深入浅出图神经网络 第2章 神经网络基础 读书笔记
 《深入浅出图神经网络》第2章的个人读书笔记
《深入浅出图神经网络》第2章的个人读书笔记
第2章 神经网络基础
2.1 机器学习基本概念
2.1.1 机器学习的分类
机器学习有以下几种常见的分类方法:
- 根据训练数据是否有标签可分为:
- 监督学习:训练数据中每个样本都有标签,通过标签指导模型进行训练
- 无监督学习:训练数据完全没有标签,算法从数据中发现约束关系,如数据之间的关联等,典型的无监督算法有如聚类算法
- 半监督学习:训练数据又有有标签数据,又有无标签数据(GNN划时代的论文GCN的模型就是半监督的)
- 从算法输出的形式上可分为:
- 分类问题:模型输出离散值
- 回归问题:模型输出连续值
2.1.2 机器学习的流程
机器学习的流程可以简单概括为:提取特征-->建立模型-->确定损失函数和进行优化求解。
提取特征这一步没什么好说的,如果用的是经典的数据集那么特征都是被提取好的,如果要自己提取特定数据的特征那就要具体问题具体分析了。
建立模型这一步,书中介绍传统的机器学习模型有逻辑回归、随机森林等(话说我之前一直以为这些就算是分类器还算不上机器学习来着...);而深度学习的方法有多层感知机(MLP),卷积网络等。模型可以看做是一个函数\(Y=f(X;W)\),函数建立了特征X到标签Y到映射,而W则是模型中的参数。
确定损失函数才能评估一个模型的好坏,可以通过损失函数的值来优化模型。在2.1.3中介绍了一些常见的损失函数。
我们接着对流程中的后两步进行细致一点的说明,假设现在有训练集有N个样本,有\(X=\{(x_i, y_i)|i=1,2,...,N\}\),分别为样本特诊及其对应的标签,特征\(x_i\in R^d\),标签\(y_i\in Y=\{0,1,...,K\}\)是离散的。模型就是要给出\(f:R^d\to R^K\)这样的映射,最后的输出在每个类别上有一个概率\(P(Y|x_i)=f(x_i;\theta)\),我们要取的就是最大的概率值作为最后模型给出的标签\(y_i^*=argmax(P(Y|x_i))\),\(argmax\)取到的最大的参数就是最大的概率值。
那么我们前面提到了该如何评估一个模型的好坏,就是要评价我们得到的预测和真实值的差异,即\(y_i\)和\(y_i^*\)之间的差异,而且我们需要一个可以量化的方法,这个方法就是定义一个损失函数(Loss Function)。通常用\(L(y,f(x;\theta))\)表示,通过最小化损失函数训练模型就是优化求解的过程,可以表示为\(\theta^*=argmin[\frac{1}{N}\Sigma^N_{i=1}L(y_i,f(x_i;\theta))+\lambda\Phi(\theta)]\),期中均值函数表示的经验风险函数,L表示的是损失函数,\(\Phi\)表示的是正则化项(regularizer)或者惩罚项(penalty term),可以是L1或L2以及其他正则函数。总之过程就是在寻找是的目标函数最小的\(\theta\)值。
这个过程当然不是一蹴而就的,在训练过程中可能要迭代训练非常多轮直到损失不再变化,这时就称模型已经收敛。这一过程还有两个隐患,一个是训练过程一直用的是训练集,模型可能过拟合,变得只认识训练集而不认识测试集;也可能欠拟合,无论如何也无法在训练集上收敛。
2.1.3 常见损失函数
- 平方损失函数:\(L(y,f(x,\theta))=\frac{1}{N}\Sigma^N_{i=1}(y_i-f(x_i;\theta))^2\),常用于回归类问题
- 交叉熵函数:\(L(y,f(x))=H(p,q)=-\frac{1}{N}\Sigma^N_{i=1}p(y_i|x_i)log[q(\hat y_i|x_i)]\),p表示数据标签的真实分布,q表示模型预测的分布,所以有\(p(y_i|x_i)\)就是数据的真实标签。对于二分类问题交叉熵可以化为二元交叉熵:\(L(y,f(x))=-\frac{1}{N}\Sigma^N_{i=1}[y_ilogq(y_i=1|x_i)+(1-y_i)log(1-logq(y_i=1|x_i))]\)
2.1.4 梯度下降算法
原理
前面提到了训练模型时需要最小化损失函数,那么这个最小化的过程也不是说小就小了,最常用的就是梯度下降算法。
考虑多元函数\(f(x)\)(带入机器学习过程就是损失函数\(L\)),梯度就是对其中每个自变量的偏导数构成的向量,有\(f'(x)=\nabla f(x)=[\nabla f(x_1),...,\nabla f(x_n)]^T\),考虑\(f(x+\Delta x)=f(x)+f'(x)^T\Delta x+o(x)\)。
回顾我们的目标:最小化损失函数。那么就是想要\(f(x+\Delta x)<f(x)\),忽略泰勒展开中的高阶项,就需要有\(f'(x)^T\Delta x<0\)。而又有\(f'(x)^T\Delta x=||f'(x)^T||·||\Delta x||·cos\theta\)。
向量的点积可以用二范数来表示,\(x^Ty=||x||·||y||·cos\theta\)。
我们取\(\Delta x=-\alpha f'(x)\)来保证每次更新都会使得原式越来越小。这里\(\alpha\)是一个超参数,就是学习率(代码中常出现的\(lr\))。
所以梯度下降的过程就是先初始化参数,之后让模型给出预测,计算损失函数,求导得到梯度,最后基于梯度更新,并不断重复直到模型收敛。
随机初始化参数:\(\{\theta_0^{(0)},...,\theta_0^{(k)}\}\),计算\(L_t=L(Y,f(X;\Theta_t))\),得到梯度\(\nabla \Theta_t=\frac{\partial L_t}{\partial \Theta_t}=\{\nabla \theta_t^{(0)},...,\nabla \theta_t^{(k)}\}\),并更新\(\Theta_{t+1}=\{\theta_t^{(0)}-\alpha \nabla \theta_t^{(0)},...,\theta_t^{(k)}-\alpha \nabla \theta_t^{(k)}\}\)。
随机梯度下降算法
原理所说的梯度下降算法被称作批梯度下降算法(BGD),其使用了全量的样本进行计算。
使用单一样本近似估计梯度的方法则被称为随机梯度下降(SGD)。具体来说,训练时每次从训练集中随机选择一个样本,计算损失和梯度,进行参数更新。显然其计算复杂度很低,但也有缺陷:虽然单一样本的梯度对全体样本的梯度是一个无偏估计,但仍然存在着偏差和不确定性,收敛速度会更慢。
改进的方法自然就是多选一些样本(但仍然少于全体样本),这样的方法被称作小批量随机梯度下降(mini-batch SGD)。
2.2 神经网络
2.2.1 神经元
基本神经元包括三个部分:输入信号,线性组合和非线性激活函数。
\(z_i=\Sigma^m_{j=1}w_{ij}x_j\),这里\(x\)是输入信号,\(w\)是神经元的权值,而\(z\)则是输入信号的线性组合。
\(a_i=\sigma(z_i+b)\),这里\(\sigma\)是激活函数,\(b\)是偏置,\(a\)就是神经元的输出信号。
2.2.2 多层感知器
单隐层感知器
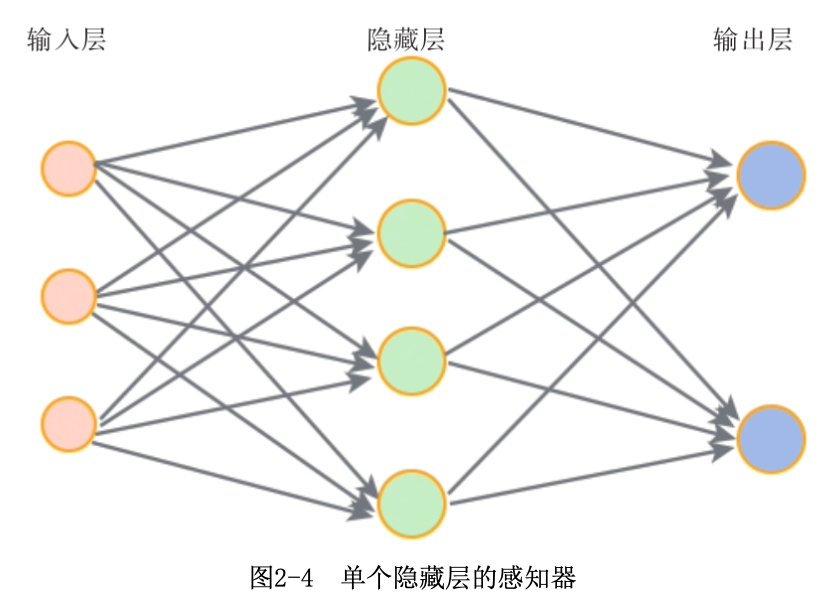
对于如图所示的感知器,计算过程可以表示为:\(f(x)=f_2(b^{(2)}+W^{(2)}(f_1(b^{(1)}+W^{(1)}x)))\)
感知器的信息传递
多层感知器MLP:
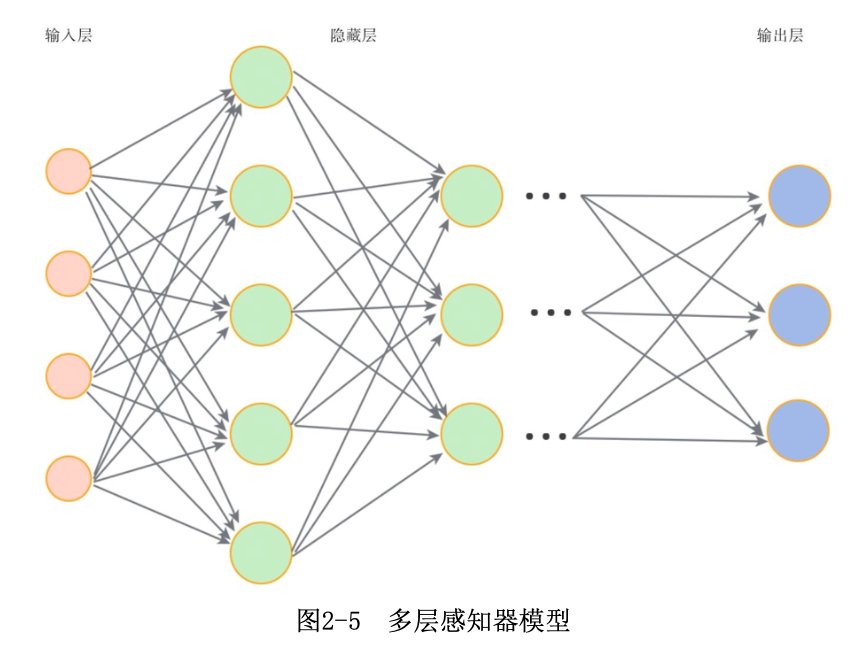
不同的就是有多个隐藏层,所以有更一般的MLP信息传播公式:
\(z^{(l)}=W^{(l)}·a^{(l-1)}+b^{(l)},a^{(l)}=\sigma_l(z^{(l)})\)
每层网络中,可训练的是\(\{W^{(l)},b^{(l)}\}\)
2.3 激活函数
激活函数的非线性让神经网络可以逼近任何非线性函数,因为注意到神经网络中会先进行线性组合,如果没有非线性元素的引入,那么神经网络最后的结果一定是线性的,表达能力有限。
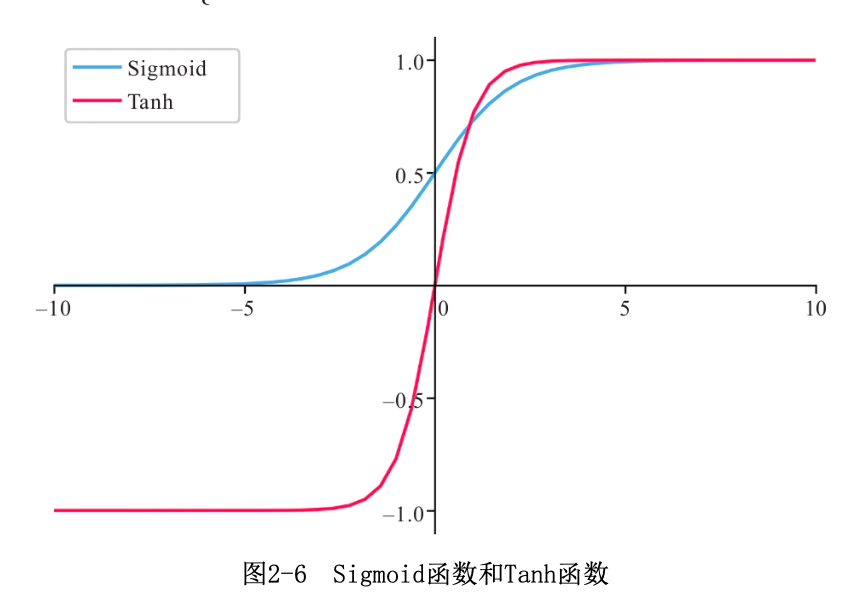
2.3.1 S型激活函数
Sigmoid:\(\sigma(x)=\frac{1}{1+e^{-x}}\),常用于二分类器最后一层的激活函数
Tanh:\(tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}\)
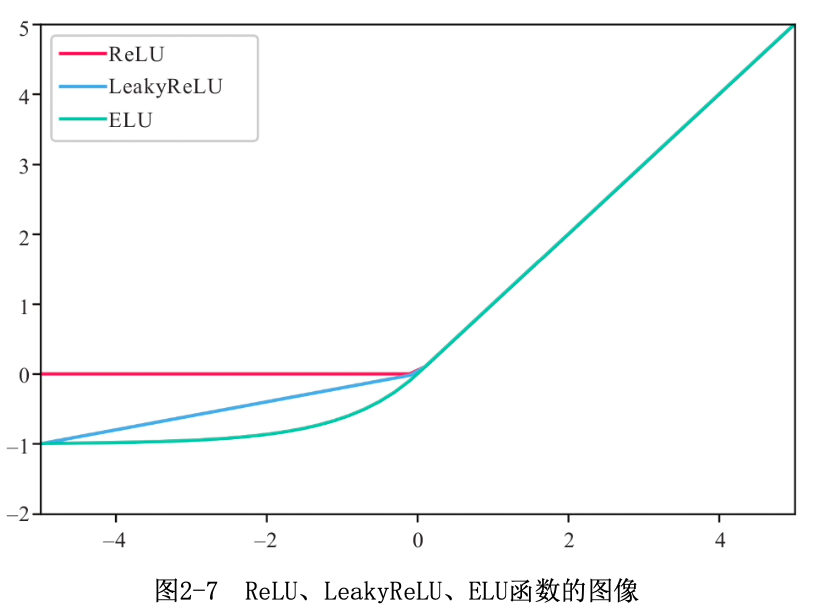
2.3.2 ReLU及其变种
ReLU:$ReLU(x)=\begin{cases} x&\text{if $$ x}\ge0 \ 0& \text{if $$ x < 0} \end{cases}$
输入为负梯度为0,输入为正梯度为1,单侧抑制。可能会导致某个神经元“死亡”。
LeakyReLU:$LeakyReLU(x)=\begin{cases} x&\text{if $$ x}>0 \ \lambda x& \text{if $$ x} \le 0 \end{cases}$
\(\lambda\)是一个超参数用来避免神经元“死亡”。
PReLU则就是将LeakyReLU中的\(\lambda\)变为可训练的参数。
ELU:$ELU(x)=\begin{cases} x&\text{if $$ x}\le0 \ \alpha(e^x)-1& \text{if $$ x} < 0 \end{cases}$
输入为负时进行非线性变换,其中\(\alpha\)是一个超参数,可以调节梯度为0。
2.4 训练神经网络
2.4.1 神经网络运行过程
- 前向传播:给定输入和参数,向前计算,得到模型预测结果
- 反向传播:基于预测结果,计算损失函数,计算梯度
- 参数更新
2.4.2 反向传播
对样本\((x,y)\),前向传播得到\(\hat y\),对应损失\(L(y, \hat y)\),参数矩阵梯度\(\nabla W^{(l)}=\frac{\partial L(y,\hat y)}{\partial W^{(l)}}\)。
根据链式法则展开参数矩阵梯度有\(\nabla W^{(l)}=\frac{\partial z^{(l)}}{\partial W^{(l)}}\frac{\partial L(y,\hat y)}{\partial z^{(l)}}\)。
定义\(\delta^{(l)}=\frac{\partial L(y,\hat y)}{\partial z^{(l)}}\)为误差项,其衡量了\(z^{(l)}\)对损失的影响,可进一步展开得到\(\delta^{(l)}=\frac{\partial a^{(l)}}{\partial z^{(l)}}\frac{\partial z^{(l+1)}}{\partial a^{(l)}}\frac{\partial L(y,\hat y)}{\partial z^{(l+1)}}\)。
回想:\(z^{(l)}=W^{(l)}·a^{(l-1)}+b^{(l)},a^{(l)}=\sigma_l(z^{(l)})\)
可继续变换得到:\(\delta^{(l)}=\sigma'(z^{(l)})\odot W^{(l+1)^T}\delta^{(l+1)}\),其中\(\odot\)是Hadamard积。
可以看到第\(l\)和第\(l+1\)层的误差项是相关的,这也是为什么可以反向传播。
(再后续的推导看的就更懵了,没怎么给过程,读了一些其他人的读书笔记发现有人反应这里的推导有误,参考了其他书籍的BP推导发现从一开始符号用的就不一样,所以这部分就先不多写了,等啃明白了BP再回来补。这里给一个个人认为写的比较清晰的推导 https://zhuanlan.zhihu.com/p/45190898 ,其实和书上的思路是一致的,就是书上的过程太简略了...)
2.4.3 优化困境
梯度消失:Sigmoid和Tanh函数在逼近上下边界的时候梯度会比较小,导致参数更新慢甚至不更新,模型难以训练,称为梯度消失
局部最优:损失函数和参数之间的关系是非凸的,在梯度下降的时候可能陷入局部最优

 浙公网安备 33010602011771号
浙公网安备 33010602011771号