HashSet、LinkedHashSet、LinkedHashMap的简单研究
一、关于HashSet的一些结论
HashSet在它的构造函数中,封装的是HashMap,因此理解了HashMap,HashSet就显得非常非常简单。怪不得好多大佬在分析结合框架源码的时候,都没有关于HashSet的文章,自己去看了源码才知道原因。因此HashSet使用的也是“数组+链表”的数据结构,书上称之为“链表散列”,真是太拗口了。特点不用说了,参照HashMap说。估计面试的时候,面试官也不会问HashSet,应该会直接问HashMap。
//底层用于存放数据的map的引用,在HashMap的构造函数中被初始化
private transient HashMap<E,Object> map;
//HashMap是一组键值对,HashSet的元素视为“key”,它的值恒为一个object对象
private static final Object PRESENT = new Object();
//空参构造函数,底层创建一个HashMap对象
public HashSet() {
map = new HashMap<>();
}
//使用指定的初始容量和加载因子来构建HashMap对象
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
//使用指定的初始容量,使用默认的加载因子来构建HashMap对象
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
二、关于LinkedHashMap的一些结论
LinkedHashMap的内部类继承了HashMap的内部类。这些内部类统统可以视为节点。也就是说LinkedHashMap的节点扩展了HashMap的节点。LinkedHashMap内部的这个新节点,新增了两个引用,before指向前一个新节点,after指向后一个新节点。另外,在初始化HashMap的时候,曾经有一个init()方法。这个时候就派上用场了。LinkedHashMap重写了init()方法,在init()方法中创建一个头节点header。第一次添加新元素的时候,调用下面的addBefore()方法,将其添加到这个这个头节点的后面。添加第二个元素的时候,放到第一个元素的后面,并使用addBefore()方法调整指针。如此类推,形成了一个双向循环链表。
每个节点的before和after引用在逻辑上也形成了一个双向循环链表。因此,在迭代LinkedHashMap的时候,才能按照元素的插入顺序进行迭代。双向循环链表的逻辑示意图如图所示,图片来源:点击打开链接
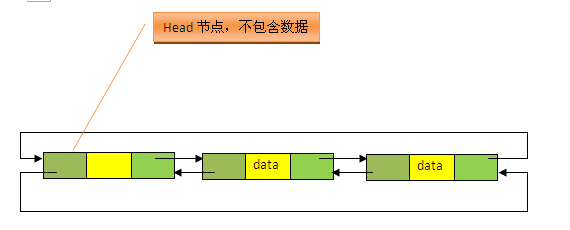
//LinkedHashMap的entry继承自HashMap的Entry。
private static class Entry<K,V> extends HashMap.Entry<K,V> {
//多出的这两个引用,分别指向的是 前一个节点 和 后一个节点
Entry<K,V> before, after;
//使用的是HashMap的Entry构造
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
//此方法在插入新节点以后调用,一般把头节点 传递给这个 existingEntry
//这个方法的意思是这样的,元素被插入到最后一个位置,需要调整一些指针的指向。
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry; //把当前插入节点的后继 指向头结点
before = existingEntry.before; //把当前插入节点的前驱指向 头结点的前一个,就是曾经的末尾节点
before.after = this; //把曾经的末尾节点的后继 是 当前插入的节点
after.before = this; //把头结点 的前驱 指向当前节点。当前节点就是末尾节点了
}
//省略部分代码
}LinkedHashMap继承了父类HashMap的添加元素put方法。并且,LinkedHsahMap还重写了向哈希表中添加元素的方法。主要被修改的代码如下:
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
//调用新节点的方法。这个方法的作用就是将e放在双向循环链表的末尾,需要将一些指向进行修改的操作。
e.addBefore(header);
size++;
}
三、关于LinkedHashSet的一些结论
LinkedHashSet继承自HashSet,HashSet封装的是HashMap。因为。因此LinkedHashSet的底层数据结构是“数组+链表”。点开LinkedHashSet的构造函数,调用的是HashSet的构造函数。LinedHashSet希望是有序的,因此在父类 HashSet 中,专为 LinkedHashSet 提供的构造方法如下,该方法为包访问权限,并未对外公开。
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);//专门为LinkedHashSet创建了一个有序的LinkedHashMap
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号