MySQL B+ 树索引
MySQL B+ 树索引
InnoDB 中索引为 B+ 树结构
每建立一条索引就创建了一棵 B+ 树
结构
每一个索引页内部都是按顺序排列,并且有页目录(索引页结构 <- 点击查看)
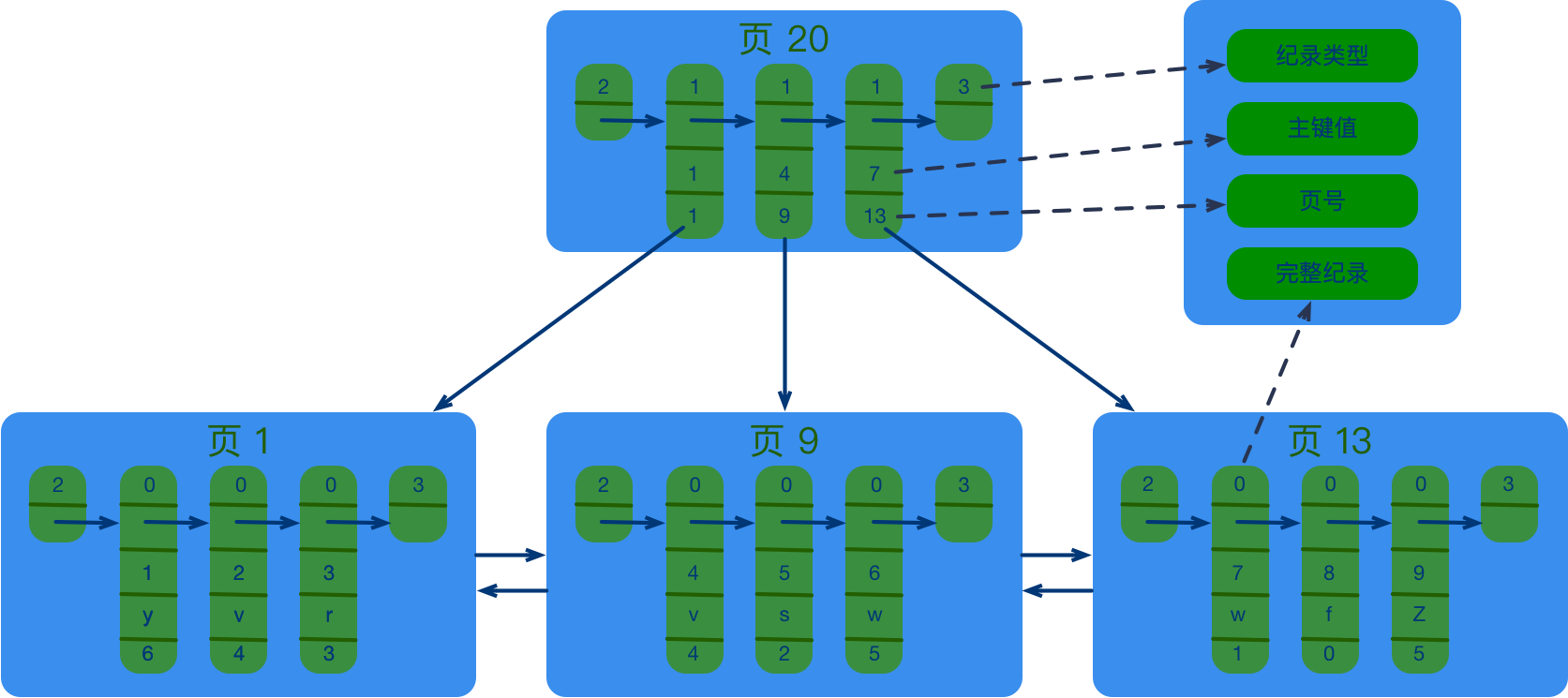
多个索引页之间也是按顺序排列,页之间的目录就储存在目录项纪录中 (纪录的是页中索引最小值)
当存在多个目录项纪录后,又需要高一级的目录项纪录来储存这一层的目录
最后就会形成一棵 B+ 树,查找时以多级目录的形式从上向下依次查找
目录项纪录
目录项纪录相当于目录,只存储了索引和页号,用来快速寻找相应的索引页
结构和用户记录相同,唯一不同的就是存储的信息
记录头信息里的 record_type 属性为 1
用户记录
用户记录存储的信息是用户自己定义的
记录头信息里的 record_type 属性为 0
B+ 树结构:
聚簇索引
聚簇索引是指将数据与索引放到了一起
聚簇索引默认是主键,但是可以通过删除主键之后再恢复更改聚簇索引
一个表只有一个聚簇索引
其他的索引都是建立在聚簇索引之上的二级索引
储存内容
聚簇索引中叶子结点储存的是完整的用户记录
目录项纪录中储存的是页中最小主键主键和页号
二级索引 (secondary index)
聚簇索引只能在通过主键查找时才能发挥作用,如果想通过其他列进行查找就需要以相应列建立索引
除了聚簇索引外其他所有的索引都是二级索引 (辅助索引)
储存内容
二级索引中叶子结点储存的只有建立索引的列和主键
目录项纪录中储存的是建立索引的列、主键和页号
回表
因为二级索引中并不储存完整的用户数据,当通过建立索引的列进行查找时,会找到对应的主键,再通过主键在聚簇索引中查找到完整的数据,这个过程就是回表
没有优化时每获取一条二级索引纪录就要进行一次回表
需要回表的记录越多,使用二级索引的性能就越低
使用回表
如果通过二级索引查找到符合条件的数据过多,查询优化器就偏向于使用全表扫描
如果希望它更偏向于通过二级索引查找,可以通过 LIMIT 限制通过二级索引查找到的数据数量,减少回表操作
避免回表 - 覆盖索引
在查询时只查询二级索引的索引列,这样在二级索引中就能获取需要的信息,而不需要再回表去查找完整数据,这个查询就是索引覆盖查询
因此查询列表时最好不要使用 * ,而是标明查询列
顺序 IO
访问二级索引时,由于数据集中分布在一个或几个数据页中,读取速度较快
随机 IO
访问聚簇索引时,通过二级索引查询到的纪录主键不一定连续,所以数据会比较分散,读取速度比较慢
联合索引
如果以多个列建立索引,这个索引就是联合索引
储存内容
联合索引也是二级索引
联合索引中叶子结点储存的是建立索引的所有列和主键
目录项纪录中储存的是建立索引的所有列、主键和页号
与分别建立索引的区别
分别建立索引就意味着要建立多棵 B+ 树,建立联合索引只需要一棵 B+ 树
分别建立索引可以分别进行查找,但是联合索引查找时列的顺序需要按照建立索引的先后进行查找,否则就用不上索引
使用索引
索引并不是建的越多越好:
因为每建一个索引就相当于建立了一棵 B+ 树,占用空间
每次增删改数据时又会修改索引,降低性能
全值匹配
当搜索条件中的列和索引列一致时,就是全值匹配,全值匹配可以使用到索引
查询优化器
WHERE 语句中列的顺序并不会影响查询的顺序,因为查询优化器会对语句进行优化
匹配左边的列
搜索时可以不包括全部联合索引中的列,只包含左边的也可以
由于建立索引时就是从左边开始建的,排序时左边的优先排序,所以搜索时必须要优先搜索左边的列才能用上索引
匹配列前缀
字符串排序时是从最左边的字符开始进行排序
所以原理和匹配最左边的列相同,只有匹配字符串前缀时才能用到索引
# 可以用到索引
SELECT * FROM person WHERE name LIKE 'A%';
# 无法使用索引
SELECT * FROM person WHERE name LIKE '%a%';
如果需要匹配后缀,可以将字符串倒置
匹配范围值
由于 B+ 树中数据是按顺序储存的,所以匹配范围值比较方便
只有最左边的一列范围查找时才能用到索引
精确匹配某一列并范围匹配另外一列
如果左边的列是精确查找,右边的一列进行范围查找时就可以用到索引
排序
如果排序的列顺序与索引相同,则可以直接获取数据
但是如果顺序不同,不同的部分就无法使用索引,左边相同的部分还是可以使用索引,
不能使用索引的情况
当正序 (ASC) 和倒序 (DESC) 混用时就无法使用索引
WHERE 语句中出现了非索引最左一列,而它左边的列却没有出现
排序的多个列不是来自同一个索引
排序列被修饰
分组
如果分组顺序与索引顺序相同,则可以使用到索引,否则只能在文件中进行
建立索引
用适当的方法建立索引,可以提高性能,节省储存空间
只为用于搜索、排序或分组的列创建索引
只为 WHERE 、ORDER BY 、 GROUP BY 子句中的列建立索引
SELECT 语句中的列没必要建立索引
列的基数
列的基数越大,列的数据越分散;基数越小,数据越集中
数据越分散,在二级索引中查询到的数据就会越少,回表操作就会比较少,性能较好
所以尽量为基数大的列建立索引
索引列的类型尽量小
数据类型越小,查询时的比较越快
数据类型约小,索引占用的储存空间就越少,每页中数据越多,磁盘 IO 对性能的损耗就少
尤其是主键,因为聚簇索引和二级索引中都会储存主键
索引字符串的前缀
建立索引时可以只对字符串的前几个字符进行索引
在字符串类型数据存储数据比较多时,建议通过这个方式建立索引
CREATE INDEX index_name ON table_name(column_name(string_length));
既节约空间,又减少字符串的比较时间
缺点
在排序时,由于无法确认完整的字符串,就无法进行排序,所以只能使用文件排序
索引列在表达式中单独出现
例如索引列为 my_col,进行筛选时:
SELECT my_col WHERE my_col * 2 < 4
SELECT my_col WHERE my_col < 4 / 2
虽然语义相同,但是上面那一条无法使用到索引,因为它不是单独出现的
一表达式或函数调用的方式出现都无法使用索引
主键
当插入纪录的主键大小位于现有纪录主键大小之间时,就需要进行页面分裂和纪录移位,来保证纪录的顺序,这就会造成性能损耗
建议将主键设置为 AUTO_INCREMENT, 这样增加新纪录时就只会添加到最后,而不是插入到原有纪录之间
冗余重复索引
如果原有的索引已经可以满足搜索需求时,就不需要再建立新的索引,多余的索引不仅占用空间,还需要维护


 浙公网安备 33010602011771号
浙公网安备 33010602011771号