MySQL索引教程
什么是索引:
索引是一种数据结构,会对添加索引的字段的值进行排序存放,提高查询效率;一张表中可以添加多个索引;innodb存储引擎默认使用的是b+tree索引结构,也支持哈希、全文索引。
innodb存储引擎中的表使用的是索引组织表(IOT);
索引的缺点:
①索引维护成本高(可通过insert buffer,change buffer提升DML语句效率)
②占用更多的存储空间(磁盘和内存)
③索引过多会造成优化器负担
应该创建索引的列
在经常查询的列上,可以加快搜索的速度;
在经常需要根据范围(<,<=,=,>,>=,BETWEEN,IN)进行搜索的列上创建索引,因为索引已经排序,可通过叶子节点双向指针快速查找;
在经常需要排序(order by)的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
不该创建索引的列
对于那些在查询中很少使用或者参考的列不应该创建索引。
对于那些只有很少数据值或者重复值多的列也不应该增加索引。
对于那些定义为text, image和bit数据类型的列不应该增加索引,造成索引树高度增加、内存空间浪费。
索引最大的长度:
默认最大长度767字节;innodb_large_prefix=on 3072字节
b+tree原理:
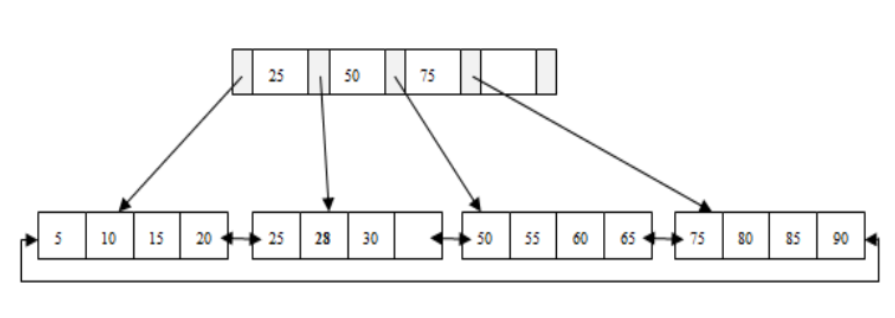
索引树高度:2
非叶子节点:non leaf page[root page],存字段的值和指针
叶子节点:leaf page,存所有字段的值和指针
指针:指针与页是映射的关系,通过指针就可以找到对应的页;指针可以存放在上一层节点;6字节
页:用于存放数据,16k;innodb_page_size | 16384
双向指针:用于保存相邻页的指针
b+tree:用于存储数据并高效检索数据,是基于页管理数据。
存储数据:数据都是存放叶子节点,并经过排序存放
b+tree删除操作:主要依赖填充因子,默认最小值为50%,如果小于50%,则会发生页合并操作
b+tree插入操作:
情况一:叶子节点有空闲,则直接插入数据
情况二:叶子节点已满,则会发生split分裂页操作
情况三:如果叶子节点和其上一层节点都已满,则会发生两次split分裂页操作
创建索引
索引名称 index_name 是可以省略的,省略后,索引的名称和索引列名相同。
-- 创建普通索引
CREATE INDEX index_name ON table_name(col_name);
-- 创建唯一索引
CREATE UNIQUE INDEX index_name ON table_name(col_name);
-- 创建普通组合索引
CREATE INDEX index_name ON table_name(col_name_1,col_name_2);
-- 创建唯一组合索引
CREATE UNIQUE INDEX index_name ON table_name(col_name_1,col_name_2);
修改表结构创建索引
ALTER TABLE table_name ADD INDEX index_name(col_name);
创建表时直接指定索引
CREATE TABLE table_name (
ID INT NOT NULL,
col_name VARCHAR (16) NOT NULL,
INDEX index_name (col_name)
);
删除索引
-- 直接删除索引
DROP INDEX index_name ON table_name;
-- 修改表结构删除索引
ALTER TABLE table_name DROP INDEX index_name;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号