C++关于使用动态库类的一些测试
C++对动态库的测试
需要使用一个类,这个类在动态库里面,而这个静态库有两个版本。
我们自己写代码模拟一下这种情况。
场景一:类的变化只是多了或者少了一个或多个函数,并没有函数名的冲突
版本一:
//头文件
#pragma once
#ifndef BUILDING_DLL
#define DLLIMPORT __declspec(dllexport)
#else
#define DLLIMPORT __declspec(dllimport)
#endif
#include<iostream>
using namespace std;
class DLLIMPORT Person
{
public:
void print();
void setId(int ida);
void setName(string names);
int getId();
string getName();
private:
int id;
string name;
};
//源文件
#include "person.h"
void DLLIMPORT Person::print()
{
cout << "this is project1's print" << endl;
}
void DLLIMPORT Person::setId(int ida)
{
id = ida;
}
void DLLIMPORT Person::setName(string names)
{
name = names;
}
int DLLIMPORT Person::getId()
{
return id;
}
string DLLIMPORT Person::getName()
{
return name;
}
编译成了lib和dll文件。
为了让别人使用,需要提供头文件、lib文件和dll文件。
版本二:
//头文件
#pragma once
#ifndef BUILDING_DLL
#define DLLIMPORT __declspec(dllexport)
#else
#define DLLIMPORT __declspec(dllimport)
#endif
#include<iostream>
using namespace std;
class DLLIMPORT Person
{
public:
void printTwo();
private:
int id;
string name;
};
//源文件
#include "person.h"
void DLLIMPORT Person::printTwo()
{
cout << "this is project2's print printTwo" << endl;
id++;
}
生成文件都是一样的,类名一样,成员也一样,只是函数变化。
为了让我们使用这个类时可以使用所有的函数。对于这种函数,我们可以直接修改类定义即可。
person.h
#include<iostream>
using namespace std;
class Person
{
public:
void print();
void setId(int ida);
void setName(string names);
int getId();
string getName();
void printTwo();
private:
int id;
string name;
};
main.cpp
#include "person.h"
#include<iostream>
using namespace std;
int main()
{
Person p;
p.setId(7);
p.print();
p.printTwo();
cout << p.getId()<<endl;
system("pause");
}
需要注意的是,需要注意两个版本库的重名问题。
方案:咱也不懂lib里面是什么,只知道里面有动态库的名称,那就暴力一点。
比如本来项目是dlltwo,生成dlltwo.lib和 dlltwo.dll
现在有两套同名的文件,我们选择其中一套修改名称即可。比如把第一套改成dllttt.lib和dllttt.dll
仅仅改文件名称,还是不够的,还需要改dllttt.lib里面的内容。这个好像没有捷径,直接fopen打开文件。
暴力搜索,把所有的dlltwo.dll改成dllttt.dll,注意和你修改的文件名称对应,还有长度一致。
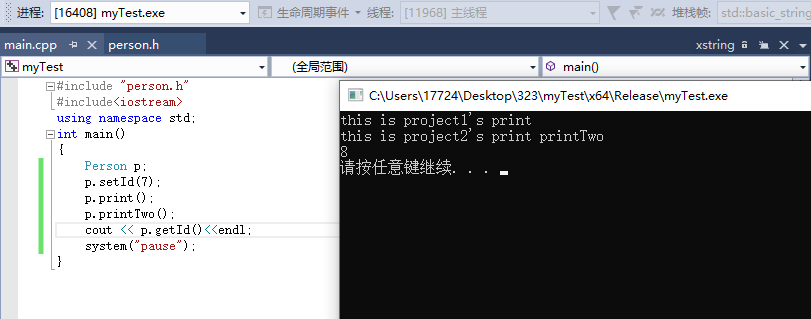
这样,就可以实现同时使用两个版本的动态库了。这只是针对多一个函数、少一个函数的情况。
场景二:
新版本的源文件修改了原来的同名函数:
#pragma once
#ifndef BUILDING_DLL
#define DLLIMPORT __declspec(dllexport)
#else
#define DLLIMPORT __declspec(dllimport)
#endif
#include<iostream>
using namespace std;
class DLLIMPORT Person
{
public:
void print();
private:
int id;
string name;
};
#include "person.h"
void DLLIMPORT Person::print()
{
cout << "this is project2's print printTwo" << endl;
id++;
}
main.cpp
#include "person.h"
#include<iostream>
using namespace std;
int main()
{
Person p;
p.setId(7);
p.print();
cout << p.getId()<<endl;
system("pause");
}
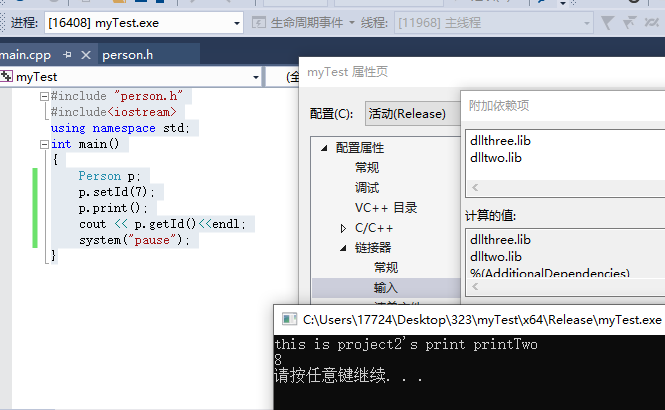
这种情况,运行结果和依赖项的先后顺序有关系。
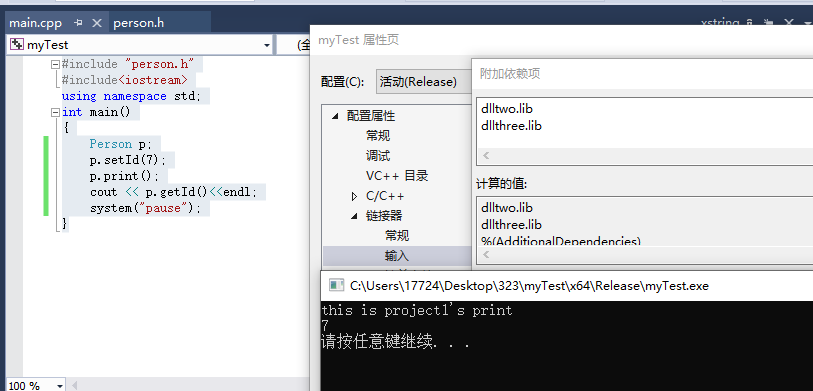
先导入哪个库,那个函数就是哪个库的。
场景三:
新版本库的代码:
没什么太大变化,就是进行了变量位置的变化,复杂点的可能增加或者减少。
你会想,改个顺序而已,调用的时候,person.id++,还不就是一样的,实则不然。
C++是一门非常灵活的语言。有时候多尝试就会发现,打印类的地址,和类中第一个成员的地址是一样的,多尝试,就会发现,成员地址是有规律分布的,而且很明显和定义的先后顺序有关系。对人而言,怎么先后调整,我们操作的成员是不会变的。我们当然可以直接编译链接,生成库,然后按照场景一那样运行。但是结果显然和第一种是完全不同的。这样做,骗得了编译器,但是运行时会出错,为什么,因为类函数操作成员是按照类实例的地址加上偏移量来弄的。
#pragma once
#ifndef BUILDING_DLL
#define DLLIMPORT __declspec(dllexport)
#else
#define DLLIMPORT __declspec(dllimport)
#endif
#include<iostream>
using namespace std;
class DLLIMPORT Person
{
public:
void printTwo();
private:
string name;
int id;
};
#include "person.h"
void DLLIMPORT Person::printTwo()
{
cout << "this is project2's print printTwo" << endl;
id++;
}
我们要想得到第一种的运行结果,只能自己手动改改了。
把新版本的lib和dll文件,需要改dll和lib的名称,lib里面的dll名称,lib里面的类名称,dll里面的类名称。比如改成Persom.
因为这个库是我们自己写的。所以合并两个类就好了。
#include<iostream>
using namespace std;
#define private public //不需要考虑什么私有变量的问题,一个宏定义就可以骗过编译器了。
class Person
{
public:
void print();
void setId(int ida);
void setName(string names);
int getId();
string getName();
private:
int id;
string name;
};
class Persom
{
public:
void printTwo();
private:
string name;
int id;
};
//添加一个新类,手动实现原来的类的方法。
class MyPerson
{
public:
MyPerson()
{
person = new Person();
persom = new Persom();
}
void print()
{
person->print();
}
void setId(int ida)
{
id = ida;
person->setId(id);
persom->id = id;
}
void setName(string names)
{
name = names;
person->setName(name);
persom->name = name;
}
int getId()
{
return id;
}
string getName()
{
return name;
}
void printTwo()
{
persom->print();
setId(persom->id);
}
private:
int id;
string name;
Person* person;
Persom* persom;
};
main.cpp
#include "person.h"
#include<iostream>
using namespace std;
int main()
{
//Person p;
//p.setId(7);
//p.print();
//cout << p.getId()<<endl;
MyPerson pa;
pa.setId(7);
pa.print();
pa.printTwo();
cout << pa.getId() << endl;
system("pause");
}
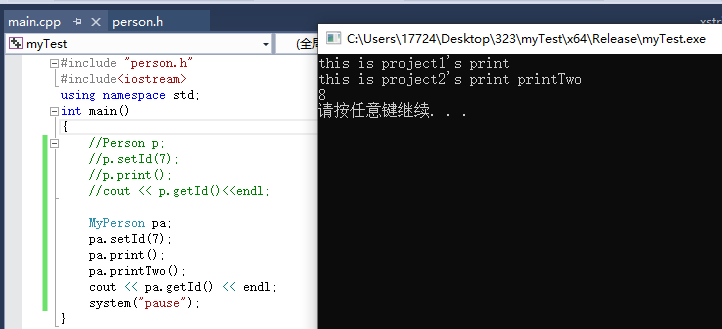
这样运行结果就和场景一一致了,简而言之,就是自己对两个类进行包装。
特别注意的是,例子总是简单的,而且这两个库都是我们自己写的。实际工作中,我们用的是别人提供的库。就需要自己分析类中数据的变化,然后进行包装了。
本人经验有限,暂时没有别的好办法了,欢迎探讨。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号