
从头开始学MySQL--------查询(1)
7.2.1 查询所有字段
使用通配符 * 来查询所有数据
SELECT * FROM fruits;优点:当不知道表的列名称的时候,可以节约时间,快速知道列的名称。
缺点:获取不需要的数据可能会降低查询的效率。而且会出现全表扫描,要谨慎使用。我同学的公司的数据库表,数据量通常都是百万级别的,用这个SQL语句出结果估计要等到太阳下山。
查询单字段 SELECT 字段 FROM 表名;
查询多字段 SELECT 字段A,字段B ....,字段N FROM 表名;
条件查询 SELECT 字段 FROM 表名 WHERE 查询条件;
7.2.4 带IN关键字的查询
使用IN将查询 满足指定范围内的条件的 记录。
SELECT
f_name
FROM
fruits
WHERE
s_id IN (101, 102)

相反,可以使用 NOT IN 来检索不在条件范围内的所有记录。
查询s_id 既不为101,也不为102的所有记录。
SELECT
f_name
FROM
fruits
WHERE
s_id NOT IN (101, 102)7.2.5 BETWEEN AND 范围查询
查询某个范围的值,包括开始值与结束值,一般用于数值型,常用于ID。
SELECT
f_name,
f_price
FROM
fruits
WHERE
f_price BETWEEN 1 AND 100
7.2.6 模糊查询 LIKE
MySQL的通配符有'%'与'_'。'%'视为任意长度的字符串。'_'视为一个字符串。
'%a'匹配以a结尾的字符串。'a%'匹配以a开头的字符串。'%a%'匹配含有字符a的字符串。
从fruits表中查询f_name字段 中含有o的记录
SELECT
f_name
FROM
fruits
WHERE
f_name LIKE '%o%'

7.2.7 空值查询
从算术运算符的章节,已经学过 SELECT A IS NULL; SELECT A IS NOT NULL; 返回的是 1或者0;
现在用于条件判断了,查询f_price 是 NULL 的所有记录。 IS NULL 与 IS NOT NULL 相反。
SELECT
f_name
FROM
fruits
WHERE
f_price IS NULL
-- f_price IS NOT NULL7.2.8 带AND的多条件查询
查询只有满足所有查询条件的记录才会被返回。AND可以连接两个甚至多个查询条件。
SELECT
*
FROM
fruits
WHERE
f_id = 'a1' AND s_id < 102;7.2.9 带OR的多条件查询
在算术运算符中。与‘AND && ’、 或‘OR ||’、非 ‘NOT !’。
使用OR操作符,表示只需要满足其中一个条件的记录即可返回。
exprA || exprB ,只要满足一个条件,返回的就是真。
s_id in (101,102) 与 s_id = 101 OR s_id = 102 效果是一样的。
OR的注意点
(1)使用IN操作符使得查询语句变得更加简洁明了,IN的速度也同样快于OR。
(2)更重要的是IN操作符可以执行更加复杂的嵌套查询。
(3)OR与AND的优先级:先做AND的操作,再连接OR
A AND B OR C A OR B AND C
等价于 (A AND B) OR C A OR (B AND C)
SELECT
*
FROM
fruits
WHERE
f_id IS NULL
OR
s_id IS NOT NULL

7.2.10 查询结果不重复(去重)
去重语法格式:SELECT DISTINCT 字段 FROM 表名 WHERE 条件;
下面的例子中,
第一条语句查询到了4条记录: 101、101、102、103
第二条语句查询到了3条记录: 101、102、103
即查询结果相同的算一条记录。
SELECT s_id FROM fruits;
SELECT DISTINCT s_id FROM fruits;再看下面的SQL
SELECT DISTINCT s_id , f_name FROM fruits;

这说明:DISTINCT控制的重复是DISTINCT后面所有字段!即查询出来的记录中的s_id、f_name必须完全一样,才能算同一条。而不是单纯的s_id相同就去重。
如果你有下面的这个SQL,查询出来的数据是
SELECT ID,NAME FROM`dept` 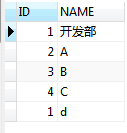
假设查出来了两条ID为1的数据,将NAME属性视为通过不同的外连接查询到的数据。
如果此时我的需求是:去掉ID重复的数据。下面这条SQL是行不通的。为什么?因为DISTINCT会将后面的所有字段去重,即不同记录中,ID与NAME属性完全一样,才能视为是相同的数据。
SELECT DISTINCT ID,NAME FROM`dept`所以, 我们需要上述的数据进行分组操作。所以,ID相同的数据,默认就展示一条了。
SELECT ID,NAME,COUNT(*) FROM`dept` GROUP BY ID 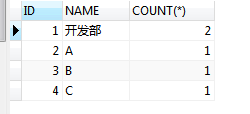
阅读更多
.

