spark学习进度09(RDD算子-action-针对KV类型的数据-针对数字类型的数据)
(所有转换操作的算子都是惰性的,在执行的时候。并不会真的去调度运行,求得结果。而是是生成对应的RDD,只有在Action操作的时候,才会真的运行求得结果)
一、Action操作:
1、collect(并不能适应所有的场景)
2、reduce


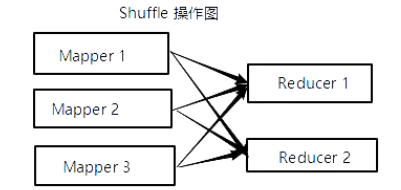

作用
-
对整个结果集规约, 最终生成一条数据, 是整个数据集的汇总
调用
-
reduce( (currValue[T], agg[T]) ⇒ T )
注意点
-
reduce 和 reduceByKey 是完全不同的, reduce 是一个 action, 并不是 Shuffled 操作
-
本质上 reduce 就是现在每个 partition 上求值, 最终把每个 partition 的结果再汇总
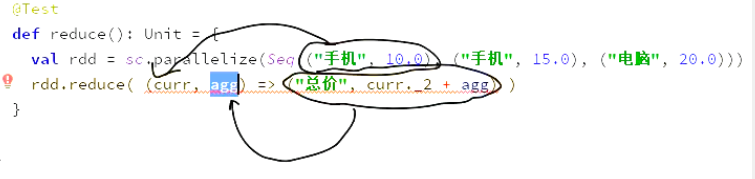
@Test def reduce():Unit={ //注意点。函数中传入的curr不是value而是整条数据。reduce整体上的结果只有一个 //生成的结果类型是(“商品”,price) val rdd=sc.parallelize(Seq(("手机",10.0),("手机",15.0),("电脑",20.0))) val rdd2=rdd.reduce((curr,agg)=>("总价",curr._2+agg._2)) println(rdd2) }

3、foreach
@Test def foreach():Unit={ //注意点。itemd的收集是一个异步的过程,并行执行。所以结果可能不是按顺序来的 val rdd=sc.parallelize(Seq(1,2,3)) val rdd2=rdd.foreach(item=>println(item)) }

4、count和countByKey(两个都是求数量的)
@Test def count():Unit={ //注意点:count和countByKey的结果相聚很远, //每次调用Action都会生成一个job,job会运行获取结果 //所以在两个job之间有大量的log打出,其实就是在启动job //countByKey的运行结果是Map(key,value的count) //如果要解决数据倾斜的问题,可以通过countByKey查看key对应的数据总数,从而解决倾斜 val rdd1=sc.parallelize(Seq(("a",1),("b",2),("c",3),("a",5))) println(rdd1.count()) println(rdd1.countByKey() ) }


5、first(只获取第一个元素)。take(获取前几个元素)。takesample(直接拿到结果和之前的sample类似)
@Test def take():Unit={ //注意点:take按顺序获取。takesample是采样获取 //first:一般情况下collect会从所有的分区获取数据,相对来说比较慢 //但是first只会获取第一个元素。处理第一个分区,无需处理所有的数据比较快 val rdd1=sc.parallelize(Seq(1,2,3,4,5,6,7,8)) rdd1.take(3).foreach(item=>println(item)) println(rdd1.first()) rdd1.takeSample(withReplacement = true,num=3).foreach(item=>println(item))//为true表示又放回的 }



小总结:
1、算子功能上进行分类:
1.1转换算子transformation
1.2动作算子Action
2、RDD中存放的数据类型:
2.1基本类型String对象
2.2KV类型
2.3数字类型
二、针对KV类型的数据,Spark提供了什么操作:
键值型数据本质上就是一个二元元组, 键值对类型的 RDD 表示为 RDD[(K, V)]
RDD 对键值对的额外支持是通过隐式支持来完成的, 一个 RDD[(K, V)], 可以被隐式转换为一个 PairRDDFunctions 对象, 从而调用其中的方法.

- 既然对键值对的支持是通过
PairRDDFunctions提供的, 那么从PairRDDFunctions中就可以看到这些支持有什么
| 类别 | 算子 |
|---|---|
|
聚合操作 |
|
|
|
|
|
|
|
|
分组操作 |
|
|
|
|
|
连接操作 |
|
|
|
|
|
|
|
|
排序操作 |
|
|
|
|
|
Action |
|
|
|
|
|
|
三、针对数字型的数据、spark提供了什么操作:
对于数字型数据的额外支持基本上都是 Action 操作, 而不是转换操作
| 算子 | 含义 |
|---|---|
|
|
个数 |
|
|
均值 |
|
|
求和 |
|
|
最大值 |
|
|
最小值 |
|
|
方差 |
|
|
从采样中计算方差 |
|
|
标准差 |
|
|
采样的标准差 |

@Test def numberic():Unit={ val rdd1=sc.parallelize(Seq(1,2,3,4,5,6,7,8)) println(rdd1.max())//大 println(rdd1.min())//小 println(rdd1.mean())//均值 println(rdd1.sum())//求和 }





 浙公网安备 33010602011771号
浙公网安备 33010602011771号