SQL语句优化(持续更新)
前言
尽量从我们平时开发中的环境找例子。
有时候SQL语句运行的速度令我抓狂,我也迫切的想弄明白如何才能写出更高效的SQL。
1.模糊查询
使用LIKE关键字可能不会触发索引,因此,只有"%"不在第一个位置,索引才会发挥左右。
# 走全表扫描,放弃索引
SELECT [COLUMN_List] FROM TABLE WHERE [COLUMN] LIKE '%abc%'
#会使用COLUNMN 列的索引
SELECT [COLUMN_List] FROM TABLE WHERE [COLUMN] LIKE 'abc%'2. IN或者NOT IN 要慎用
就我经历过的项目而言,系统数据库中一般会有一些参数表。比如现在参数表中,订单有四种状态。
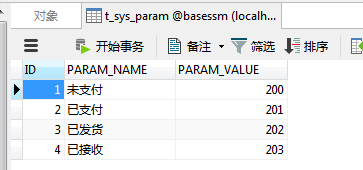
我需要查询出 不是"已接收"状态 的其它所有订单。那么我通常写的SQL是
SELECT [COLUMN_LIST] FROM T_SYS_PARAM WHERE PARAM_VALUE IN (200,201,202)但是这样的写法可能会出现全表扫描。应该优化成
SELECT [COLUMN_LIST] FROM T_SYS_PARAM WHERE PARAM_VALUE BETWEEN 200 AND 202所以,对于连续的数值,能用 between 就不要用 in 了。
3. * 禁用
使用 * 可能会查询出不需要的列,降低SQL的查询速度。
使用 * 会返回了不需要的列
SELECT * FROM T_TABLE4.使用LIMIT 1 或者 TOP 1
当知道只会查询出一条数据的时候,使用LIMIT 1 及时终止SQL的执行,可终止数据库索引继续扫描整个表或索引。
SELECT PARAM_NAME FROM t_sys_param WHERE PARAM_VALUE = '已支付' LIMIT 15.尽量不要在WHERE子句中对字段进行表达式操作
CREATE TABLE `t_sys_param` (
`ID` int(11) NOT NULL AUTO_INCREMENT,
`PARAM_NAME` varchar(10) DEFAULT NULL,
`PARAM_VALUE` int(11) DEFAULT NULL,
PRIMARY KEY (`ID`),
KEY `abc` (`PARAM_VALUE`)
) ENGINE=InnoDB AUTO_INCREMENT=2231 DEFAULT CHARSET=utf8;首先我写了一个存储过程,插入两千条数据到T_SYS_PARAM中。
DROP PROCEDURE IF EXISTS testWhile;
DELIMITER //
CREATE PROCEDURE testWhile(IN myCount INT(11),OUT result INT(11))
BEGIN
DECLARE i INT DEFAULT 0 ; -- 定义变量
WHILE i < myCount DO -- 符合条件就循环
INSERT INTO t_sys_param VALUES(NULL,i,i);
SET i = i + 1 ; -- 计数器+1
END WHILE; -- 当不满足条件,结束循环 --分号一定要加!
SET result = i; -- 将变量赋值到输出
END // ![]()
花了5秒中,生成了2000条数据,只显示了一部分。
现在查询PARAM_VALUE 除以 2 等于 50 的数据。果然扫描了2000条数据,我的妈耶。
EXPLAIN SELECT PARAM_NAME FROM t_sys_param WHERE PARAM_VALUE / 2 = 50
再测试另外一个。 只扫描了1条数据,可以,很强势。
EXPLAIN SELECT PARAM_NAME FROM t_sys_param WHERE PARAM_VALUE = 50 * 2
6.尽量不在where子句中用 != 操作符
比如说,查询某个班级的同学,条件是同学的名字不叫"大宇",首先做的就是应该先查询到这个班的所有同学的名字呢。所以,全表扫描就出现了。
7.尽量避免在 where 子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描
理由同5
