

从头开始学分库分表-------全局主键避重
一、雪花算法
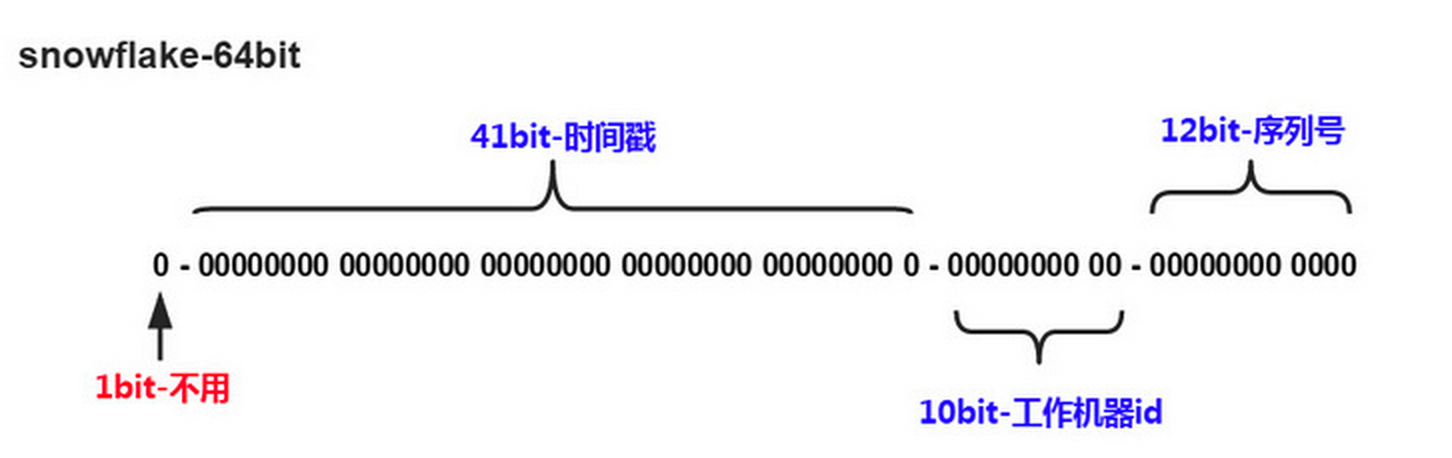
雪花算法由【符号位】 + 【时间戳】 + 【机器码】 + 【序列号】
符号位只占1位,表示正数。
时间戳占41位,毫秒级别。2^41次方,这个数字也是一个庞大的数字,保证不会重复。
机器码占10位,由硬件决定。
序列号占12位,标志生成的第多少个ID,计数用。

雪花算法的优点:
(1)雪花算法生成的ID可用使用Long类型来接收,是纯数字类型,可以做MySQL数据库表的主键。
(2)雪花算法毫秒在高位,生成的ID是递增的。
(3)不依赖第三方系统,生成ID的效率很高。
雪花算法的缺点:
(1)如果服务器时间回拨,调回到以前,理论上ID就有可能重复
(2)JS可能达不到雪花算法产生的ID的长度,需要传输的时候把Long类型的ID转成字符串。
补充:
著名的ORM框架MyBatisPlus,它的默认ID生成策略也是【雪花算法】
作者的雪花算法开源项目地址:https://gitee.com/yu120/sequence
二、UUID
UUID使用"-"符号来分割,它的结构是 8-4-4-4-12,加上4个"-",长度共36个字符。
我使用java.util.UUID.randomUUID().toString(),得到的结果:"c1ae1d86-e859-496c-a207-6785eee5312b"
UUID的优点:
(1)生成ID的性能很好。理由:很明显,直接使用了JDK自带的工具类,方便快捷。
(2)不依赖第三方系统,不需要网络传输。
UUID的缺点:
(1)32位的长度就比其它ID长,占用MySQL磁盘。
(2)UUID生成的主键不适用于数字类型的主键。
(3)UUID不安全,可能会泄露MAC地址
(4)在插入上百万级别得数据的时候,UUID耗时长,不如自增长的ID算法与雪花算法,性能直线下降。
原因是在InnoDB引擎下,UUID是无序的,所以插入的数据会引起数据位置频繁变动,影响性能。
