
这样加个中间件,接口速度提升 1000%
本文是在开发 mockm 周边过程中的创作。它可以快速生成 api 以及创造数据,开箱即用,便于部署,恳求不吝提出宝贵意见。
动机
最近在做一个 curd 项目,这里我们代名为 myApi ,用于实现 0 代码、无需声明模型、自动实现增删改查一些列的接口,支持任意关系型数据库。
经过几天的努力,终于把基本的 curd 实现了。但是性能如何呢?要知道,就是因为 json-server 的性能瓶颈太低,才创建此项目的。
json-server 使用 json 作为数据存储载体,当数据大于 10M 的时候,就触及了性能瓶颈,好在该库是用于原型开发,但如果要在生产环境使用,那等于埋了一个雷。
如何进行接口性能测试?
因为已经安装了 node,那就使用 autocannon ,它用于对 http/https 进行负载测试。

测试的结果如下图:
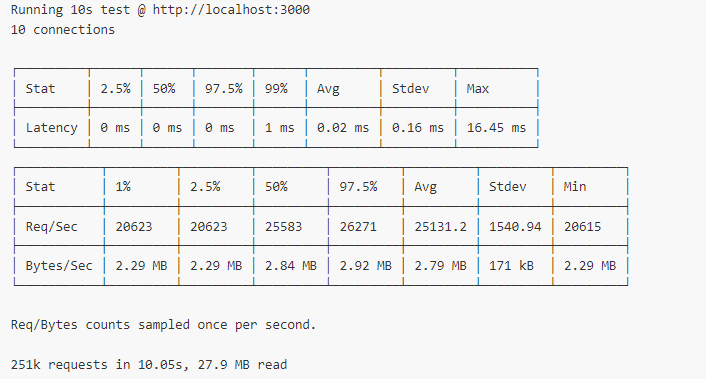
数据解释:
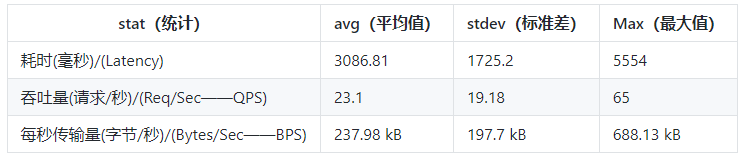
如何优化接口性能?
谈到优化,一般可以有很多个方向,例如业务逻辑、缓存,提升硬件配置等。
但是由于我们的 myApi 项目逻辑本就很简单,所以就先从缓存入手吧,因为经过分析,当前我们的项目是缺少缓存这一实现的。

缓存之 etag
ETag(Entity Tag)是一种由服务器生成的唯一标识符,用于表示资源的特定版本。服务器可以根据资源的内容、大小、最后修改时间等生成 ETag 值。当客户端请求资源时,服务器可以将 ETag 值包含在响应的头部中。客户端在后续请求中可以使用该 ETag 值来检查资源是否已经发生变化。
在 Express 中,我们可以使用 etag 中间件来启用 ETag 缓存。etag 中间件会自动处理 ETag 的生成和比较工作,并在响应头中添加相应的 ETag 值。
下面是一个示例代码,展示了如何在 Express 中使用 ETag 缓存:
const express = require("express");
const app = express();
app.set("etag", true);
app.use(express.static("public")); // 静态资源目录
app.get("/api/data", (req, res) => {
const data = {
message: "Hello, World!",
};
res.json(data);
});
app.listen(3000, () => {
console.log("Server started on port 3000");
});
在上述代码中,我们首先使用 express.static 中间件指定了一个静态资源目录 'public'。这意味着 Express 将自动处理位于 'public' 目录下的静态文件,并为它们生成 ETag 值。
然后,我们定义了一个路由 /api/data,用于返回一个 JSON 数据。在每个请求中,Express 会自动检查客户端请求的 ETag 值是否与服务器上的资源匹配。如果匹配,则服务器返回 304 Not Modified 状态码,表示客户端可以使用缓存的版本。如果不匹配,则服务器返回新的资源,并在响应头中添加新的 ETag 值。
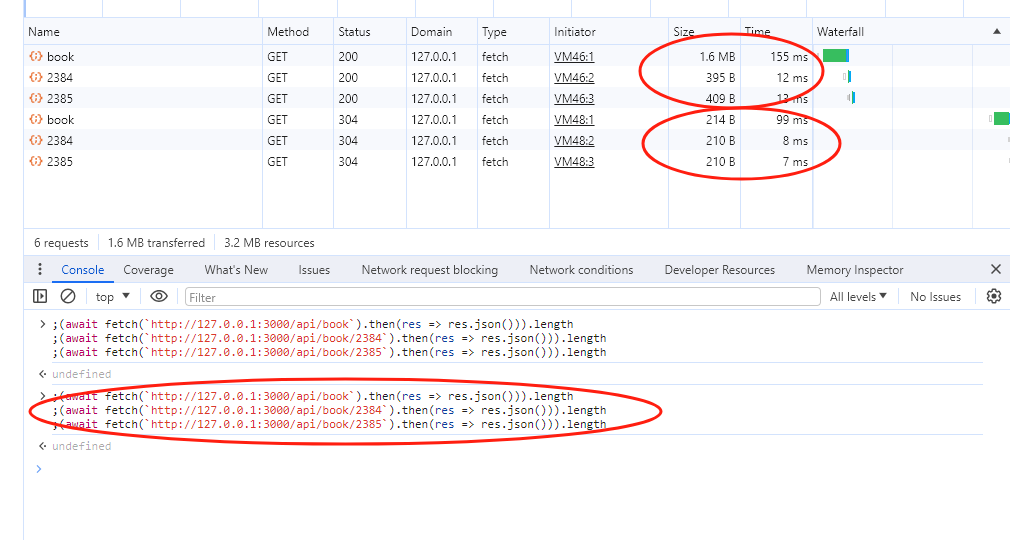
ETag 的生成规则是响应体的简短唯一值,可以看成一个哈希值。观察上面的两张图片,第一次请求时,响应码是 200,并且返回了 Etag 。当下次请求的时候,会把该值带上,服务器会检查该值是否与之前的一致,如果一致,说明没有变化,返回 304,否则返回 200。
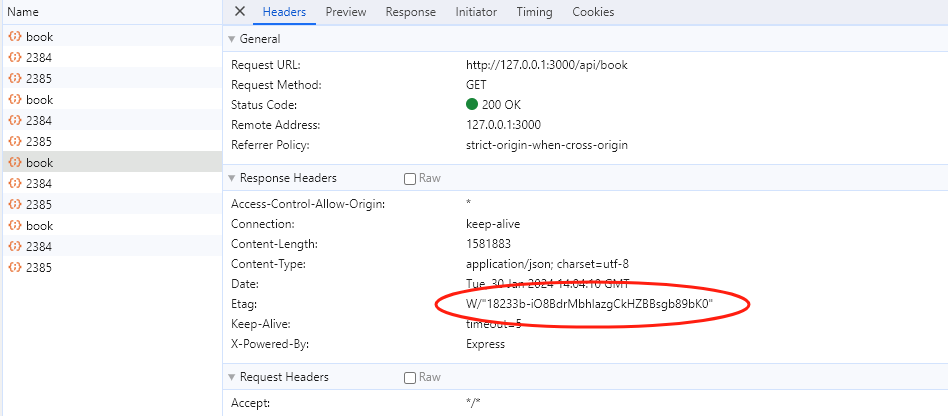
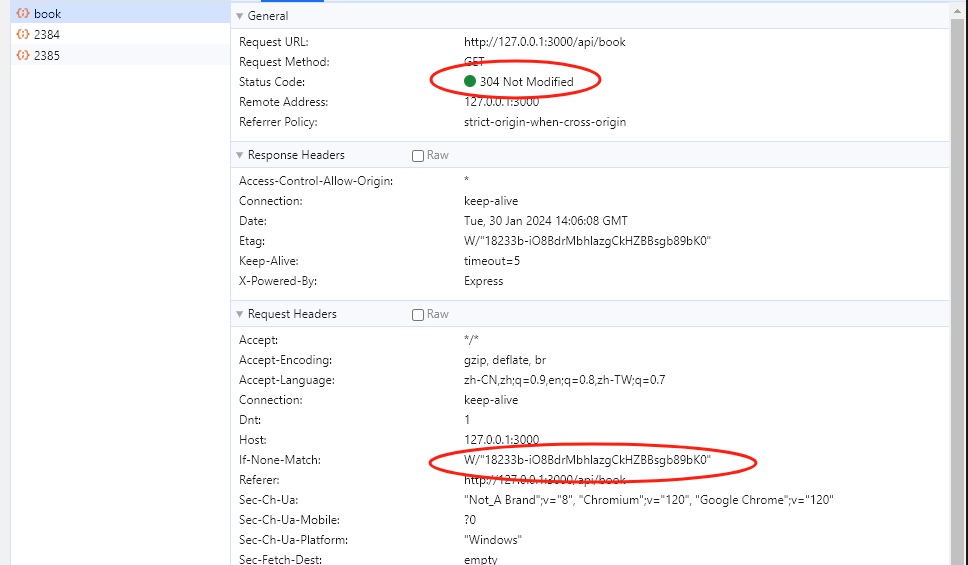
在 chrome 中发起几个接口请求:可以看到,第一次请求时数据为 1.6M,第二次为 214B,请求时间从 155ms 到 99ms 。这得到了以下提升:
- 响应体减少了,在客户端网速很差的情况下,不用再次下载 1.6M 的数据。
- 请求时间变快了,因为响应体没有变,服务器可以对客户端进行响应,再做后续逻辑。
缓存之 cache-control
然后从 cmd 控制台中可以看到,再次请求都有执行 sql。
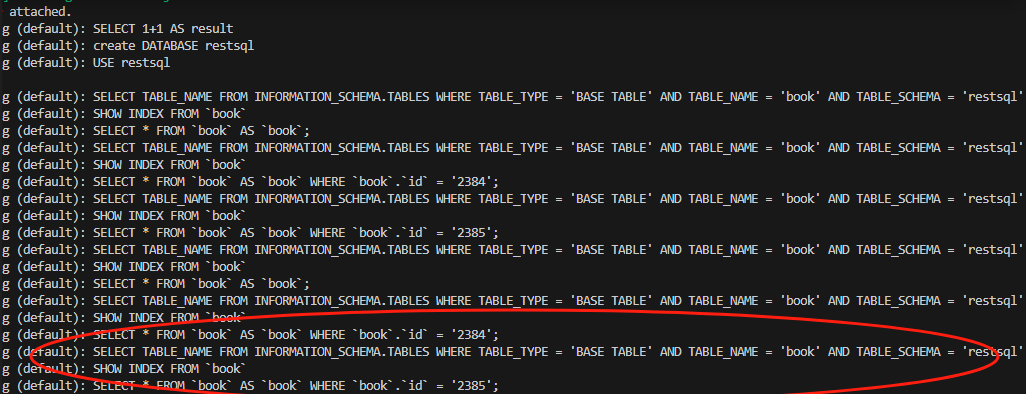
虽然单个 sql 的查询速度通常在 几十到一百毫秒以内。但是为了实现多数据库兼容,我们使用了 ORM 框架,这有一定的转换成本,如果有复杂的业务逻辑存在,又加单次增加不少时间。在这几种叠加效果上,再加上并发的话,差异就会变成非常明显。
为了减少服务器压力,在数据没有变更的情况下,我们最好连业务逻辑相关的代码也不要执行。
那么问题就来了,我们怎么知道数据有没有变更呢?又如何为没有变更的数据进行缓存?
首先我们可以使用 http cache-control 对缓存进行精细化控制。
本文重点请几个属性,如果要了解更多信息,请在参考一节中查询相关文章。
在 Web 开发中,no-cache 和 max-age 是与缓存相关的 HTTP 头部指令,用于控制客户端和服务器之间的缓存行为。它们可以帮助我们更精确地管理缓存策略,以提高性能和资源利用率。
no-cache
no-cache 用于告诉客户端在使用缓存之前先与服务器确认资源是否已更改。当客户端收到带有 no-cache 指令的响应时,它将发送一个条件请求到服务器,以检查资源是否仍然有效。
服务器在收到条件请求后,可以执行一些验证逻辑,例如检查资源的最后修改日期或生成 ETag 值。如果资源未更改,服务器将返回 304 Not Modified 状态码,告知客户端可以使用缓存的版本。如果资源已更改,服务器将返回新的资源,并在响应头中添加新的缓存控制指令。
使用 no-cache 可以确保客户端始终与服务器进行验证,以获取最新的资源版本。这对于某些内容频繁更改的动态资源非常有用,但也会增加一定的网络开销。
max-age
max-age 用于指定资源在客户端缓存中的最大有效期。它表示从服务器发送响应后,客户端可以在指定的时间段内使用缓存的版本,而无需向服务器发出请求。
max-age 的值是以秒为单位的时间间隔。例如,max-age=3600 表示资源在客户端缓存中的有效期为 1 小时。当客户端再次请求相同的资源时,在 max-age 的时间范围内,客户端将直接使用缓存的版本,并避免向服务器发出请求。
使用 max-age 可以减少与服务器的通信次数,提高性能和响应速度。但请注意,这也可能导致客户端在有效期内使用过时的资源,因此需要根据资源的特性和更新频率进行适当的设置。
组合使用
no-cache 和 max-age 可以结合使用,以在客户端和服务器之间实现更细粒度的缓存控制。例如,可以使用 no-cache 确保客户端始终与服务器进行验证,但同时使用 max-age 设置一个相对较长的有效期,以减少与服务器的通信次数。
以下是一个示例响应头,演示了 no-cache 和 max-age 的组合使用:
Cache-Control: no-cache, max-age=3600
在上述示例中,响应头中同时包含了 no-cache 和 max-age 指令。这意味着客户端将始终与服务器进行验证,但在验证通过后,可以在 1 小时内使用缓存的版本。
通过合理地使用 no-cache 和 max-age,我们可以根据资源的特性和需求,灵活地控制缓存策略,从而提高应用程序的性能和用户体验。
总结
no-cache指令告诉客户端在使用缓存之前先与服务器确认资源是否已更改。max-age指令指定资源在客户端缓存中的最大有效期。no-cache和max-age可以结合使用,以实现更精确的缓存控制策略。
缓存相关工具库
apicache
源码地址为 https://github.com/kwhitley/apicache ,共 1.2k stars,最近维护时间为 3 年前。对其尝试了下,默认情况下它会对所有路由进入缓存。这可以理解。
但是,在 myApi 中,当我首先调用 GET /api/book 获取所有书本列表,再调用 POST /api/book 创建一本书,这时 POST /api/book 的请求竟然会返回 /GET /api/book 的响应,这让我很意外。看进来默认情况下实现的是 path 级别的缓存,而不是 method + path 级别的缓存。
apicache 提供了一个选项 appendKey 用于自定义缓存的 key,应该是精细级别的控制。这个函数我没有测试过。
apicache.options({
appendKey: (req, res) => req.method + res.session.id,
});
还有另外一个选项叫缓存组,看起来像是我要的东西(我想缓存一个 table 表,如果表中任何数据更新,则此表的缓存也要更新):
var apicache = require("apicache");
var cache = apicache.middleware;
// GET collection/id
app.get("/api/:collection/:id?", cache("1 hour"), function (req, res, next) {
req.apicacheGroup = req.params.collection;
// do some work
res.send({ foo: "bar" });
});
// POST collection/id
app.post("/api/:collection/:id?", function (req, res, next) {
// update model
apicache.clear(req.params.collection);
res.send("added a new item, so the cache has been cleared");
});
观察上面代码,/api/:collection 中的 :collection 类比表名,如果通过 POST /api/:collection 进行数据创建时,就调用 apicache.clear(req.params.collection) 清除 :collection 表的缓存。
可是经测试,结果还是不对。可能我的使用方式还不是太正确,但介于此库 3 年没有更新,以及我自身有一些想着反正都是根据逻辑来控制缓存策略,那好像和自己写一个缓存器也没什么区别,对于此工具提供的 redis 支持,在 myApi 里是不需要的。所以没有继续探究问题出在哪里。
lru-cache
star 高达 5k,npm 周使用量 185,936,796 。这是一个基于访问频率进入缓存保留的库。即那些不常用的缓存会先被删除。
@isaacs/ttlcache
这是一个基于时间的缓存库,最先到期的缓存会最先被删除。
选择和应用
在我的用例中,我认为基于时间的缓存策略对于我来说是更好的选择。所以我选择了 @isaacs/ttlcache。
const TTLCache = require("@isaacs/ttlcache");
const cacheStore = {};
function cacheFn(config) {
return (req, res, next) => {
const method = req.method.toLowerCase();
const query = Object.keys(req.query).length ? req.query : ``;
const { table = ``, id = `` } = req.params;
const cacheTable = (cacheStore[table] =
cacheStore[table] || new TTLCache({ max: 10000, ttl: 1e3 * 10 })); // 表级别的缓存
if (method === `get`) {
const disableCache = req.headers["cache-control"] === `no-cache`;
const reqKey = generateMD5(
[method, table, id, JSON.stringify(query)].join(``)
);
const etag = req.headers["if-none-match"];
console.log({ reqKey, etag });
// 禁用缓存时,获取最新数据,并刷新缓存,这样在开启缓存时会直接命中缓存
if (disableCache) {
cacheTable.set(reqKey, true);
next();
} else if (!cacheTable.get(reqKey)) {
// 缓存失效时,获取最新数据并刷新缓存
cacheTable.set(reqKey, true);
next();
} else if (cacheTable.get(reqKey)) {
// 缓存有效时,告诉浏览器缓存可用
res.setHeader("Cache-Control", "no-cache");
res.status(304).end();
} else {
next();
}
} else {
cacheTable.clear();
next();
}
console.log(cacheStore);
};
}
这段代码的主要功能是根据请求的不同情况来处理缓存。
- 在每个请求中,根据请求的方法、表名、ID 和查询参数生成一个唯一的请求键
reqKey。 - 如果请求方法是
GET:- 检查请求头中是否包含
cache-control: no-cache指令,如果是,则禁用缓存,获取最新数据,并刷新缓存。 - 如果缓存失效(即
reqKey在缓存中不存在),则获取最新数据,并刷新缓存。 - 如果缓存有效(即
reqKey在缓存中存在),则设置响应头Cache-Control: no-cache,并返回 304 Not Modified 状态码,告知浏览器可以使用缓存。 - 如果以上条件都不满足,则继续处理下一个中间件或路由处理程序。
- 检查请求头中是否包含
- 如果请求方法不是
GET,则清除缓存,并继续处理下一个中间件或路由处理程序。 - 在每个请求结束后,打印缓存存储对象
cacheStore。
使用该插件后的测试效果为: 100 并发 800ms 左右
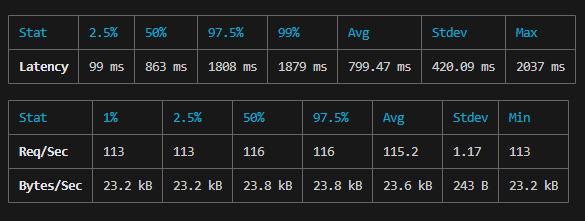
额外的思考和行动
在上面的代码中,可以看到我们为每个 table 实现了一个缓存实例。在实例中每个 table 下的 api 是缓存的子项,如果子项有更新,则缓存实例会更新。而所有的实例都保存在 cacheStore 这个对象中。这样看来,@isaacs/ttlcache 这个库似乎最大的作用就是用来管理缓存总数、过期时间,提供了一些简单的 get set clear 方法而已?那我尝试弄一个看看,这样又可以少引用一个库了?
首先,反正大家都是内存缓存,那直接把状态保存在公用对象中即可。另外,过期时间和缓存大小这些通过 Date.now() 对比,数组 length 对比这些好像就能搞定。试试看:
class TTLCache {
options = {
ttl: 60 * 60 * 1e3, // 缓存过期时间
max: 10 * 1e3, // 最大缓存数量
};
store = {}; // 保存的 key 缓存状态
constructor(options) {
this.options = Object.assign(this.options, options);
setInterval(() => {
const list = Object.entries(this.store);
list.map(([key, val], index) => {
if (
index < this.options.max || // 溢出的缓存
Date.now() - val < this.options.ttl // 过期的缓存
) {
delete this.store[key];
}
});
}, this.options.ttl);
return this;
}
get(key) {
const old = this.store[key];
return old ? Date.now() - old < this.options.ttl : false;
}
set(key) {
this.store[key] = Date.now();
}
clear() {
this.store = {};
}
}
经尝试,使用自己实现的缓存器,减少 60% 以上的时间,从 800ms 到 320ms。为了保证内存占用不高,定时根据 max 配置裁剪缓存数量和过期的缓存。
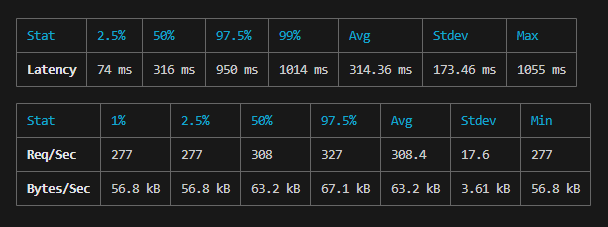
去除 console 后 140ms 左右,大约每秒处理 1400 个请求,5 秒处理完 7000 个请求,并发数为 200,平均每个接口用时 70ms。
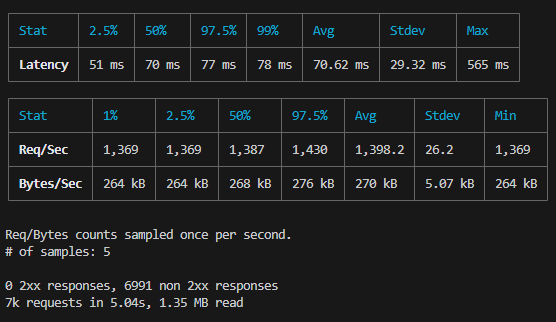
store 对象的值如下:
store = {
"651b10c00298624a5b61053c6d970f7c": 1706627825171,
d980f49196fce9d6d1fd41557c8ed9da: 1706627825353,
"34260c615ac67e948250222b0a506136": 1706627825367,
};
乍一看,性能好像是提升了不少,但其实是有很多需要完善的地方的,例如:定时器的执行时间是 ttl 的设置时间,假如 ttl 为 1 小时,那么在这 1 小时内,是不会触发缓存数量裁剪的,在特殊情况下这会导致内存增加。
不过,就一个 hash 和时间,这应该也要不了多少内存(如果存储的时间是应用启动时间到当前时间的差,并且使用 etag 的计算方式,可能还会减少很多内存)。所以我就先使用自己的这段代码吧(应该 ttlcache/lru-cache 他们有更完善的实现,例如内存限制等)。
总结
- etag:服务器读取真实数据做比较,如果相同则不发送真实数据。
- cache:服务器不读取真实数据,而是返回上次请求中的数据或返回未变更标志。
- 难点:判断某请求是否为同一请求,例如相同的请求参数和身份。
- 注意:浏览器不使用缓存时,就算服务器发送未变更标记,浏览器也不从缓存读取数据,而是从服务器读取数据,这时要求服务器必须要发送数据。
- 结果:从并发 100 avg 800ms 到并发 200 avg 70ms 应该有提升 1000% 的吧。
- 逃:前端是产品形态差异很大的平台,不谈应用场景都是耍流氓。
相关文章
- 内存缓存 https://www.npmjs.com/package/memory-cache
- Express 使用服务端缓存 https://cloud.tencent.com/developer/article/2041817
- etag 在 expressjs 中如何工作 https://stackoverflow.com/questions/24542959/how-does-a-etag-work-in-expressjs
本文是在开发 mockm 周边过程中的创作。它可以快速生成 api 以及创造数据,开箱即用,便于部署,恳求不吝提出宝贵意见。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号