

scrapy爬虫之模拟ajax post请求获取数据
实质:分析真实请求地址,根据规则构造新地址从而获得数据。

分析发现数据是通过异步ajax方式→post 获得的
于是通过分析response
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
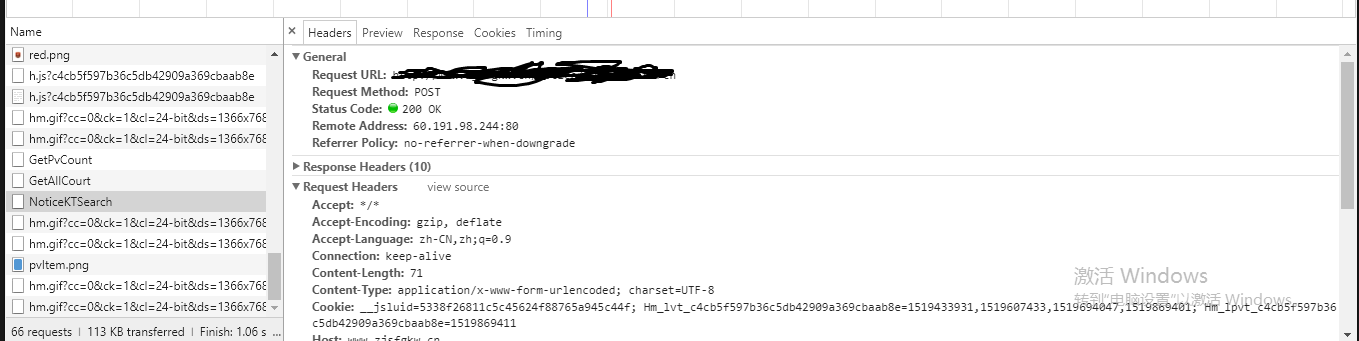


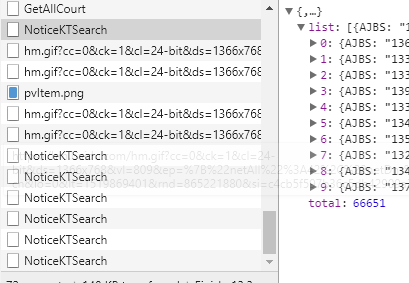
发现每次翻页 网页都会新请求一个NoticeKTSearch,以post方式请求
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓


把formdata以 字典(名为body)形式存储下来 ,用FormRequest重新请求二次解析页。
最后用JSON转字典格式,直接提取数据,over!!!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号