spark学习进度08(RDD算子-转换)

一、转换操作:

1、mapPartitions的相关操作
@Test def mapPartitions():Unit={ //1、数据生成 //2、算子使用 //3、获取结果 sc.parallelize(Seq(1,2,3,4,5,6),2) .mapPartitions(iter=>{ iter.foreach(item=>println(item)) iter })//传递的函数要是迭代器(interator) .collect() }

@Test def mapPartitions2():Unit={ //1、数据生成 //2、算子使用 //3、获取结果 sc.parallelize(Seq(1,2,3,4,5,6),2) .mapPartitions(iter=>{ //遍历interator中的每一条数据进行转换 //转换完以后返回iter //iter是scala中的类型 iter.map(item=>item*10) })//传递的函数要是迭代器(interator) .collect() .foreach(item=>println(item)) }

2、mapPartitionsWithIndex的相关操作
@Test def mapPartitionsWithIndex():Unit={ sc.parallelize(Seq(1,2,3,4,5,6),2) .mapPartitionsWithIndex( (index,iter)=>{//其中index表示的分区 println("index: "+index) iter.foreach(item=>println(item)) iter } ) .collect() }

3、总结上边两个:
3.1map和mappartitions的区别
##mapPartitions和map算子是一样的,只不过map是针对每一条数据进行转换,mappartitions是针对一整个分区的数据进行转换。
所以map的func参数是单条数据,mappartitions的func参数是一个集合,func的参数是一个集合,一个分区整个的所有数据,
##map的func返回值也是单条数据,mappartitions的func的返回值是一个集合
3.2mappartitions和mappartitionsindex的区别
区别是mappartitionsindex中的func中多了一个参数是分区号
4、filter进行数据的过滤
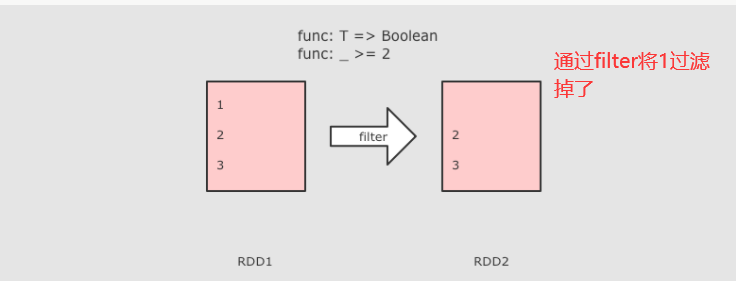
@Test def filter():Unit={ //1、定义集合 //2、过滤数据 //3、收集结果 sc.parallelize(Seq(1,2,3,4,5,6,7,8,9)) .filter(item=>item%2==0)//只保留偶数 .collect() .foreach(item=>println(item)) }

5、sample(不需要接收任何函数)(是随机的。主要用于随机采样)

@Test def sample():Unit={ //1、定义集合 //2、过滤数据 //3、收集结果 val rdd1=sc.parallelize(Seq(1,2,3,4,5,6,7,8,9,10)) val rdd2=rdd1.sample(false,0.6)//第二个参数采用的比例。第一个参数是是否有放回 val rdd3=rdd2.collect() rdd3.foreach(item=>println(item)) }

6、mapvalues(只能作用于k-v和map类似其只转换map-value中的value)
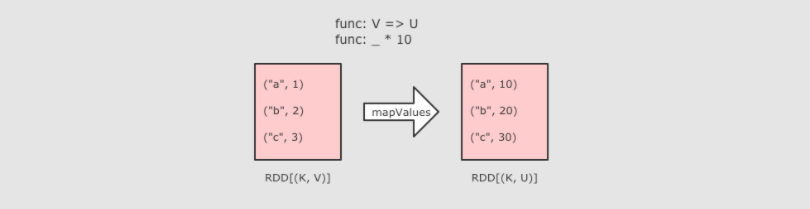
@Test def mapValues():Unit={ //1、定义集合 //2、过滤数据 //3、收集结果 sc.parallelize(Seq(("a",1),("b",2),("c",3))) .mapValues(item=>item*10) .collect() .foreach(println(_)) }

7、itersection-union-

7.1交集itersection
@Test def intersection():Unit={//交集 val rdd1=sc.parallelize(Seq(1,2,3,4,5)) val rdd2=sc.parallelize(Seq(3,4,5,6,7)) rdd1.intersection(rdd2) .collect() .foreach(println(_)) }

7.2并集union(可以存在重复)
@Test def union():Unit={//并集 val rdd1=sc.parallelize(Seq(1,2,3,4,5)) val rdd2=sc.parallelize(Seq(3,4,5,6,7)) rdd1.union(rdd2) .collect() .foreach(println(_)) }

7.3差集subtract
@Test def subtract():Unit={//差集 val rdd1=sc.parallelize(Seq(1,2,3,4,5)) val rdd2=sc.parallelize(Seq(3,4,5,6,7)) rdd1.subtract(rdd2) .collect() .foreach(println(_)) }

8、groupByKey(先按照key进行分组之后把每一组进行reduce)(不需要传入func函数)
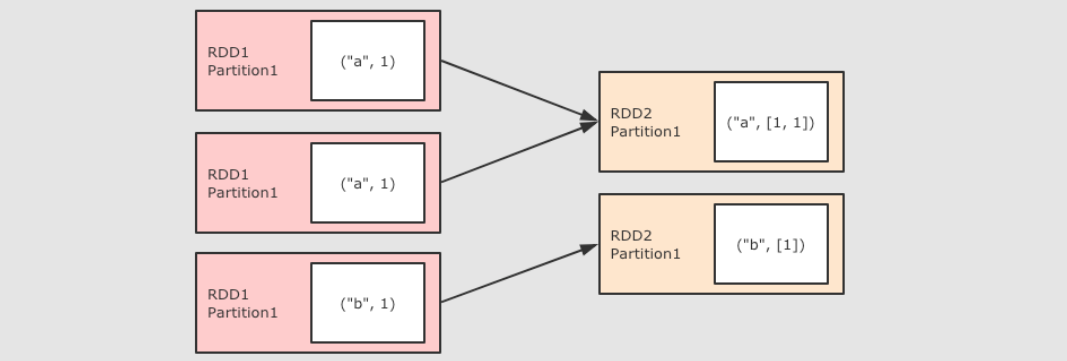
@Test def groupByKey():Unit={ sc.parallelize(Seq(("a",1),("a",2),("c",3))) .groupByKey() .collect() .foreach(println(_)) }

9、combinByKey(groupByKey和reduceByKey都是以他为底层)
作用
-
对数据集按照 Key 进行聚合
调用
-
combineByKey(createCombiner, mergeValue, mergeCombiners, [partitioner], [mapSideCombiner], [serializer])
参数
-
createCombiner将 Value 进行初步转换 -
mergeValue在每个分区把上一步转换的结果聚合 -
mergeCombiners在所有分区上把每个分区的聚合结果聚合 -
partitioner可选, 分区函数 -
mapSideCombiner可选, 是否在 Map 端 Combine -
serializer序列化器
注意点
-
combineByKey的要点就是三个函数的意义要理解 -
groupByKey,reduceByKey的底层都是combineByKey
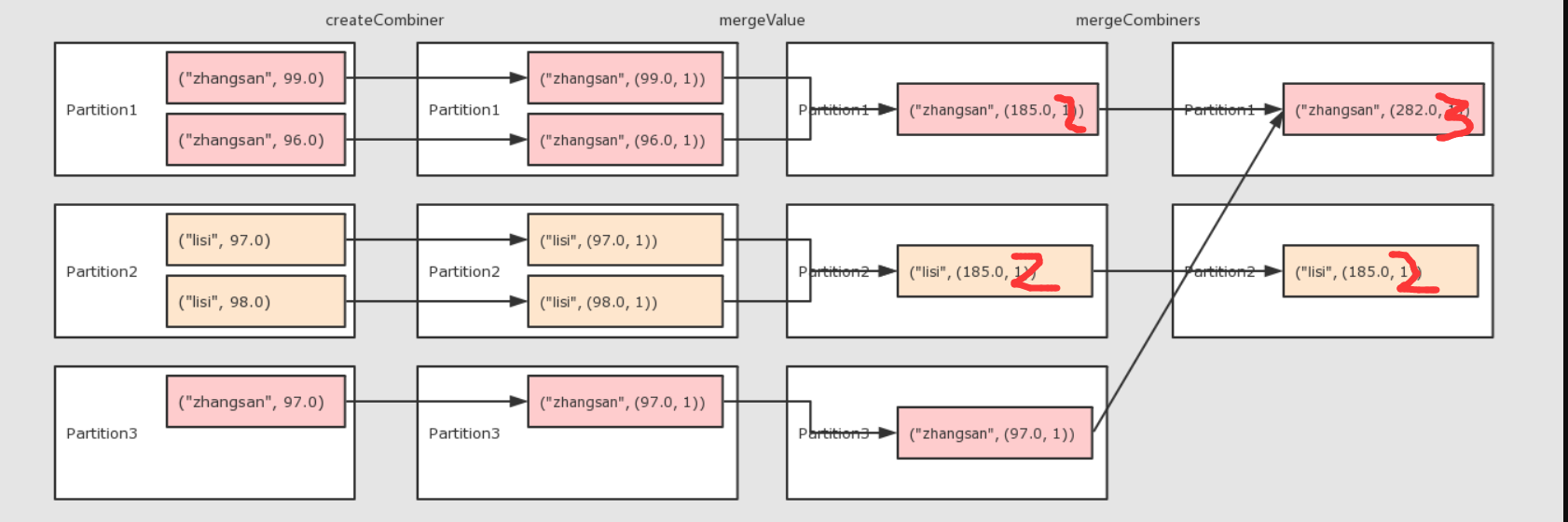
@Test def combinByKey():Unit={ //1、准备集合 val rdd: RDD[(String, Double)] = sc.parallelize(Seq( ("zhangsan", 99.0), ("zhangsan", 96.0), ("lisi", 97.0), ("lisi", 98.0), ("zhangsan", 97.0)) ) //2、算子操作 //2-1createcombiner转换数据 //2-2mergevalue分区上的集合 //2-3mergecombiner把所有分区上的结果再次聚合,生成最终的结果 val comBineResult=rdd.combineByKey( createCombiner = (curr: Double) =>(curr,1),//接收函数 mergeValue = (curr:(Double,Int),nextValue:Double)=>(curr._1+nextValue,curr._2+1), mergeCombiners = (curr:(Double,Int),agg:(Double,Int))=>(curr._1+agg._1,curr._2+agg._2) ) //现在的数据是这样的(“name”,(分数,次数)) //获得结果将他打印出来 comBineResult.map(item=>(item._1,item._2._1/item._2._2)).collect().foreach(println(_)) }

得到的结论:combinByKey接收三个函数。
第一个:转换函数,初始函数,作用于第一条数据,用于开启整个计算
第二个:在分区上进行计算聚合
第三个:把所有分区的聚合结果聚合为最终的结果
10、foldByKey(与reduceByKey的区别是。他有一个初始值,reduceByKey的初始值是0)
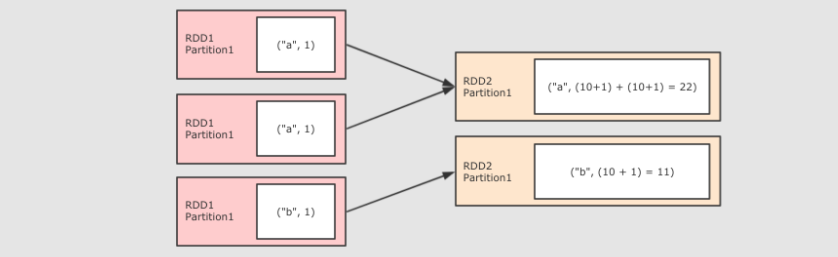

@Test def flodByKey():Unit={ sc.parallelize(Seq(("a", 1), ("a", 1), ("b", 1))) .foldByKey(zeroValue = 10)( (curr, agg) => curr + agg )//第一个函数传入初始值。第二个传入聚合的规则 .collect() .foreach(println(_)) }

11、aggregateByKey(这个是foldByKey的底层)
- 作用
-
-
聚合所有 Key 相同的 Value, 换句话说, 按照 Key 聚合 Value
-
- 调用
-
-
rdd.aggregateByKey(zeroValue)(seqOp, combOp)
-
- 参数
-
-
zeroValue初始值 -
seqOp转换每一个值的函数 -
comboOp将转换过的值聚合的函数
-
注意点 * 为什么需要两个函数?
aggregateByKey 运行将一个`RDD[(K, V)]聚合为`RDD[(K, U)], 如果要做到这件事的话, 就需要先对数据做一次转换, 将每条数据从`V`转为`U`, `seqOp`就是干这件事的 ** 当`seqOp`的事情结束以后, `comboOp`把其结果聚合
-
和 reduceByKey 的区别::
-
aggregateByKey 最终聚合结果的类型和传入的初始值类型保持一致
-
reduceByKey 在集合中选取第一个值作为初始值, 并且聚合过的数据类型不能改变
-
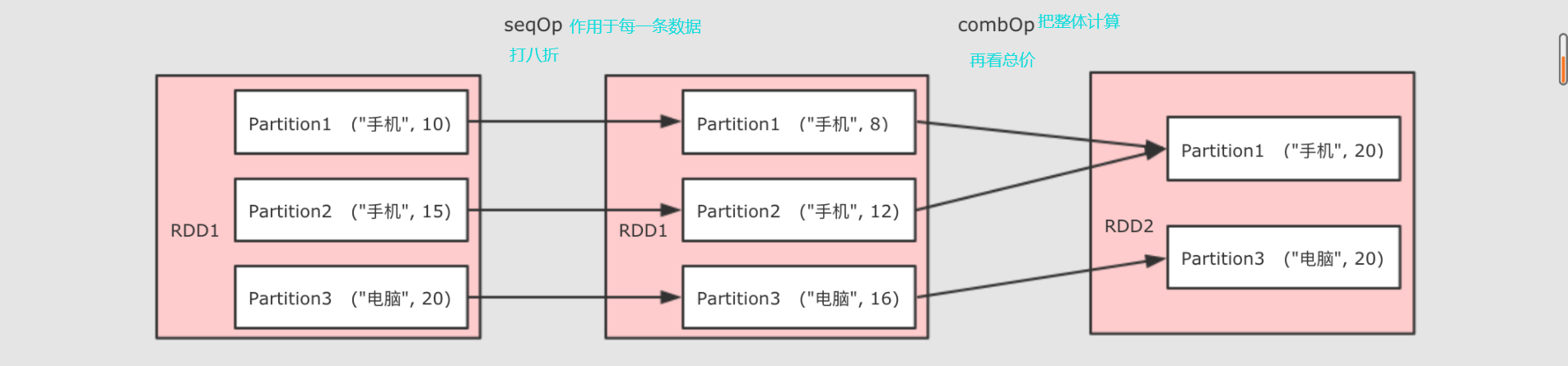
@Test def aggregateByKey():Unit={//东西打八折 val rdd = sc.parallelize(Seq(("手机", 10.0), ("手机", 15.0), ("电脑", 20.0))) val result = rdd.aggregateByKey(0.8)( seqOp = (zero, price) => price * zero, combOp = (curr, agg) => curr + agg ) .collect() .foreach(println(_)) }

12、join
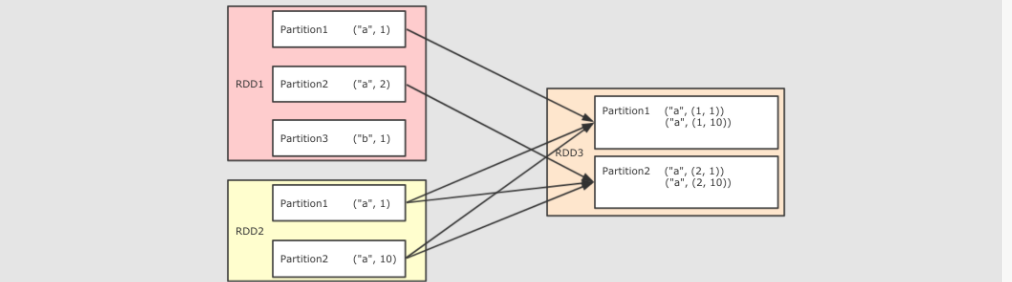
@Test def join():Unit={ val rdd1 = sc.parallelize(Seq(("a", 1), ("a", 2), ("b", 1))) val rdd2 = sc.parallelize(Seq(("a", 10), ("a", 11), ("a", 12))) rdd1.join(rdd2).collect().foreach(println(_)) }

13、sortBy和sortByKey(两个与排序有关的算子)
作用
-
排序相关相关的算子有两个, 一个是`sortBy`, 另外一个是`sortByKey`
调用
sortBy(func, ascending, numPartitions)
参数
-
`func`通过这个函数返回要排序的字段
-
`ascending`是否升序
-
`numPartitions`分区数
注意点
-
普通的 RDD 没有`sortByKey`, 只有 Key-Value 的 RDD 才有
-
`sortBy`可以指定按照哪个字段来排序, `sortByKey`直接按照 Key 来排序
@Test def sort():Unit={ val rdd1 = sc.parallelize(Seq(1,2,3,4,5,6)) val rdd2 = sc.parallelize(Seq(("a", 3), ("b", 2), ("c", 1))) rdd1.sortBy(item=>item).collect().foreach(println(_)) rdd2.sortBy(item=>item._2).collect().foreach(println(_)) rdd2.sortByKey().collect().foreach(println(_)) }



总结:sortBy可以作用于任何类型的数据的RDD,
sortByKey只有KV类型的数据的RDD中才有
sortBy可以按照任何地方来排序,
sortByKey只能按照Key排序
sortByKey写法简单,不用编写函数了
14、repartition和coalesce重分区(都是改变分区数)
作用
-
一般涉及到分区操作的算子常见的有两个,
repartitioin和coalesce, 两个算子都可以调大或者调小分区数量
调用
-
repartitioin(numPartitions) -
coalesce(numPartitions, shuffle)
参数
-
numPartitions新的分区数 -
shuffle是否 shuffle, 如果新的分区数量比原分区数大, 必须 Shuffled, 否则重分区无效
注意点
-
repartition和coalesce的不同就在于coalesce可以控制是否 Shuffle -
repartition是一个 Shuffled 操作
@Test def partitioning():Unit={//改变分区数 val rdd = sc.parallelize(Seq(1,2,3,4,5),2) println(rdd.repartition(5).partitions.size)//repartition可大 println(rdd.repartition(1).partitions.size)//repartition可小 println(rdd.coalesce(1).partitions.size)//coalesce可小但是不可大(变大之后还是原来的) println(rdd.coalesce(5,shuffle = true).partitions.size)//设置shuffle = true之后coalesce可大 }

大总结:
主要分为几类:转换:map、mapPatrtitions、mapValues
过滤:filiter、sample
集合操作:intersection、union、subtract
聚合操作:reduceByKey、groupByKey、combinByKey、foldByKey、aggregateBuKey、sortBy、sortByKey
重分区:reparititions、coalesce

 浙公网安备 33010602011771号
浙公网安备 33010602011771号