
软件工程第五周理论与实践学习
一、理论学习
1、完成慕课第六、七章的相关学习。
2、阅读《构建之法》讲义中的“需求”。
需求是多方面的,开发之前应该调研各方面的需求,功能需求、用户需求等等,明确的需求能为软件的开发奠定良好的基础,开发也会事半功倍。
二、实践学习
本周根据课程要求开发一款类似《中国诗词大会》类似规则的游戏,首先是建立诗词资源,根据老师提供的资源,我发现资源上的诗词资源的古诗难度太大,玩家们玩起来可能太难了,想选一些朗朗上口的古诗,我挑了一个网站https://so.gushiwen.org/gushi/xiaoxue.aspx,这里面有小学六个年级的古诗,想先用这些诗完成出口成诗的开发,理想状况应该是数据应存入数据库,但是因为我这方面有所欠缺,所以先按照txt格式来进行编写。
1、数据爬取
因为这些古诗有100来首,如果每首都自己复制的话太累了,就写了个简单的爬虫,首先分析一下它的网页,在chrome打开网页按F12打开开发者工具,CTRL+R刷新以后点开一个请求文件xiaoxue.apx,看一下它的Response,可以看到这里面就包含有需要的链接:
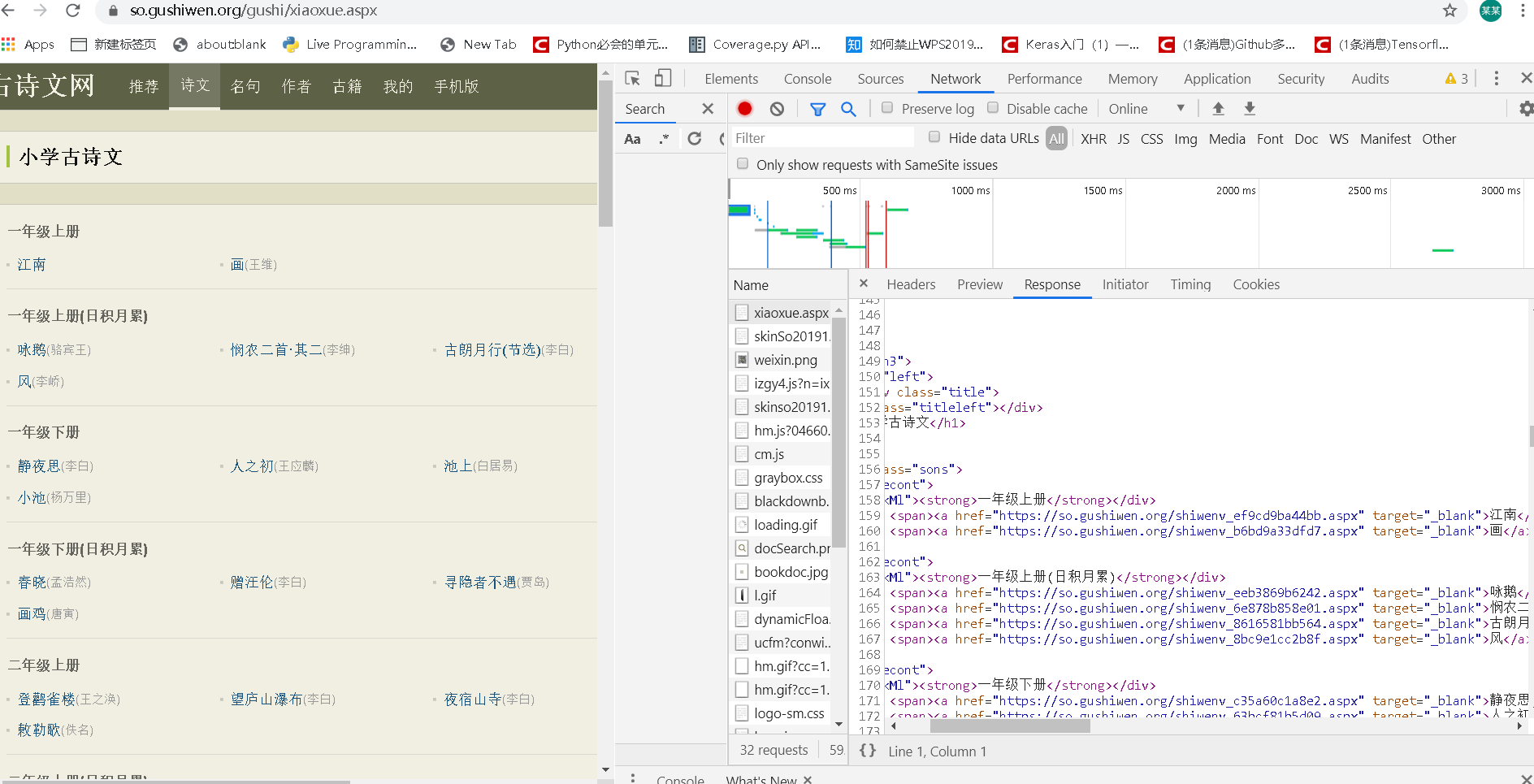
这个网站好像没有反应很快的反爬手段,我爬了很多次来调代码也不禁ip,先访问xiaoxue.aspx的url
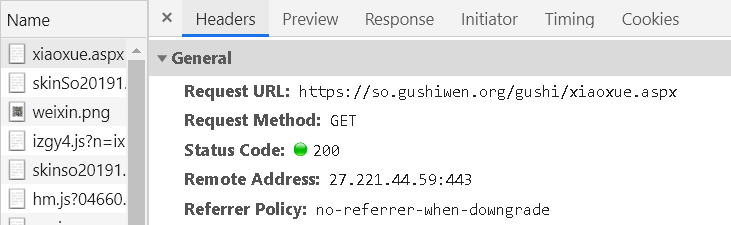
他返回应答页面给我们后可以用正则表达式或者beautifulsoup库提取里面的信息,我们的目标就是各个年级古诗对应的url,这里面就包含古诗信息
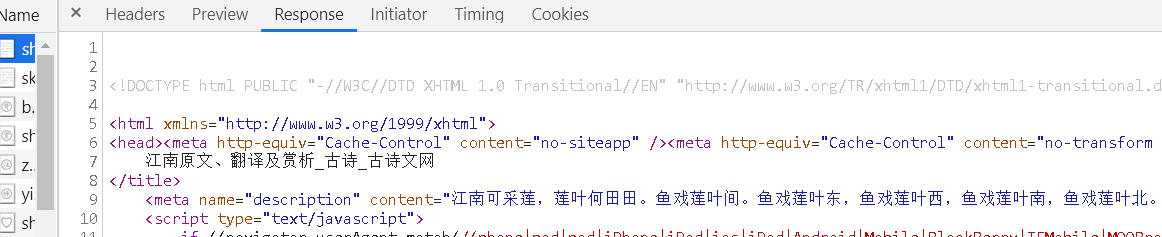
对每一个url访问再把返回报文中的古诗信息提取出来存到本地的txt文件中即可。下面贴出代码
1 from urllib import request,error 2 from bs4 import BeautifulSoup 3 4 if __name__ == '__main__': 5 6 url = "https://so.gushiwen.org/gushi/xiaoxue.aspx" 7 8 try: 9 10 req = request.Request(url) 11 12 rsp = request.urlopen(req) 13 14 html = rsp.read().decode() 15 soup=BeautifulSoup(html,'lxml') 16 html=soup.prettify() 17 div = soup.find_all('a',{'target':'_blank'}) 18 div = div[1:-1] 19 name = div[0].string 20 f = open('D:\桌面\诗词库.txt','w+') 21 num = 1 22 for i in div: 23 # print(i.string) 24 # print(i.get('href')) 25 name = i.string 26 url = i.get('href') 27 req = request.Request(url) 28 rsp = request.urlopen(req) 29 html = rsp.read().decode() 30 31 soup=BeautifulSoup(html,'lxml') 32 html=soup.prettify() 33 div2 = soup.find('meta',{'name':'description'}) 34 print(div2.get('content')) 35 36 f.writelines([str(num),name,'\n',div2.get('content'),'\n']) 37 f.close 38 num+=1 39 except error.URLError as e: 40 print("URLError:{0}".format(e.reason)) 41 print("URLError:{0}".format(e)) 42 43 44 except Exception as e: 45 print(e)
这样就可把一百多首比较经典的诗词爬到txt文件里,我们就可以处理使用他了,这里应该是存到数据库的,后续学习了数据库的相关知识后应该会改进。
2、出口成诗
因为是txt文件,不是数据库导入数据直接用,所以比较繁琐,先把文件里的古诗按照需要分词,先分成一首诗为一个字符串,再将每首诗按句分词一个一个的标题、句子,一首诗放在一个列表,所有的诗也放在一个列表,形成一个嵌套式的列表。分词是一个比较头疼的事情,因为出口成诗里要在句子中挑选一个词提供给玩家,人为分工作量太大,查过资料后目前用的最多是一个叫jieba的库,可以提供分词的功能,下面贴出出口成诗这一段的代码
1 import jieba 2 import sys 3 import re 4 import random 5 from random import randrange 6 import os,time 7 8 9 class WordCreate(): 10 def __init__(self,path): 11 ''' 12 导入文件进行解析 13 ''' 14 with open(path,encoding="utf-8") as file: 15 content = file.read() 16 17 x = re.findall(r'\((.*)\)', content) 18 19 for i in x: 20 print(i) 21 zifu = '('+i+')' 22 print(zifu) 23 content = content.replace(zifu,'') 24 print(content) 25 print(content) 26 content = re.split(r'\d', content) 27 content = [i for i in content if i != ''] 28 self.sc_list = [] 29 for i in content: 30 weak_list = re.split(r'[、。\n\s*]',i) 31 weak_list = [i for i in weak_list if i != ''] 32 self.sc_list.append(weak_list) 33 print(self.sc_list) 34 def random_choice(self): 35 ''' 36 对解析好的文件进行选句、选词 37 ''' 38 whole_sentences = random.choice(self.sc_list) 39 sentences_name = whole_sentences[0] 40 random_sentence_index = randrange(2,len(whole_sentences)) 41 random_sentence = whole_sentences[random_sentence_index] 42 seg_list = jieba.cut(random_sentence,cut_all=False) 43 seg_list = list(seg_list) 44 seg_list = [i for i in seg_list if i != ','] 45 random_word = random.choice(seg_list) 46 print(random_word,'\n') 47 print('请按回车查看答案') 48 while True: 49 key = input() 50 if key == '': 51 print('答案为:{}:{}\n'.format(whole_sentences[0],random_sentence)) 52 break 53 else: 54 print('请输入回车') 55 def loop_execution(self): 56 ''' 57 循环执行命令 58 ''' 59 while True: 60 self.random_choice() 61 print('输入1退推出游戏,按回车继续') 62 key = input() 63 if key == '': 64 continue 65 elif key == '1': 66 print('欢迎再玩') 67 break 68 else: 69 print() 70 71 def main(): 72 generator = WordCreate('D:\桌面\诗词库.txt') #选择合适的路径 73 generator.loop_execution() 74 75 if __name__ == '__main__': 76 main()
这段可以实现在控制台玩游戏,自我体验一般般,因为分词的局限性,有时候给的词比较尴尬。

基本能实现游戏的要求,但是玩起来好像没有太明显的感觉,不知道是我自己不喜欢玩还是写的不行。游戏肯定要有一个界面,就想写个简单的GUI
3、GUI
GUI我选择的是tkinter这个工具,上手比较快,下面是这个界面的动图
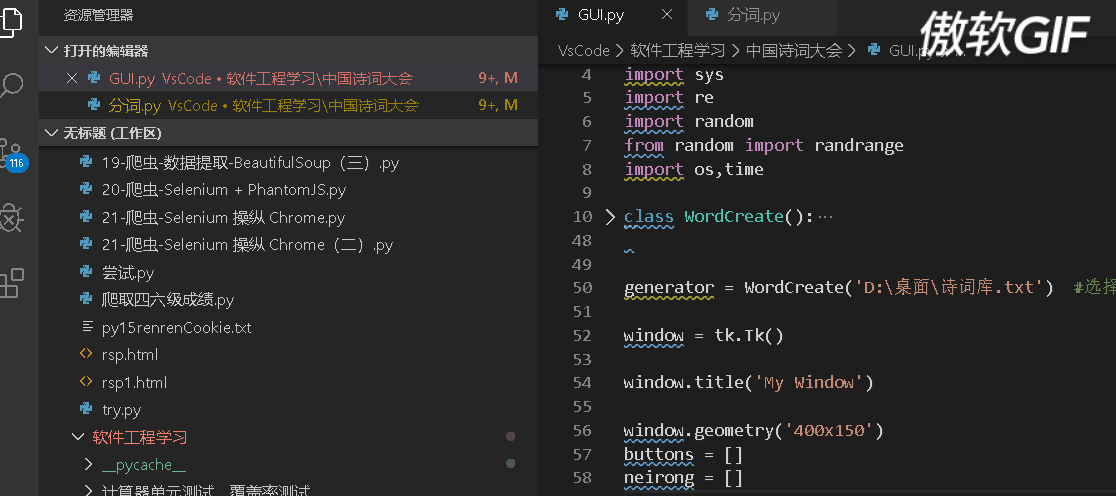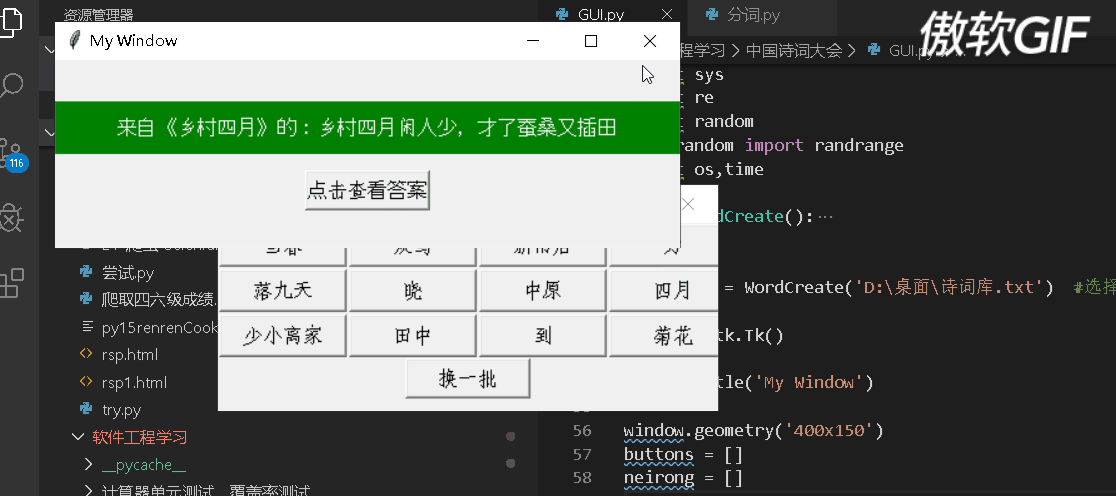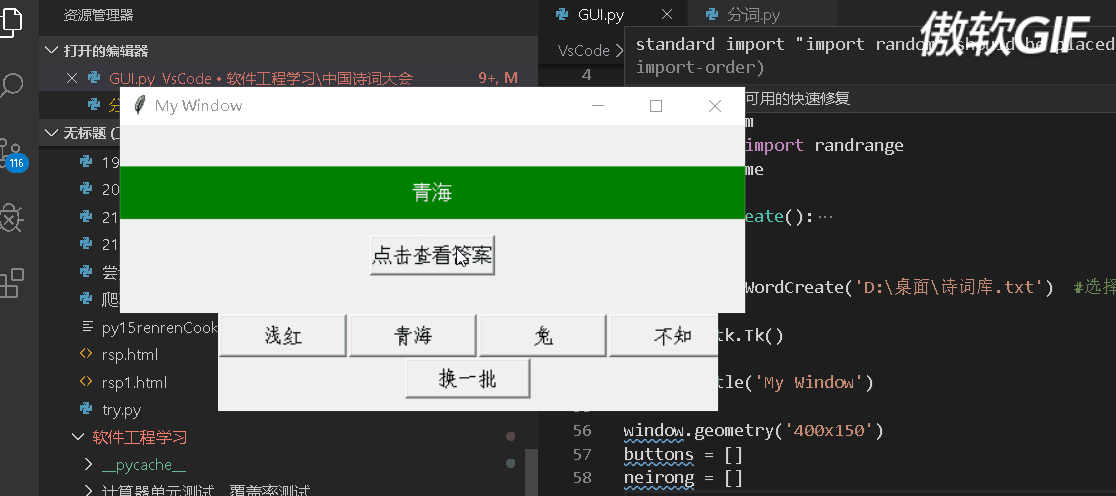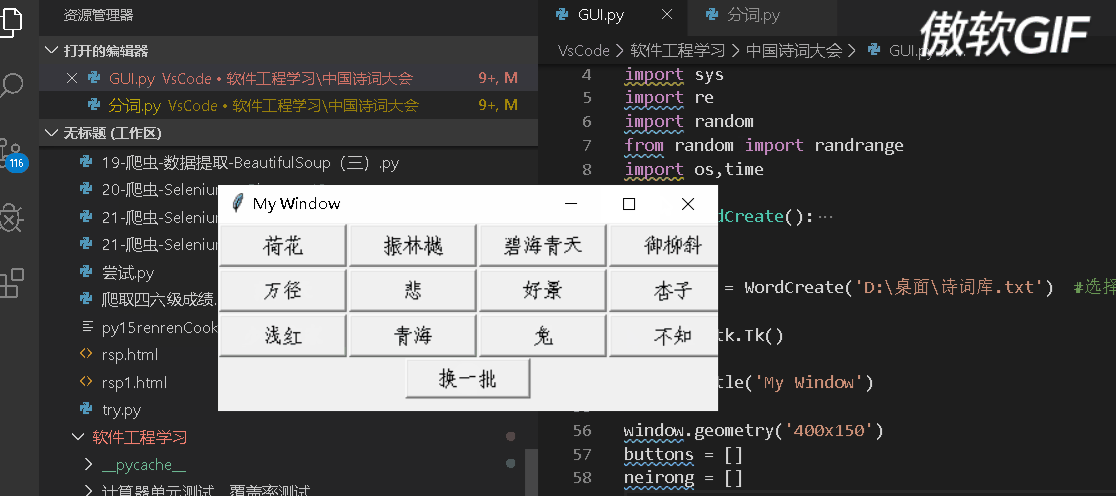
下面贴出代码:
1 import tkinter as tk # 使用Tkinter前需要先导入 2 import tkinter.messagebox 3 import jieba 4 import sys 5 import re 6 import random 7 from random import randrange 8 import os,time 9 10 class WordCreate(): 11 def __init__(self,path): 12 ''' 13 导入文件进行解析 14 ''' 15 with open(path,encoding="utf-8") as file: 16 content = file.read() 17 18 x = re.findall(r'\((.*)\)', content) 19 # content = content.replace('29','cao') 20 for i in x: 21 22 zifu = '('+i+')' 23 24 content = content.replace(zifu,'') 25 26 27 content = re.split(r'\d', content) 28 content = [i for i in content if i != ''] 29 self.sc_list = [] 30 for i in content: 31 weak_list = re.split(r'[、。?:“”\n\s*]',i) 32 weak_list = [i for i in weak_list if i != ''] 33 self.sc_list.append(weak_list) 34 35 def random_choice(self): 36 ''' 37 对解析好的文件进行选句、选词 38 ''' 39 whole_sentences = random.choice(self.sc_list) 40 sentences_name = whole_sentences[0] 41 random_sentence_index = randrange(1,len(whole_sentences)) 42 random_sentence = whole_sentences[random_sentence_index] 43 seg_list = jieba.cut(random_sentence,cut_all=False) 44 seg_list = list(seg_list) 45 seg_list = [i for i in seg_list if i != ','] 46 random_word = random.choice(seg_list) 47 return random_word,sentences_name,random_sentence 48 49 50 generator = WordCreate('D:\桌面\诗词库.txt') #选择合适的路径 51 52 window = tk.Tk() 53 54 window.title('My Window') 55 56 window.geometry('400x150') 57 buttons = [] 58 neirong = [] 59 60 def des(index,n): 61 window = tk.Tk() 62 window.title('My Window') 63 window.geometry('500x150') 64 var=n[0] 65 word_display = tk.Label(window, text=var, bg='green', fg='white', font=('Arial', 12), width=60, height=2) 66 word_display.place(x=250,y=75,anchor='s') 67 answer_button = tk.Button(window,text='点击查看答案', font=('Arial', 12), width=10, height=1, command=lambda :word_display.config(text='来自《'+n[1]+'》的:'+n[2])) 68 answer_button.place(x=250,y=120,anchor='s') 69 70 def create_key_word(): 71 b.destroy() 72 buttons = [] 73 neirong = [] 74 refresh_button = tk.Button(window, text='换一批', font=('Arial', 12), width=10, height=1, command=create_key_word) 75 refresh_button.place(x=200,y=140,anchor='s') 76 for i in range(3): 77 78 for j in range(4): 79 index = j+i*4 80 word,name,sentence = generator.random_choice() 81 sc_list = [word, name, sentence] 82 neirong.append(sc_list) 83 n = neirong[index] 84 c = tk.Button(window, text=word, font=('Arial', 12), width=10, height=1, command=lambda index=index,n=n:des(index,n)) 85 c.grid(row=i, column=j, padx=1, pady=1, ipadx=1, ipady=1) 86 buttons.append(c) 87 88 89 b = tk.Button(window, text='进入游戏', font=('Arial', 12), width=10, height=1, command=create_key_word) 90 b.place(x=200, y=70, anchor='s') 91 window.mainloop()
以上的所有代码都上传了github:https://github.com/dbefb/nickYang
三、总结
本周实践比较有趣,运用了不少知识,但是功能上有很多局限性,比如txt格式的文件中数据的存放方式一改,代码就得改,不利于拓展,后续将利用数据库来进行数据的存储和调用,还有分词比较头疼,分词效果一般导致游戏的可玩性差,GUI界面做的也不是很好看,这些都是后续有待完善的地方。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号