被大家所熟知。
LSM-tree 更像一种思想,模糊了 B-tree 里 tree 的严肃性,通过文件组织成一个更加松散的 tree。
这里不谈一个具体的 LSM-tree 是 Leveled 还是 Size-tiered,只谈大体思想。
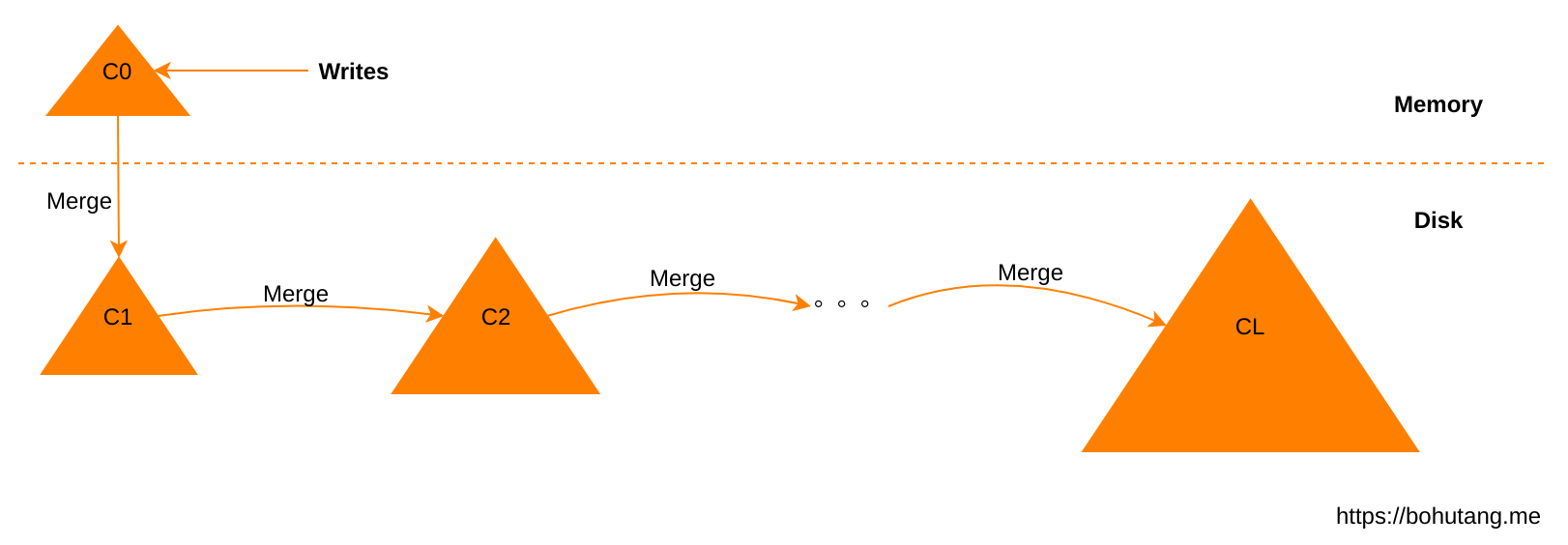
写入
- 先写入内存的 C0
- 后台线程根据规则(Leveled/Sized)进行 merge,C0 –> C1, C1 –> C2 … CL
- 写入 C0 即可返回,IO 放到后台的 Merge 过程
- 每次 Merge 是硬伤,动作大就抖,动作小性能不好,每次 Merge 的数据流向不明确
- 写放大问题
读取
- 读取 C0
- 读取 C1 .. CL
- 合并记录返回
- 读放大问题
Fractal-tree
终于发展到了“终极”优化(目前最先进的索引算法),Fractal-tree。
它是在 Append-only B-tree 的基础上,对每个 branch 节点增加了一个 message buffer 作为缓冲,可以看做是 LSM-tree 和 Append-only B-tree 完美合体。
相对于 LSM-tree 它的优势非常明显:
Merge 更加有序,数据流向非常分明,消除了 Merge 的抖动问题,大家一直寻找的 compaction 防抖方案一直存在的!
这个高科技目前只有 TokuDB 在使用,这个算法可以开篇新介,这里不做累述,感兴趣的可以参考原型实现 nessDB。
Cache-oblivious
这个词对于大部分人都是陌生的,不过别怕。
在存储引擎里,有一个数据结构非常非常重要,它负责 page 数据有序性维护,比如在一个 page 里怎么快速定位到我要的记录。
在 LevelDB 里使用 skiplist,但大部分引擎使用的是一个有序数组来表示,比如 [1, 2, 3, … 100],然后使用二分查找。
大概 10 年前一位内核开发者发表了一篇 <You’re Doing It Wrong>,这个小文讲了一个很有意思的事情:
数据的组织形式对性能有很大的影响,因为 CPU有 cache line。
抛开这篇文章不谈,咱们来看一张“神仙”图:
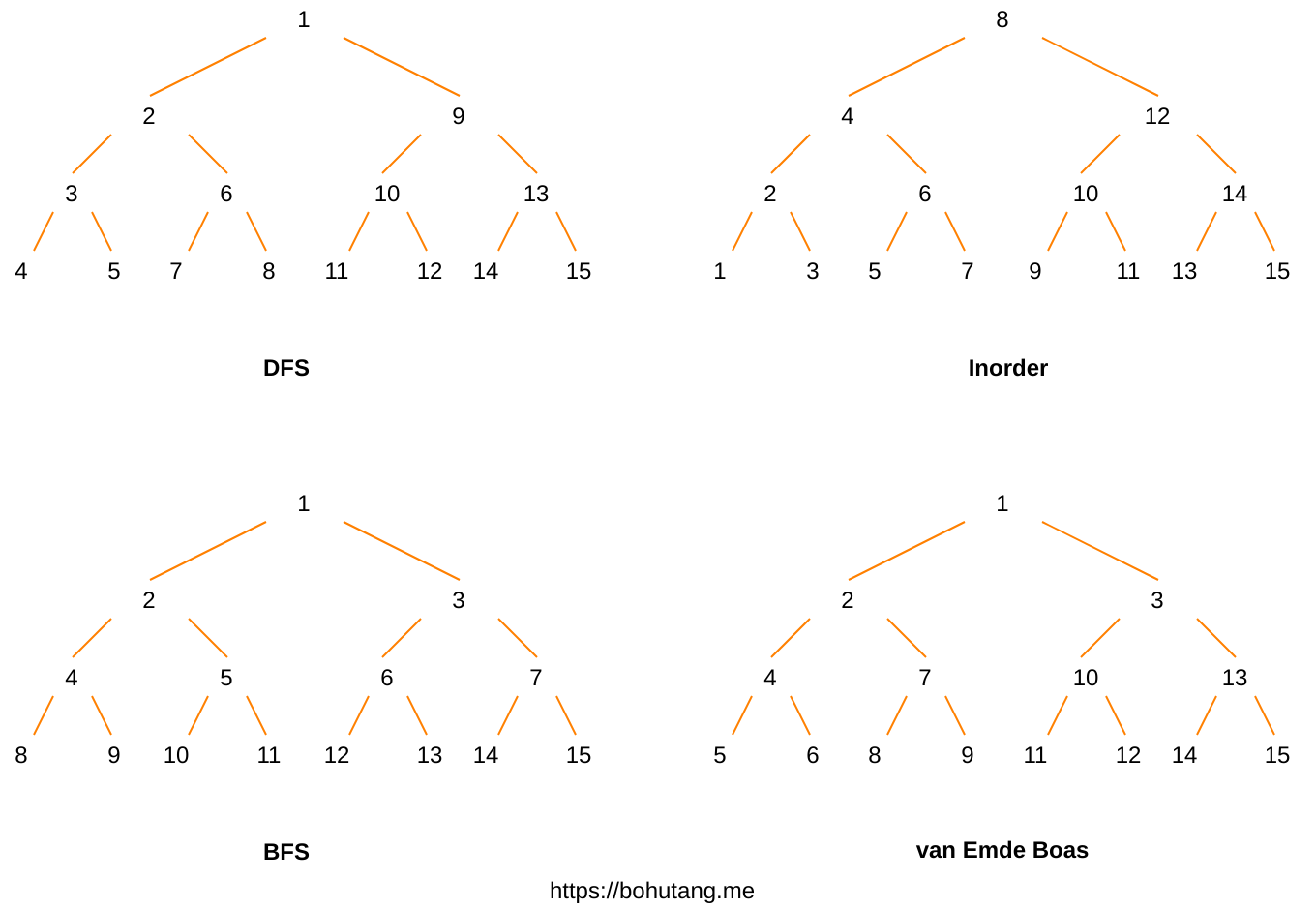
这是一个 binary-tree 的 4 种 layout 表示形式,那么哪种 layout 对 CPU cache line 最友好?
也许你已经猜对了,那就是 van Emde Boas,简称 vEB。
因为它的相邻数据“扎堆”存储,point-query 和 range-query 的 cache line 可以最大化共享,skiplist 对 cache line 是非常不友好的,还可以更快!
对于 cache oblivious 数据结构,这里有一个简单的原型实现: omt
B-tree优化魔力象限
写优化算法从原生的 B-tree 到 Append-only B-tree(代表作 LMDB),又到 LSM-tree(LevelDB/RocksDB 等),最后进化到目前最先进的 Fractal-tree (TokuDB)。
这些算法耗费了很多年才在工程上实现并被认可,研发一款存储引擎缺的不是算法而是“鉴宝”的能力,这个“宝”可能已经躺了几十年了。
其实,”科学家”们已经总结出一个 B-tree 优化魔力象限:
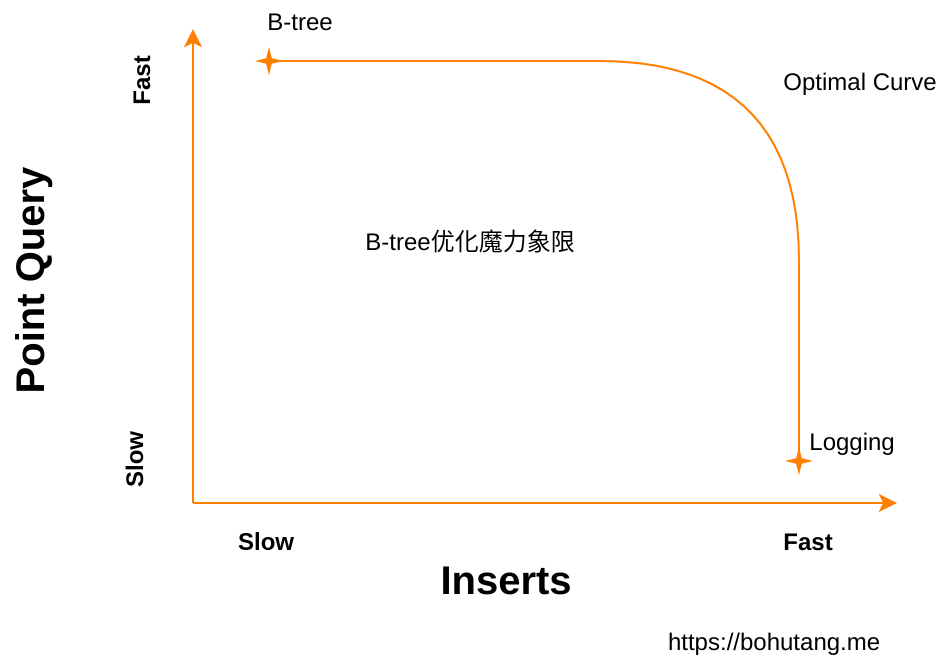
横坐标是写性能,纵坐标是读性能,B-tree 和 Logging 数据结构分布在曲线的两个极端。
B-tree 的读性能非常好,但是写性能差。
Logging 的写性能非常好,但是读性能差(想想我们每次写都把数据追加到文件末尾,是不是很快?但是读…)。
在它们中间有一个优化曲度(Optimal Curve)。
在这个曲度上,你可以通过增加/减少一个常数(1-epsilon)来做读和写优化组合,LSM-tree/Fractal-tree 都在这个曲度之上。

总结
本文主要讨论事务性引擎的技术演进,其中包含了 IO 复杂度分析,其实这个分析是基于一个 DAM(Disk Access Machine) 模型,这里不再展开。
这个模型要解决什么问题呢?
如果工程中涉及硬件层级关系,比如 Disk / Memory / CPU,数据在Disk,读取(以 block 为单位)到 Memory,查找计算(cache-line)在 CPU,不同介质间性能差距又非常之大,我们怎么做才能让整体性能更优的问题。
和当今的硬件相融合,这个模型也一样适用。
最后回到 ClickHouse 的 MergeTree 引擎,它只使用了本文中的部分优化,实现也比较简洁、高效,毕竟没有事务,撸起来也没啥心理负担。
随机变顺序,空间换时间, MergeTree 原理,请听下回分解。
References
[1] Cache-Oblivious Data Structures
[2] Data Structures and Algorithms for Big Databases
[3] The buffer tree: A new technique for optimal I/O-algorithms
[4] how the append-only btree works
[5] 写优化的数据结构(1):AOF和b-tree之间
[6] 写优化的数据结构(2):buffered tree
[7] 存储引擎数据结构优化(1):cpu bound
[8] 存储引擎数据结构优化(2):io bound
[9] nessDB
[10] omt
欢迎关注我的微信公众号【数据库内核】:分享主流开源数据库和存储引擎相关技术。

| 标题 | 网址 |
|---|---|
| GitHub | https://dbkernel.github.io |
| 知乎 | https://www.zhihu.com/people/dbkernel/posts |
| 思否(SegmentFault) | https://segmentfault.com/u/dbkernel |
| 掘金 | https://juejin.im/user/5e9d3ed251882538083fed1f/posts |
| 开源中国(oschina) | https://my.oschina.net/dbkernel |
| 博客园(cnblogs) | https://www.cnblogs.com/dbkernel |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号