
Linux下的uniq,head,tail,cut,paste
paste
按列合并
例如文件1是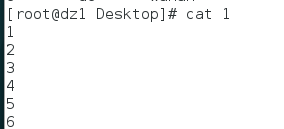 文件2是
文件2是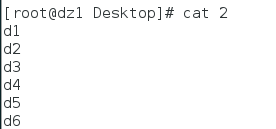 文件3是
文件3是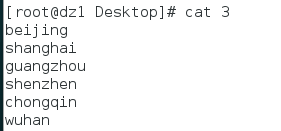
paste 1 2 3就会在屏幕上标准输出一个

uniq
合并文件中的连续重复行并且做标准输出
可以配合sort排序将不连续的重复行去掉
uniq [filename] 合并文件中连续重复的行
uniq -u [filename] 将连续重复的行只显示一次
uniq -c [filename] 去掉连续的重复的行
uniq -d [filename] 只显示重复的行
cut
按模式分割文件中的内容并作标准输出、
cut -b 按字节选取(忽略多字节字符边界例如汉字,除非加上参数-n)
cut -d"" 定义分隔符,默认为tab键,一般和-f一起使用(例如一个空格做分隔符,-d" " 遇到多个空格时需要其他命令来合并)
cut -f 选取的字段
cut -c 按字符为单位进行分割,可以选取指定字符
cut -n 必须和-b一起使用,取消分割多字节字符,即如果字符的最后一个字节落在由-b参数列表指定的范围之内,则该字符将被选出,否则,该字符将被排除
-b -f -c都是可以选取特定位置或者范围的
例如-b N(第N项) -f N-(N项到最后一项) -c N-M(N项到M项) -b -M(第一项到M) -f -(第一项到所有项)
head
查看文件的头n行
一般和cut一起在管道符后面使用
head [filename] 查看一个文件头10行
head -n number [filename] 查看一个文件头number行
如果head后面没有接filename那么调用前面的标准输入
tail
查看文件的最后n行
tail [filename] 查看一个文件的后10行
tail -n number [filename] 查看一个文件最后number行
tail -f [filename] 一直查看filename的后10行,可以用来监控log
若以分隔符开头则分隔符之后算第二段
例子(分隔符为:)
:dada:wewe中的dada为第二段-f 2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号