从头开始学JDK-------String
目录
* String #subString(int beginIndex)
* String static#join(String separator , String... elements)
* String #replaceFirst(String regex , String replacement)
* String #matches(String regex)
* String #倒序
public static boolean reverseEquals(String str) {
return Objects.equals(str, new StringBuilder(str).reverse().toString());
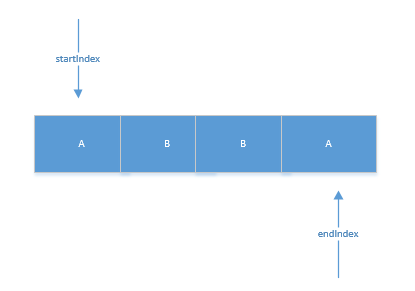
}下面的代码是不允许使用任何其它类的实现,前后分别创建了一个指针。
public static boolean reverseEquals2(String str) {
Objects.requireNonNull(str);
int startIndex = 0;
int endIndex = str.length() - 1;
int middle = str.length() / 2;
for (int i = 0; i < middle; i++) {
char start = str.charAt(startIndex);
char end = str.charAt(endIndex);
if (!Objects.equals(start, end)) {
return false;
}
startIndex++;
endIndex--;
}
return true;
}* String #构造函数
String字符串内部维护了一个char[]数组。不管是哪个构造函数,最终都是解析成char[]数组。
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
public String() {
this.value = new char[0];
}
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
public String(StringBuilder builder) {
this.value = Arrays.copyOf(builder.getValue(), builder.length());
}* 衍生Arrays.copyOf(数组[],新长度)
Arrays.copyOf(基本类型[],新长度) ,这个方法重载了很多种,就是把一个基本类型的数组的值,复制一个新的长度的数组,如果长度大于以前的数组,则用默认值填充。
如果是引用数据类型的话,那么就是重新创建一个容器,但是里面的元素是浅复制,指向的与源数组是同一个对象。
class Temp{
}
Temp[] a = {new Temp(),new Temp()};
Temp[] b = Arrays.copyOf(a,a.length);
System.out.println(Arrays.equals(a,b)); 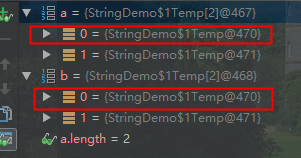
* 衍生Arrays.equals(a,b)
比较的是每个数组对应的角标上的元素,调用它们的equals()方法。
class Arrays
public static boolean equals(Object[] a, Object[] a2) {
//....
for (int i=0; i<length; i++) {
Object o1 = a[i];
Object o2 = a2[i];
if (!(o1==null ? o2==null : o1.equals(o2)))
return false;
}
return true;
}* String #equals
Object类中定义了一个equals方法。
class Object
public boolean equals(Object obj) {
return (this == obj);
}String类重写了equals方法,与另外一个字符串类中char[]数组(引用名为value),比较的是它们的value数组是否每个成员都一样。
PS:写到这里的时候,我突然想,为什么JDK大佬不直接用Arrays#equals方法直接比较,原来Arrays是JDK1.2开始使用的。。水一下
class String
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
* String #内存
如果直接使用 == ,比较的是字符串对象的内存地址。
String a = new String("abc");创建了两个字符串对象,一个是在字符串常量池里,另外一个在堆内存里。
构造函数中有一个 new String(源字符串),把源字符串的 char[] value(基本数据类型)直接赋值给这个新构造的字符串对象。
它们两个使用" == "比较的话,返回false,因为内存不同。
如果使用 #quals(Object)方法比较的话,返回true。因为内部的char[]数组是一样的。
String a = "abc";
String b = new String(a);
System.out.println(a == b);//内存地址不一样false
System.out.println(a.equals(b));//char[]数组一样true
System.out.println(a == b.intern());//b.intern返回了字符串常量池的a,true
* String #hashcode
对char[]数组的每个元素进行运算,近似理解成对每个字符的ASCII码 与 31做运算,并求和。
a的ASCII码是97,b的是98。
为什么使用31作为乘子,是因为31作为一个既不太大又不太小的乘子,计算出来的hashcode值范围处于一个“适中”的区间,能够很好的降低哈希冲突
* 衍生 为什么我们在使用HashMap的时候总是用String做key?
因为字符串是不可变的,当创建字符串时,它的它的hashcode被缓存下来,不需要再次计算。因为HashMap内部实现是通过key的hashcode来确定value的存储位置,所以相比于其他对象更快。这也是为什么我们平时都使用String作为HashMap对象。
* String #startsWith
本质上比较的是char[]数组的前几个字符是否相同。源码中果然也是创建了两个指针。
* String #endWith
endWith从另外一个角度看就是startsWith。指针从 【value.length - suffix.value.length】开始。
* String #indexOf
如果是一个字符串,找到这个字符串第一次出现的地方。匹配的还是char[] value。
String a = "abcabcadef";
//找到ca第一次出现的位置,并且截取它后面的字符串
String s = "ca";
System.out.println(a.indexOf(s));
System.out.println(a.substring(a.indexOf(s) + s.length()));
int fromIndex = 3;
System.out.println(a.substring( a.indexOf(s,fromIndex) + s.length()));//def* String #lastIndexOf
从右向左遍历char[]
* String #subString(int beginIndex)
创建一个新的对象,源码上首先通过beginIndex确定了要截取的子字符串长度是多少,然后使用Arrays.copyOfRange方法复制char[]
public String substring(int beginIndex) {
//remove some code
int subLen = value.length - beginIndex;
return (beginIndex == 0) ?
this : new String(value,beginIndex,subLen);
}
String(char[],int beginIndex,int count){
//remove some code
this.value = Arrays.copyOfRange(value, beginIndex, subLen)
}
* String static#join(String separator , String... elements)
第一个是分隔符,第二个是可变参数。源代码中使用的是JDK1.8出现得StringJoiner类,该类是面向对象编码的典范。
public static String join(CharSequence delimiter, CharSequence... elements) {
Objects.requireNonNull(delimiter);
Objects.requireNonNull(elements);
StringJoiner joiner = new StringJoiner(delimiter);
for (CharSequence cs: elements) {
joiner.add(cs);
}
return joiner.toString();
}
public final class StringJoiner ...
private final String prefix;
private final String delimiter;
private final String suffix;
private String emptyValue;
public StringJoiner(CharSequence delimiter,
CharSequence prefix,
CharSequence suffix) {
Objects.requireNonNull(prefix, "The prefix must not be null");
Objects.requireNonNull(delimiter, "The delimiter must not be null");
Objects.requireNonNull(suffix, "The suffix must not be null");
// make defensive copies of arguments
this.prefix = prefix.toString();
this.delimiter = delimiter.toString();
this.suffix = suffix.toString();
this.emptyValue = this.prefix + this.suffix;
}
* String #split(String regex)
按照指定正则分割,返回String[]
String a = "a,b,c,d,e";
//[a, b, c, d, e]
System.out.println(Arrays.toString(a.split(",")));* String #replace(char,char)
把源字符串的char[]中的所有字符替换成另外一个,并且返回一个新的字符串对象。
public String replace(char oldChar, char newChar) {
//buf is a new char[] after replace all oldChar using newChar
return new String(buf, true);
}* String #replaceFirst(String regex , String replacement)
把符合正则的第一处,替换成replacement。当然还有replaceAll(String regex,String replacement)
* String #matches(String regex)
是否符合指定正则
* String #contains
是否包含,源码思路:indexOf指定字符串,看是否返回 大于 -1 。 -1代表没找到

 浙公网安备 33010602011771号
浙公网安备 33010602011771号