
clusterware启动顺序——CRSD
CRSD层面
1.启动过程
CRSD层面的主要工作是启动crsd.bin守护进程,然后由crsd.bin读取OCR中的信息并和PE master节点通信,之后与crsd.bin对应的代理进程被启动,同时还启动集群所有的应用程序资源。CRSD管理的应用程序之间的依赖关系(启动顺序)可以通过以下图形了解。
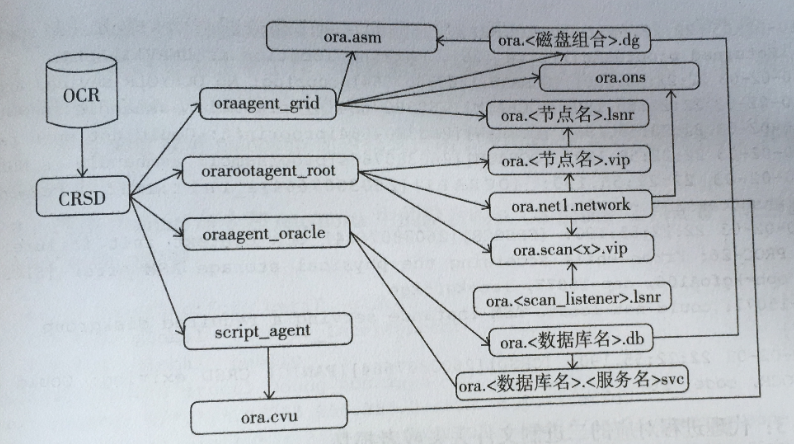
具体的启动过程如下
1) crsd.bin从OCR中获得所需要启动的资源列表。
2) crsd.bin启动对应的代理进程。
3) 代理进程oraagent_root启动集群的公网资源,之后集群的VIP和SCAN VIP资源也被启动。
4) 代理进程oraagent_grid启动和VIP对应的Listener资源,以及和SCAN VIP对应的SCAN Listener资源。
5) 代理进程oraagent_grid启动ONS资源。
6) 代理进程oraagent_grid启动ora.asm资源,并启动其他的磁盘组资源。
7) 代理进程oraagent_oracle启动数据库资源,之后启动对应的数据库服务资源。
8) 代理进程script_agent启动ora.cvu资源。
2.可能出现的问题
(1)导致CRSD无法启动集群的应用程序资源的可能原因有:
原因1:/etc/oracle/ocr.loc指向了错误的OCR文件
[grid@ebsdb1 11.2.0]$ cat
/etc/oracle/ocr.loc
ocrconfig_loc=+VOTE_DG
local_only=FALSE
原因2:OCR损坏或者已经丢失。
原因3:代理进程对应的二进制文件丢失或者损坏。
原因4:集群的私网出现问题,从而导致crsd.bin无法和远程节点通信。
原因5:$GRID_HOME/bin/crsd.bin文件的权限错误或者文件已经损坏。
原因6:$GRID_HOME/crs/init/*.pid的文件指向了其他的运行中的进程。
相应的解决方法如下:
方法1:修改/etc/oracle/ocr.loc中的OCR位置,使其指向正确的OCR磁盘组,如果使用了裸设备或集群文件系统,则确认它指向了正确的裸设备名或文件系统名。
方法2:从正常的OCR备份中恢复OCR。
方法3:从正常的节点上复制代理进程的二进制文件到有问题的节点。
方法4:确认私网能够正常工作。
方法5:确认$GRID_HOME/bin/crsd.bin文件的权限正确。如果问题是crsd.bin文件损坏,可以从正常的节点上复制该文件到问题节点。
[grid@ebsdb1 11.2.0]$ ls -l
$GRID_HOME/bin/crsd.bin
-rwxr----x 1 root oinstall 106051083 Jun
16 2014 /ebsdb/grid/11.2.0/bin/crsd.bin
方法6:删除有问题的$GRID_HOME/crs/init/*.pid文件,之后重新启动CRSD,例如
crsctl stop res ora.crsd -init
crsctl start res ora.crsd -init
(2)导致VIP或SCAN VIP无法正常启动的可能原因:
原因1:由于网络问题导致集群公网资源无法启动。
原因2:由于DNS问题导致无法正常解析VIP和SCAN VIP。
原因3:VIP或SCAN VIP地址已经被网络中的其他主机占用。
原因4:OCR中记录的VIP或SCAN VIP信息和OS层面不一致。
对应的解决问题方法如下:
方法1:确认集群公网能够正常工作,而且公网资源ora.net1.network正常工作。
方法2:确认DNS能够正常工作,而且能够正确地解析VIP和SCAN VIP,例如使用nslookup <VIP或SCAN VIP对应的主机名>验证。
方法3:使用ping或者nslookup命令找到占用了VIP或SCAN VIP的主机,以解决地址冲突问题。
方法4:使用ifconfig命令和/etc/hosts中的信息确认OS层面的公网配置,之后通过以下的命令检查OCR中的配置
[grid@ebsdb1 11.2.0]$ oifcfg getif -global
eth0172.28.1.0 global public
eth1192.168.10.0 global cluster_interconnect
[grid@ebsdb1 11.2.0]$ srvctl config
nodeapps -a
Network exists:
1/172.28.1.0/255.255.255.0/eth0, type static
VIP exists:
/ebsdbvip1/172.28.1.223/172.28.1.0/255.255.255.0/eth0, hosting node ebsdb1
VIP exists:
/ebsdbvip2/172.28.1.224/172.28.1.0/255.255.255.0/eth0, hosting node ebsdb2
[grid@ebsdb1 11.2.0]$ srvctl config scan
SCAN name: ebsscan, Network:
1/172.28.1.0/255.255.255.0/eth0
SCAN VIP name: scan1, IP:
/ebsscan/172.28.1.225
(3)导致Listener或SCAN Listener无法正常启动的可能原因
由于Listener和SCAN Listener是依赖于VIP和SCAN VIP的,所以绝大部分Listener或SCAN Listener无法启动的问题都是由于VIP和SCAN VIP的问题导致的。
(4)ora.asm和磁盘组资源无法正常启动的可能原因
对于ora.asm,由于这个资源实际上是初始化资源ora.asm的一个代理资源,这个资源可能出现问题的原因可以参考之前的内容。而对于磁盘组资源ora.<磁盘组名>.dg,它实际上是用于反映对应ASM磁盘组的状态,如果这个资源无法启动,那在绝大部分情况下表明对应的ASM磁盘组没有被挂载,而磁盘组无法挂载的主要原因就是底层对应的ASM磁盘出现了问题,例如:某些磁盘的权限和属主错误、磁盘头信息错误、磁盘无法访问等。
解决办法如下:
方法1:修正ASM磁盘的权限和属主信息,对应的基本原则是:ASM磁盘的属主应该是grid用户,对应的组应该是asmadmin,而且grid用户和asmadmin组都应该对磁盘组有读写权限。
方法2:从11.1.0.7版本开始,ASM磁盘头信息会自动备份到AU#1的倒数第二个块中。对于AU大小为1MB的磁盘组,每个AU包括的块数量=1024KB/4KB=256个,备份信息位于AU#1的第254号块(从0号开始)。可以使用下面的命令手动恢复备份的磁盘头信息:
kfed repair /dev/oracleasm/disks/DATA1
aus=1048576
方法3:如果磁盘无法被访问,那绝大部分情况下都是由操作系统或存储层面的问题导致的。
(5)数据库资源或数据库服务资源无法启动的可能原因
对于数据库资源,实际上代理进程完成的工作就是通过资源的定义,执行startup spfile=<spfile位置>命令。而对于数据库服务资源,代理进程执行的命令就是alter
system set service_names=<数据库服务名称> sid=<数据库实例名>。可能导致它们无法启动的原因如下:
原因1:数据库资源的某些属性配置错误,如果数据库的启动选项被设置成了nomount,这表示代理进程会使用“startup nomount”的方式启动数据库。如果数据库角色被设置成了STANDBY,则表示代理进程认为这是一个备用数据库,那么数据库在启动时会导致问题。
原因2:数据库的health check文件($ORACLE_HOME/dbs/hc_<实例名>.dat)无法被访问。
原因3:操作系统验证被禁用。
原因4:$ORACLE_HOME/bin下的Oracle二进制文件的权限或者属主配置错误。
原因5:数据库资源所依赖的磁盘组没有被挂载。
对应的解决方法如下:
方法1:确保数据库资源在OCR中的属性是正确的,以下是一个正常的数据库资源属性的输出
[orasit@ebsdb1 ~]$ srvctl config database
-d sit
Database unique name: SIT
Database name:
Oracle home: /ebsdb/sit/db/tech_st/11.2.0
Oracle user: orasit
Spfile:
Domain:
Start options: open
Stop options: immediate
Database role: PRIMARY
Management policy: AUTOMATIC
Server pools: SIT
Database instances: SIT1,SIT2
Disk Groups: DATA_DG
Mount point paths:
Services:
Type: RAC
Database is administrator managed
方法2:确保数据库的health check文件存在而且能够访问,例如
[orasit@ebsdb1 ~]$ ls -l $ORACLE_HOME/dbs
total 31812
……
-rw-rw---- 1 orasit oinstall 1544 Feb 10 18:56 hc_SIT1.dat
……
方法3:启用操作系统验证。在$ORACLE_HOME/network/admin/sqlnet.ora文件中将一下行注释掉或者直接删除。
SQLNET.AUTHENTICATION_SERVICES=(NTS)
方法4:确保$ORACLE_HOME/bin下的Oracle二进制文件的权限或者属主配置正确,例如
[orasit@ebsdb1 ~]$ ls -l
$ORACLE_HOME/bin/oracle
-rwsr-s--x 1 orasit asmadmin 239729642
Feb 8 11:55 /ebsdb/sit/db/tech_st/11.2.0/bin/oracle
方法5:确保数据库所在的磁盘组已经被挂载。如果磁盘组对应的磁盘存在问题,在解决了磁盘组层面的问题后,使用类似于下面的命令挂载磁盘组:
alter diskgroup DATA mount;
如果磁盘组的冗余度是normal或者high,而只是个别的磁盘出现了问题,且没有数据丢失,可以使用类似下面的命令强制挂载磁盘
alter diskgruop DATA mount force;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号