spark学习进度22(Scala编程初级实践-2)
spark-shell 交互式编程:
请到本教程官网的“下载专区”的“数据集”中下载 chapter5-data1.txt,该数据集包含 了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80 Tom,Algorithm,50 Tom,DataStructure,60 Jim,DataBase,90 Jim,Algorithm,60 Jim,DataStructure,80
请根据给定的实验数据,在 spark-shell 中通过编程来计算以下内容:

(1)该系总共有多少学生;
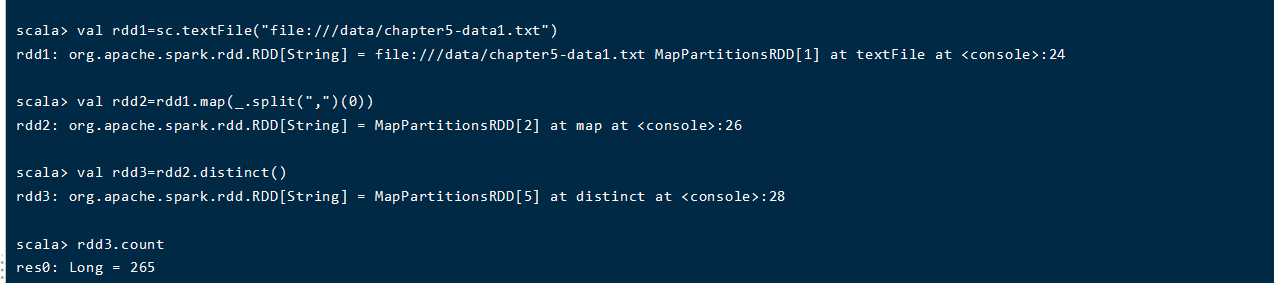
(2)该系共开设来多少门课程;
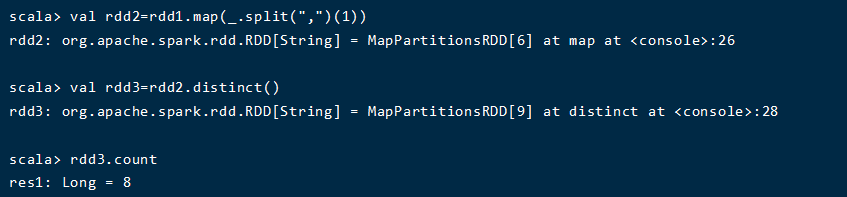
(3)Tom 同学的总成绩平均分是多少;


(4)求每名同学的选修的课程门数;

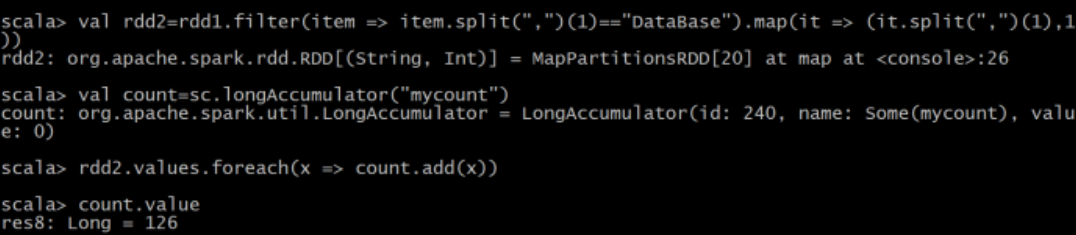
(5)该系 DataBase 课程共有多少人选修;

(6)各门课程的平均分是多少;

(7)使用累加器计算共有多少人选了 DataBase 这门课。
编写独立应用程序实现数据去重
对于两个输入文件 A 和 B,编写 Spark 独立应用程序,对两个文件进行合并,并剔除其 中重复的内容,得到一个新文件 C。下面是输入文件和输出文件的一个样例,供参考。
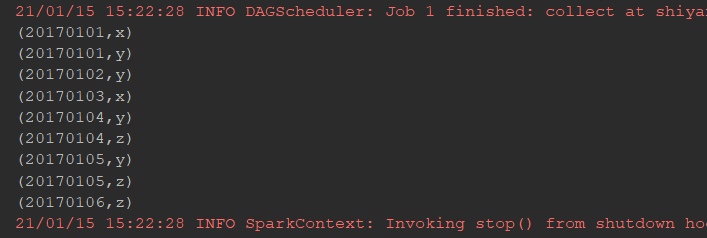
输入文件 A 的样例如下: 20170101 x 20170102 y 20170103 x 20170104 y 20170105 z 20170106 z 输入文件 B 的样例如下: 20170101 y 20170102 y 20170103 x 20170104 z 20170105 y 根据输入的文件 A 和 B 合并得到的输出文件 C 的样例如下: 20170101 x 20170101 y 20170102 y 20170103 x 20170104 y 20170104 z 20170105 y 20170105 z 20170106 z
package cn.itcast.spark.SY4 import java.io.{BufferedWriter, FileOutputStream, OutputStreamWriter} import org.apache.spark.rdd.RDD import org.apache.spark.sql.catalyst.InternalRow import org.apache.spark.sql.catalyst.encoders.RowEncoder import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession} import org.apache.spark.{SparkConf, SparkContext, sql} import org.junit.Test /** * @Author 带上我快跑 * @Data 2021/1/15 14:12 * @菩-萨-说-我-写-的-都-对@ */ class shiyan { @Test def test(): Unit ={ val conf=new SparkConf().setMaster("local[6]").setAppName("xlf_union") val sc=new SparkContext(conf) val ra=sc.textFile("dataset/a.txt") val rb=sc.textFile("dataset/b.txt") val rc=ra.union(rb) .distinct() .map(item => (item.split(" ")(0),item.split(" ")(1))) .sortBy(item =>(item._1,item._2)) .collect() val file = "dataset/c.txt" val writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file))) for(x<- rc) { println(x) writer.write(x+"\n") } writer.close() } }
编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生 名字,第二个是学生的成绩;编写 Spark 独立应用程序求出所有学生的平均成绩,并输出到 一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
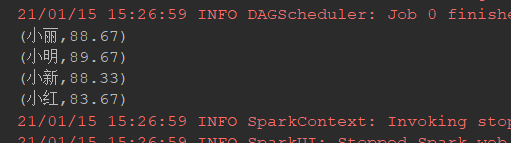
Algorithm 成绩: 小明 92 小红 87 小新 82 小丽 90 Database 成绩: 小明 95 小红 81 小新 89 小丽 85 Python 成绩: 小明 82 小红 83 小新 94 小丽 91 平均成绩如下: (小红,83.67) (小新,88.33) (小明,89.67) (小丽,88.67)
package cn.itcast.spark.SY4 import java.io.{BufferedWriter, FileOutputStream, OutputStreamWriter} import org.apache.spark.rdd.RDD import org.apache.spark.sql.catalyst.InternalRow import org.apache.spark.sql.catalyst.encoders.RowEncoder import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession} import org.apache.spark.{SparkConf, SparkContext, sql} import org.junit.Test /** * @Author 带上我快跑 * @Data 2021/1/15 15:23 * @菩-萨-说-我-写-的-都-对@ */ class shiyan2 { @Test def test2(): Unit ={ val conf=new SparkConf().setMaster("local[6]").setAppName("xlf_avg") val sc=new SparkContext(conf) val ra=sc.textFile("dataset/Algorithm.txt") val rb=sc.textFile("dataset/Database.txt") val rc=sc.textFile("dataset/Python.txt") val out=ra.union(rb) .union(rc) .map(item => (item.split(" ")(0),item.split(" ")(1).toDouble)) .mapValues(v => (v,1)) .reduceByKey( (x,y) =>(x._1+y._1,x._2+y._2) ) .mapValues(v => (v._1/v._2).formatted("%.2f") ) .collect() val file = "dataset/out.txt" val writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file))) for(x<- out) { println(x) writer.write(x+"\n") } writer.close() } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号