
软件工程慕课第二章编程题—对英文文献的检索
课程地址:https://next.xuetangx.com/learn/THU08091000367/THU08091000367/1516221/exercise/1385903
一、编程思路
1、将待分析文件和查询文件从本地导入
2、利用正则表达式对文档进行分句并用list进行保存
3、对分好的句子进行单词匹配,匹配到以后返回句子所在位置并对句子进行分词
4、对分好的词进行匹配,查找到单词所在位置
二、代码实现
1、首先写出了代码的框架和添加了必要的注释

前两个方法实现思路1、2,第三个方法实现思路3、4,上图是最开始的思路写出的框架,以前我没有写框架的习惯,这次看完课程自己实践后发现写框架可以将自己的思路模块化并记录在代码中,实现每一个模块就更加精准打击,不用整体考虑,只需要专心实现一个模块
下面贴出基于自己写的框架编写完的程序
1 import sys 2 import re 3 from memory_profiler import profile 4 class txtHandle: 5 def __init__(self,contents_path,query_path): 6 ''' 7 导入待分析文件 8 ''' 9 with open(contents_path,encoding="utf-8") as f: 10 self.content = f.read() 11 self.content = (self.content).lower() 12 self.content = (self.content).replace('\n',' ') 13 self.content = re.split(r'[.!?]',self.content) 14 del self.content[-1] #删除最后一个元素,最后一句是句子删除的就是空元素,不是句子删除的就是不完整的句子 15 self.content = [ i for i in self.content if i != ''] 16 self.queryFile(query_path) 17 18 def queryFile(self,path): 19 ''' 20 导入查询文件,把里面的单词弄成一个列表1 21 ''' 22 with open(path,encoding="utf-8") as f: 23 self.query = (f.read()).lower() 24 self.query = (self.query).split('\n') 25 self.query = [ i for i in self.query if i != ''] 26 27 def fileAnalysis(self): 28 ''' 29 对两个文档进行处理,调用findSubscript进行单词在句子、句子在列表中的位置定位 30 ''' 31 list=[] 32 for word in self.query: 33 for sentences in self.content: 34 if sentences.find(word) != -1: 35 setences_position = (self.content).index(sentences) 36 sentences = re.split(r'[ +\'\’\,]',sentences) 37 sentences = [i for i in sentences if i!=''] #删除列表空元素 38 word_position = [i for i,x in enumerate(sentences) if x == word] 39 if word_position == None: 40 pass 41 else: 42 for z in word_position: 43 list.append(str(setences_position+1)+'/'+str(z+1)) 44 45 if list == []: 46 print('None') 47 else: 48 print(','.join(list)) 49 list=[] 50 51 @profile 52 def main(): 53 ''' 54 sys.argv[1]为待分析文件 55 sys.argv[2]为查询文件 56 ''' 57 txt = txtHandle(sys.argv[1],sys.argv[2]) 58 txt.fileAnalysis() 59 60 if __name__ == '__main__': 61 62 main()
这次实践也是一波三折,起初再编写fileAnalysis这个方法的时候,思路不够清晰,导致代码量庞大,而且可读性很差,而且忘记记录了,我将其中查找句子在文档中的位置和单词在句子中的位置抽象成了一个新的方法
1 def findSubscript(self,list,element): 2 3 ''' 4 5 查找单词在列表中的下标 6 7 返回单词句子的位置 8 9 ''' 10 11 for i in range(0,len(list)): 12 13 14 15 if list[i] == element: 16 17 18 19 return i+1
这样程序立马变得简洁,而且可读性较强,但是后来发现,相同的单词可能出多次重复出现在一个句子中,故将这个方法删除,查句子改成:
1 setences_position = (self.content).index(sentences)
查单词改成:
1 word_position = [i for i,x in enumerate(sentences) if x == word]
self.content和sentences已经处理为列表,这样就更加精炼了整个代码
下面是我采用的分析文档和查询文档进行功能测试:
分析文档eng2.txt和查询文档query.txt已经上传githubhttps://github.com/dbefb/nickYang
命令行调用:
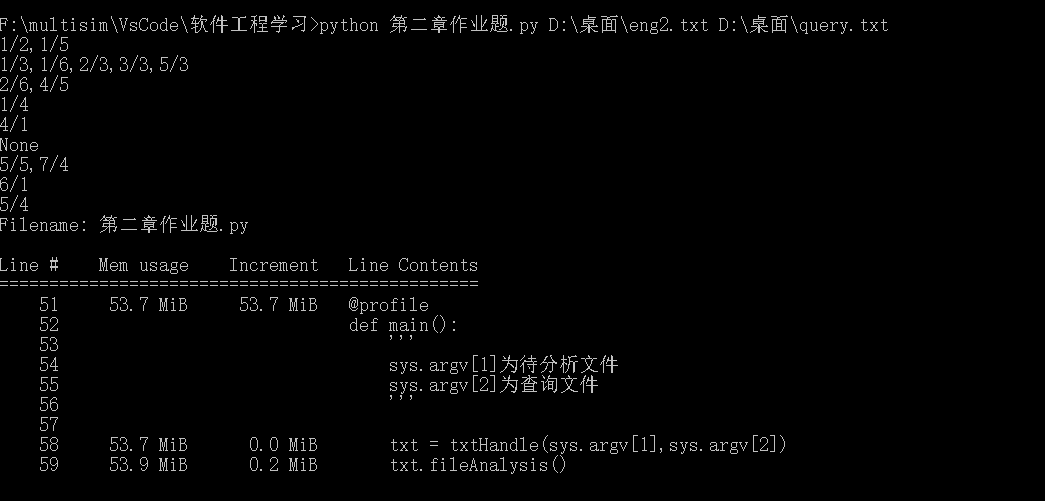
能完成要求的功能
三、性能测试
代码中@profile是进行内存测试的工具,要求的性能测试有一个问题就是1M,5M,30M的英文文档太大了不好弄,我用了很长一段英文文章进行复制沾粘后,勉强达到1M和5M大小,编写了一个脚本进行查询文件的生成,能从分析文档中随机选需要数目的单词按要求写成一个txt:
1 import re 2 import random 3 4 def __init__(path): 5 6 with open (path) as f: 7 query = f.read() 8 9 query = re.split(r'[ .!?="±,°;\n\[\]\(\)]',query) 10 query = [ i for i in query if i!= ''] 11 with open ('D:\桌面\query.txt','w') as tf: 12 for i in range(1,100): 13 tf.write(query[random.randint(0,10000)]) 14 tf.write('\n') 15 __init__('D:\桌面\eng1.txt')
最后跑代码的时候发现一个问题就是分析文档中太多重复的一模一样的句子,导致代码查句子在文章中的位置一直保持不变,在此问题下的性能测试如下:
1、当文档大小为1.05M,随机选100个单词生成查询文档进行测试:
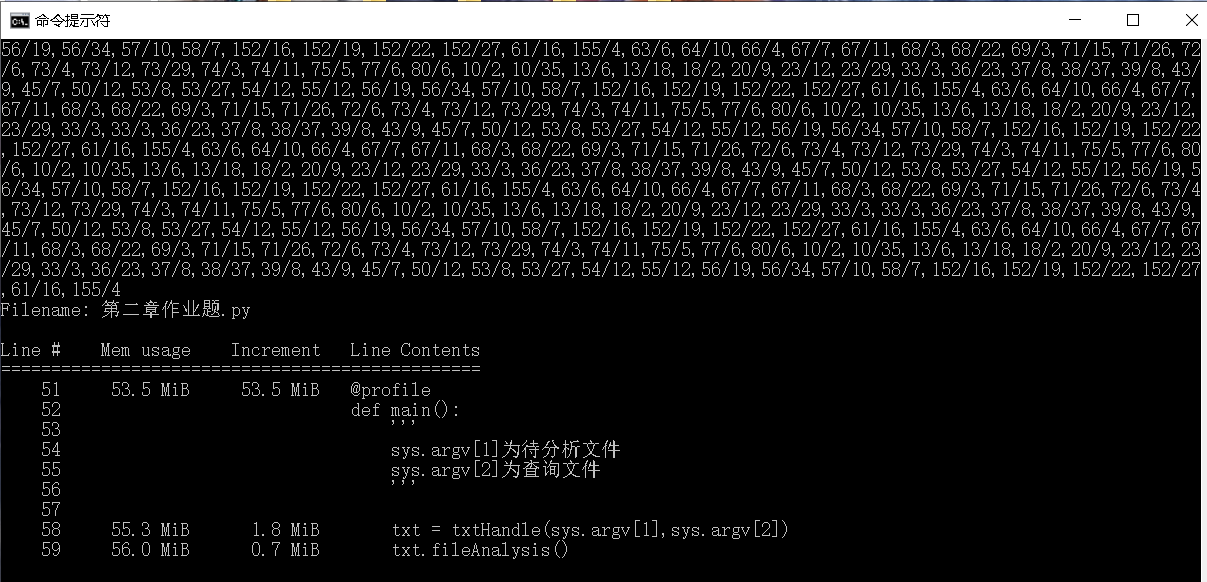
内存占用1.8M,大约16s跑完
2、当文档大小为5.13M,随机选1000个单词生成查询文档进行测试:
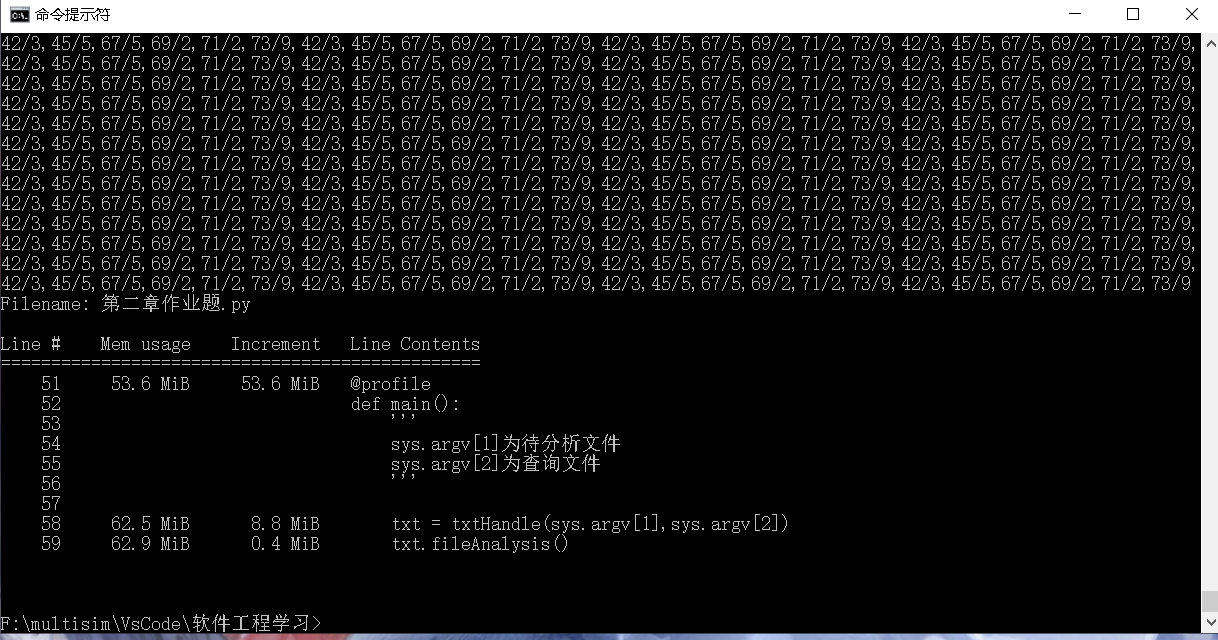
时间上用了13min37s才跑完,严重超出了题目要求的5min,不清楚是否是上述发现的问题导致的,对于30M,2000个单词就没有测试了。
性能方面没有达到要求,目前还不知道如何改进,只能边学边做。
四、PEP8规范性检查
使用pylint工具进行代码规范性检查:
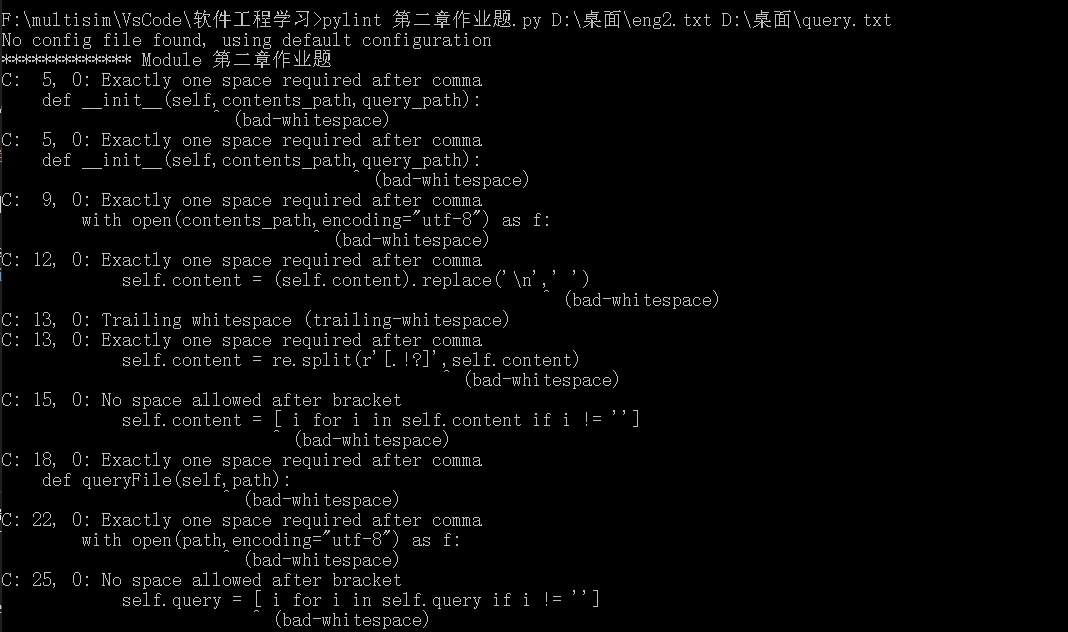
根据错误提示对代码进行修改:
1 """实现对英文文档的分词分句,给出所查单词位置""" 2 import sys 3 4 import re 5 6 from memory_profiler import profile 7 8 class TxtHandle: 9 """txt文档的分析""" 10 def __init__(self, contents_path, query_path): 11 ''' 12 导入待分析文件 13 ''' 14 with open(contents_path, encoding="utf-8") as file: 15 self.content = file.read() 16 self.content = (self.content).lower() 17 self.content = (self.content).replace('\n', ' ') 18 self.content = re.split(r'[.!?]', self.content) 19 del self.content[-1] #删除最后一个元素,最后一句是句子删除的就是空元素,不是句子删除的就是不完整的句子 20 self.content = [i for i in self.content if i != ''] 21 self.query_file(query_path) 22 23 def query_file(self, path): 24 ''' 25 导入查询文件,把里面的单词弄成一个列表1 26 ''' 27 with open(path, encoding="utf-8") as file: 28 self.query = (file.read()).lower() 29 self.query = (self.query).split('\n') 30 self.query = [i for i in self.query if i != ''] 31 32 def file_analysis(self): 33 ''' 34 对两个文档进行处理,调用findSubscript进行单词在句子、句子在列表中的位置定位 35 ''' 36 position_list = [] 37 for word in self.query: 38 for sentences in self.content: 39 if sentences.find(word) != -1: 40 setences_position = (self.content).index(sentences) 41 sentences = re.split(r'[ +\'\’\,]', sentences) 42 sentences = [i for i in sentences if i != ''] #删除列表空元素 43 word_position = [i for i, x in enumerate(sentences) if x == word] 44 if word_position is None: 45 pass 46 else: 47 for i in word_position: 48 position_list.append(str(setences_position+1)+'/'+str(i+1)) 49 50 if position_list == []: 51 print('None') 52 else: 53 print(','.join(position_list)) 54 position_list = [] 55 56 @profile 57 def main(): 58 ''' 59 sys.argv[1]为待分析文件 60 sys.argv[2]为查询文件 61 ''' 62 txt = TxtHandle(sys.argv[1], sys.argv[2]) 63 txt.file_analysis() 64 65 if __name__ == '__main__': 66 67 main()
再次测试:
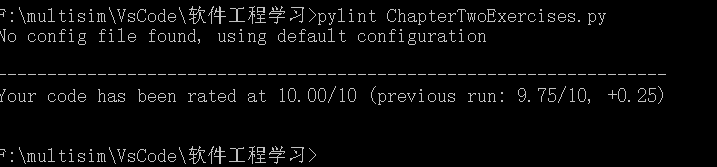
已经修改成符合PEP8规范的代码,代码的可读性更高,更加清晰。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号