spark学习进度27(行政区信息、会话统计)
需求介绍
思路整理
-
需求
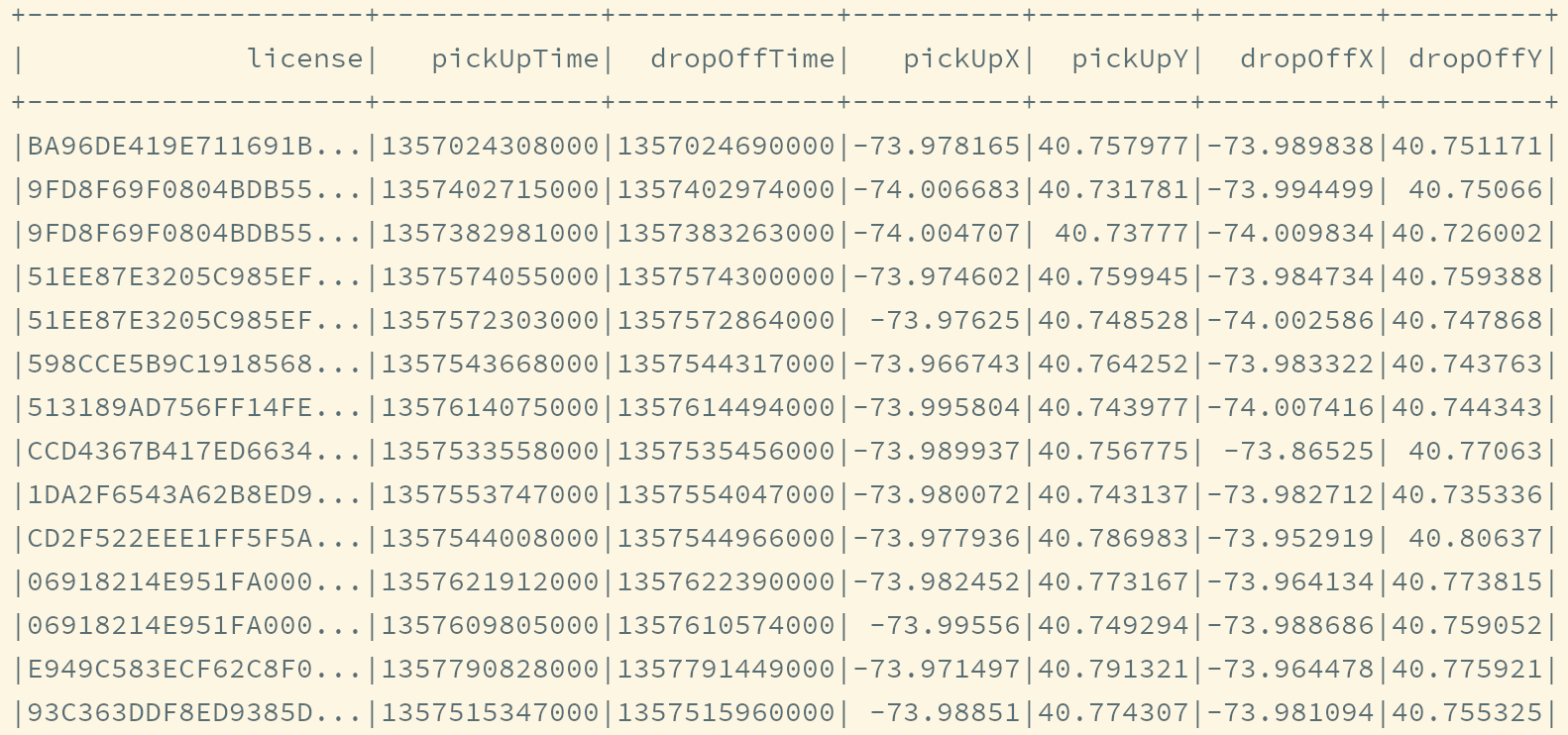
项目的任务是统计出租车在不同行政区的平均等待时间, 所以源数据集和经过计算希望得到的新数据集大致如下
-
源数据集
-
目标数据集

-
-
目标数据集分析
目标数据集中有三列,
borough,avg(seconds),stddev_samp(seconds)-
borough表示目的地行政区的名称 -
avg(seconds)和stddev_samp(seconds)是seconds的聚合,seconds是下车时间和下一次上车时间之间的差值, 代表等待时间
所以有两列数据是现在数据集中没有
-
borough要根据数据集中的经纬度, 求出其行政区的名字 -
seconds要根据数据集中上下车时间, 求出差值
-
-
步骤
-
求出
borough-
读取行政区位置信息
-
搜索每一条数据的下车经纬度所在的行政区
-
在数据集中添加行政区列
-
-
求出
seconds -
根据
borough计算平均等待时间, 是一个聚合操作
GeoJSON 是什么
-
定义
-
GeoJSON是一种基于JSON的开源标准格式, 用来表示地理位置信息 -
其中定了很多对象, 表示不同的地址位置单位
-
-
如何表示地理位置
类型 例子 点

{ "type": "Point", "coordinates": [30, 10] }线段

{ "type": "Point", "coordinates": [30, 10] }多边形
{ "type": "Point", "coordinates": [30, 10] }
{ "type": "Polygon", "coordinates": [ [[35, 10], [45, 45], [15, 40], [10, 20], [35, 10]], [[20, 30], [35, 35], [30, 20], [20, 30]] ] } -
数据集
-
行政区范围可以使用
GeoJSON中的多边形来表示 -
课程中为大家提供了一份表示了纽约的各个行政区范围的数据集, 叫做
nyc-borough-boundaries-polygon.geojson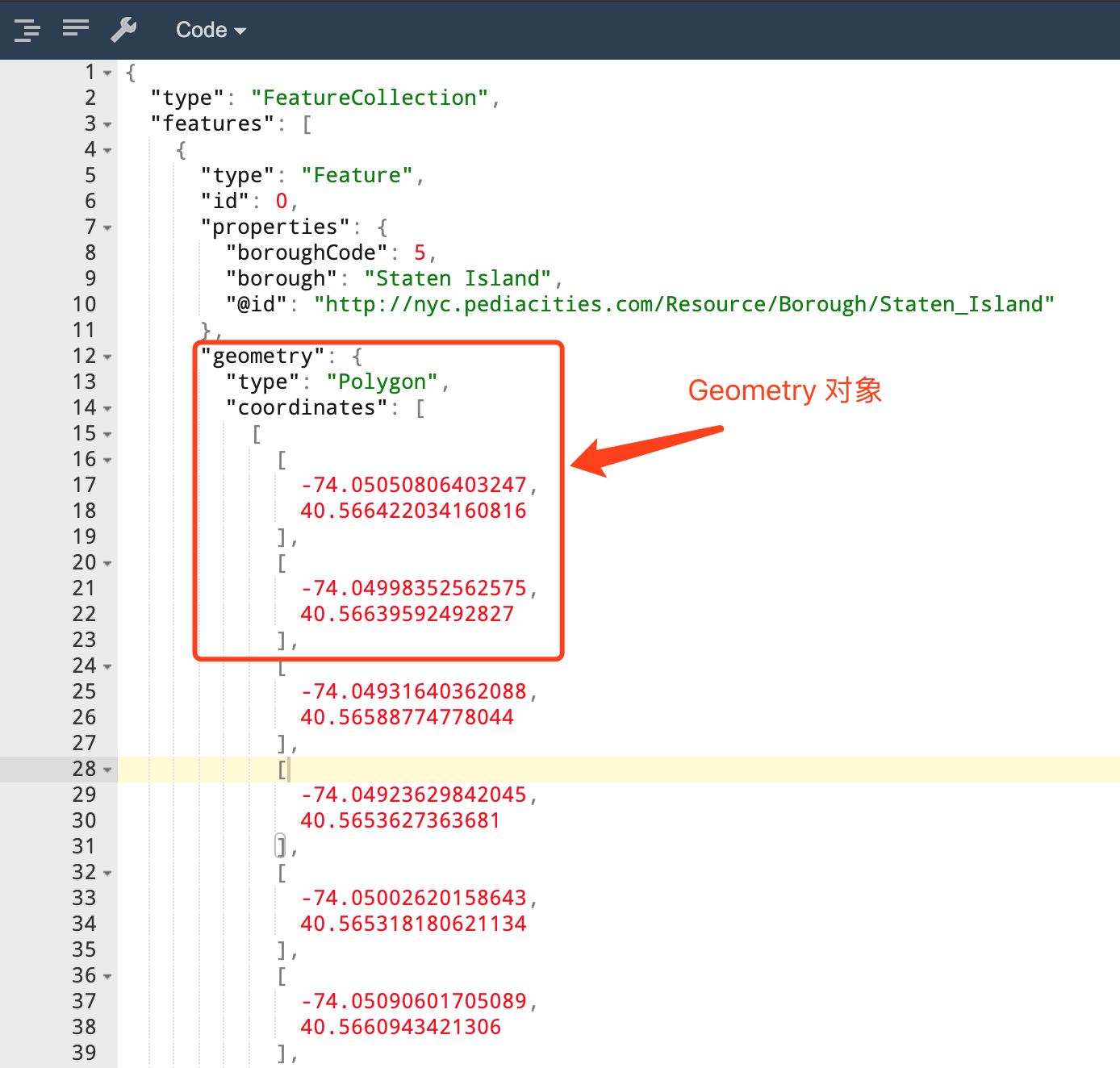
-
-
使用步骤
-
创建一个类型
Feature, 对应JSON文件中的格式 -
通过解析
JSON, 创建Feature对象 -
通过
Feature对象创建GeoJSON表示一个地理位置的Geometry对象 -
通过
Geometry对象判断一个经纬度是否在其范围内
package cn.itcast.taxi import java.text.SimpleDateFormat import java.util.Locale import java.util.concurrent.TimeUnit import com.esri.core.geometry.{GeometryEngine, Point, SpatialReference} import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession} import scala.io.Source object TaxiAnalysisRunner { def main(args: Array[String]): Unit = { // 1. 创建 SparkSession val spark = SparkSession.builder() .master("local[6]") .appName("taxi") .getOrCreate() // 2. 导入隐式转换和函数们 import spark.implicits._ import org.apache.spark.sql.functions._ // 3. 数据读取 val taxiRaw: Dataset[Row] = spark.read .option("header", value = true) .csv("dataset/half_trip.csv") // taxiRaw.show()看数据构成 // taxiRaw.printSchema()看数据结构 // 4. 转换操作 val taxiParsed: RDD[Either[Trip, (Row, Exception)]] = taxiRaw.rdd.map(safe(parse))//rdd是不考虑 里面存放的啥 // 可以通过如下方式来过滤出来所有异常的 row // taxiParsed.filter(e => e.isRight) // .map(e => e.right.get._1) val taxiGood: Dataset[Trip] = taxiParsed.map(either => either.left.get ).toDS() // 5. 绘制时长直方图 // 5.1 编写 UDF 完成时长计算, 将毫秒转为小时单位 val hours = (pickUpTime: Long, dropOffTime: Long) => { val duration = dropOffTime - pickUpTime val hours = TimeUnit.HOURS.convert(duration, TimeUnit.MILLISECONDS) hours } val hoursUDF = udf(hours) // 5.2 进行统计 // taxiGood.groupBy(hoursUDF($"pickUpTime", $"dropOffTime") as "duration") // .count() // .sort("duration") // .show() // 6. 根据直方图的显示, 查看数据分布后, 剪除反常数据 spark.udf.register("hours", hours) val taxiClean = taxiGood.where("hours(pickUpTime, dropOffTIme) BETWEEN 0 AND 3") // taxiClean.show() // 7. 增加行政区信息 // 7.1. 读取数据集 val geoJson = Source.fromFile("dataset/nyc-borough-boundaries-polygon.geojson").mkString val featureCollection = FeatureExtraction.parseJson(geoJson) // 7.2. 排序 // 后续需要得到每一个出租车在哪个行政区, 拿到经纬度, 遍历 features 搜索其所在的行政区 // 在搜索的过程中, 行政区越大命中的几率就越高, 所以把大的行政区放在前面, 更容易命中, 减少遍历次数 val sortedFeatures = featureCollection.features.sortBy(feature => { (feature.properties("boroughCode"), - feature.getGeometry().calculateArea2D()) }) // 7.3. 广播 val featuresBC = spark.sparkContext.broadcast(sortedFeatures) // 7.4. UDF创建, 完成功能 val boroughLookUp = (x: Double, y: Double) => { // 7.4.1. 搜索经纬度所在的行政区 val featureHit: Option[Feature] = featuresBC.value.find(feature => { GeometryEngine.contains(feature.getGeometry(), new Point(x, y), SpatialReference.create(4326)) }) // 7.4.2. 转为行政区信息 val borough = featureHit.map(feature => feature.properties("borough")).getOrElse("NA") borough } // 7.5. 统计信息 // val boroughUDF = udf(boroughLookUp) // taxiClean.groupBy(boroughUDF('dropOffX, 'dropOffY)) // .count() // .show() // 8.1. 过滤没有经纬度的数据 // 8.2. 会话分析 val sessions = taxiClean.where("dropOffX != 0 and dropOffY != 0 and pickUpX != 0 and pickUpY != 0") .repartition('license) .sortWithinPartitions('license, 'pickUpTime) // 8.3. 求得时间差 def boroughDuration(t1: Trip, t2: Trip): (String, Long) = { val borough = boroughLookUp(t1.dropOffX, t1.dropOffY) val duration = (t2.pickUpTime - t1.dropOffTime) / 1000 (borough, duration) } val boroughtDuration = sessions.mapPartitions(trips => { val viter = trips.sliding(2) .filter(_.size == 2) .filter(p => p.head.license == p.last.license) viter.map(p => boroughDuration(p.head, p.last)) }).toDF("borough", "seconds") boroughtDuration.where("seconds > 0") .groupBy("borough") .agg(avg('seconds), stddev('seconds)) .show() } /** * 作用就是封装 parse 方法, 捕获异常 */ //p是参数R是返回值 def safe[P, R](f: P => R): P => Either[R, (P, Exception)] = { new Function[P, Either[R, (P, Exception)]] with Serializable { override def apply(param: P): Either[R, (P, Exception)] = { try { Left(f(param)) } catch { case e: Exception => Right((param, e)) } } } } /** * Row -> Trip */ def parse(row: Row): Trip = { val richRow = new RichRow(row) val license = richRow.getAs[String]("hack_license").orNull val pickUpTime = parseTime(richRow, "pickup_datetime") val dropOffTime = parseTime(richRow, "dropoff_datetime") val pickUpX = parseLocation(richRow, "pickup_longitude") val pickUpY = parseLocation(richRow, "pickup_latitude") val dropOffX = parseLocation(richRow, "dropoff_longitude") val dropOffY = parseLocation(richRow, "dropoff_latitude") Trip(license, pickUpTime, dropOffTime, pickUpX, pickUpY, dropOffX, dropOffY) } def parseTime(row: RichRow, field: String): Long = { // 1. 表示出来时间类型的格式 SimpleDateFormat val pattern = "yyyy-MM-dd HH:mm:ss" val formatter = new SimpleDateFormat(pattern, Locale.ENGLISH) // 2. 执行转换, 获取 Date 对象, getTime 获取时间戳 val time: Option[String] = row.getAs[String](field) val timeOption: Option[Long] = time.map(time => formatter.parse(time).getTime ) timeOption.getOrElse(0L) } def parseLocation(row: RichRow, field: String): Double = { // 1. 获取数据 val location = row.getAs[String](field) // 2. 转换数据 val locationOption = location.map( loc => loc.toDouble ) locationOption.getOrElse(0.0D)//为空处理 } } /** * DataFrame 中的 Row 的包装类型, 主要为了包装 getAs 方法 * @param row */ class RichRow(row: Row) { /** * 为了返回 Option 提醒外面处理空值, 提供处理方式 */ def getAs[T](field: String): Option[T] = { // 1. 判断 row.getAs 是否为空, row 中 对应的 field 是否为空 if (row.isNullAt(row.fieldIndex(field))) {//参数相当于下标 // 2. null -> 返回 None None } else { // 3. not null -> 返回 Some Some(row.getAs[T](field)) } } } case class Trip( license: String, pickUpTime: Long, dropOffTime: Long, pickUpX: Double, pickUpY: Double, dropOffX: Double, dropOffY: Double )
会话统计
- 目标和步骤
- 会话统计的概念
-
-
需求分析
-
需求
统计每个行政区的平均等客时间
-
需求可以拆分为如下几个步骤
-
按照行政区分组
-
在每一个行政区中, 找到同一个出租车司机的先后两次订单, 本质就是再次针对司机的证件号再次分组
-
求出这两次订单的下车时间和上车时间只差, 便是等待客人的时间
-
针对一个行政区, 求得这个时间的平均数
-
-
问题: 分组效率太低
分组的效率相对较低
-
分组是
Shuffle -
两次分组, 包括后续的计算, 相对比较复杂
-
-
解决方案: 分区后在分区中排序
-
按照
License重新分区, 如此一来, 所有相同的司机的数据就会在同一个分区中 -
计算分区中连续两条数据的时间差
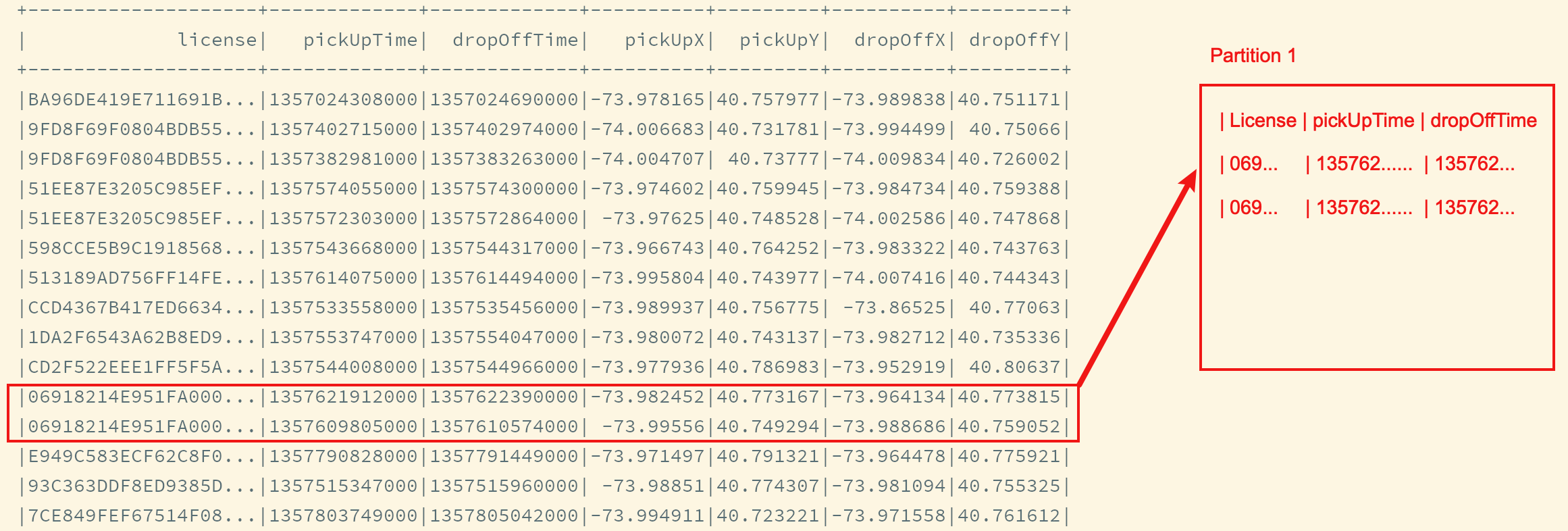
上述的计算存在一个问题, 一个分组会有多个司机的数据, 如何划分每个司机的数据边界? 其实可以先过滤一下, 计算时只保留同一个司机的数据 -
-
无论是刚才的多次分组, 还是后续的分区, 都是要找到每个司机的会话, 通过会话来完成功能, 也叫做会话分析
-
-
- 功能实现
- 总结
-
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号