
Python第三方库requests的编码问题
PS:这个解决方法可能很简单,但是这是平时的一些细节问题,所以有必要提醒一下!
首先代码不多,就是通过get方法去获取豆瓣首页信息,如图:但是会报UnicodeEncodeError: 'gbk' codec can't encode character '\u2122' in position 42358: illegal multibyte sequence错误
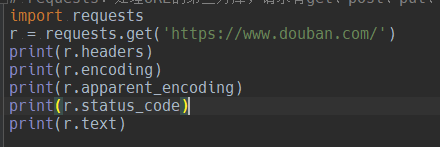
其中,r.encoding是获取响应头Content-Type的charset值,有的网站没有charset字段,就可能使用默认的 ISO-8859-1, 一般那些不规范的页面往往有这样的问题.,所以这种方法可能获取编码不准确。
那么r.apparent_encoding就是获取网站真实的编码,apparent_encoding通过调用chardet.detect()来识别文本编码。
- 情况一:这可能是大家正常情况下最常遇到的问题,那就是没有charset字段,或者编码与charset字段的不符合。
解决方法:
- 如果没有charset字段,可以通过r.apparent_encoding获取真实的编码,再使用r.encoding = ‘xxx’指定正确的编码,这样在调用text时就会根据指定的字符编码进行转换。
- 如果与charset的编码不符合,直接用r.encoding = ‘xxx’指定charset的编码就OK啦!
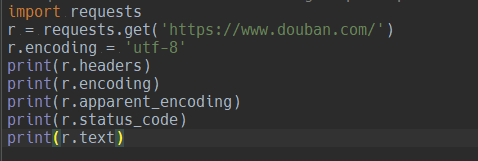
- 情况二: 通过r.encoding或者r.apparent_encoding获取的编码都是一样的,但是还是会报编码错误,这种情况可能就要考虑下IDE的字符编码设置问题了。
以PyCharm为例按如下路径:file→settings→Editor→File Encodings→Project Encoding进行设置,如图:

推荐看一下我以前的文章:Pycharm有必要改的几个默认设置项
欢迎与我一起学习!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号