

转:Content-disposition设置返回的文件名为中文时无法正常返回文件名问题
在做文件下载时,当文件名为中文时,经常会出现乱码现象。
参考文章: http://blog.robotshell.org/2012/deal-with-http-header-encoding-for-file-download/
本文就详细给出案例来解决这一乱码问题,以及还一直未解决的一个疑问,欢迎大家一起来探讨。
大体的原因就是header中只支持ASCII,所以我们传输的文件名必须是ASCII,当文件名为中文时,必须要将该中文转换成ASCII。
转换方式有很多:
方式一:将中文文件名用ISO-8859-1进行重新编码,如headers.add("Content-disposition","attachment;filename="+new String("中国".getBytes("UTF-8"),"ISO-8859-1")+".txt");
方式二:可以对中文文件名使用url编码,如headers.add("Content-disposition","attachment;filename="+URLEncoder.encode("中国","UTF-8")+".txt");
疑问:中文文件名转换成ASCII后传给浏览器,浏览器遇到一堆ASCII,如何能正确的还原出来我们原来的中文文件名的呢?
实验案例:
乱码现象如下:
@RequestMapping(value="/test/httpEntity1",method=RequestMethod.GET)
public HttpEntity<String> testHttpEntity1() throws UnsupportedEncodingException{
String body="abc";
HttpHeaders headers=new HttpHeaders();
headers.add("Content-disposition","attachment;filename=中国.txt");
HttpEntity<String> ret=new HttpEntity<String>(body,headers);
return ret;
}
这里的filename直接使用中文文件,然后就造成了下面的乱码现象: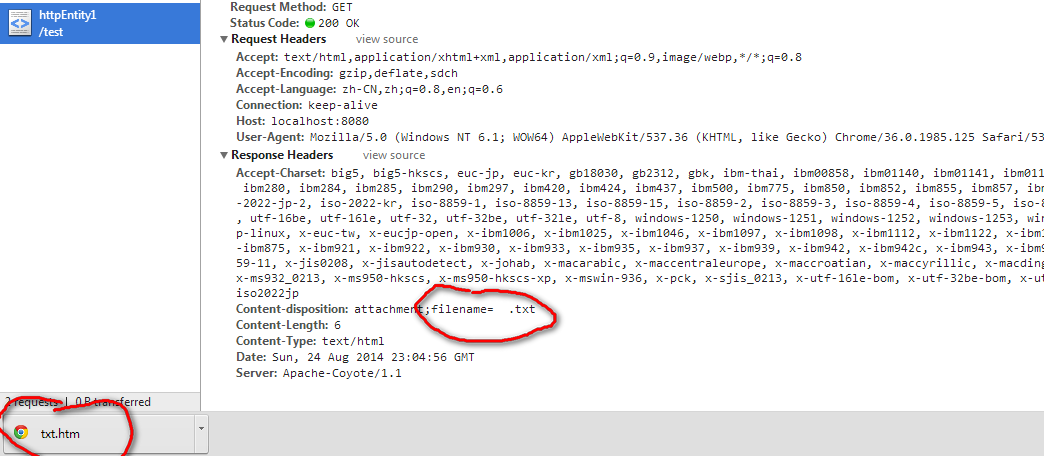
文件名后缀也完全变了。
原因就是header只支持ASCII,所以我们要把"中国"转换成ASCII。
解决方案一:将中文文件名用ISO-8859-1进行重新编码
@RequestMapping(value="/test/httpEntity",method=RequestMethod.GET)
public HttpEntity<String> testHttpEntity() throws UnsupportedEncodingException{
String body="abc";
HttpHeaders headers=new HttpHeaders();
headers.add("Content-disposition","attachment;filename="+new String("中国".getBytes("UTF-8"),"ISO-8859-1")+".txt");
HttpEntity<String> ret=new HttpEntity<String>(body,headers);
return ret;
}
chrome为: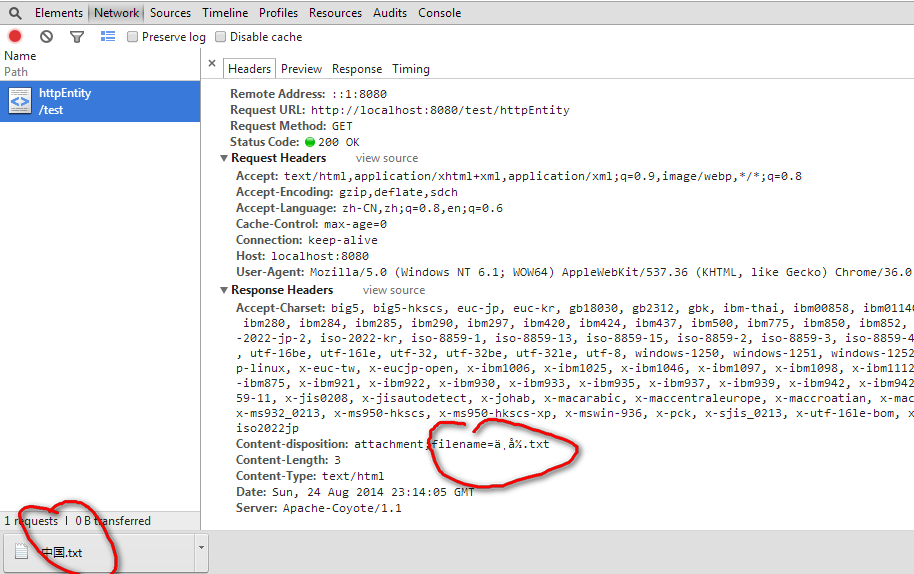
IE11为:
chrome解决了乱码现象,但IE没有。但是你是否想过,浏览器面对一堆Content-disposition:attachment;filename=ä¸å½.txt,它又是如何来正确显示的中文文件名"中国.txt"的呢,它肯定要对ä¸å½,重新进行UTF-8编码才能正确显示出"中国",即必须进行类似如下的操作:new String("ä¸å½".getBytes("ISO-8859-1"),"UTF-8"),才能正常显示出"中国.txt"。而IE11进行的类似操作为:new String("ä¸å½".getBytes("ISO-8859-1"),"GBK")。
同样的实验,只是把UTF-8改成GBK:
@RequestMapping(value="/test/httpEntity",method=RequestMethod.GET)
public HttpEntity<String> testHttpEntity() throws UnsupportedEncodingException{
String body="abc";
HttpHeaders headers=new HttpHeaders();
headers.add("Content-disposition","attachment;filename="+new String("中国".getBytes("GBK"),"ISO-8859-1")+".txt");
HttpEntity<String> ret=new HttpEntity<String>(body,headers);
return ret;
}
chrome为: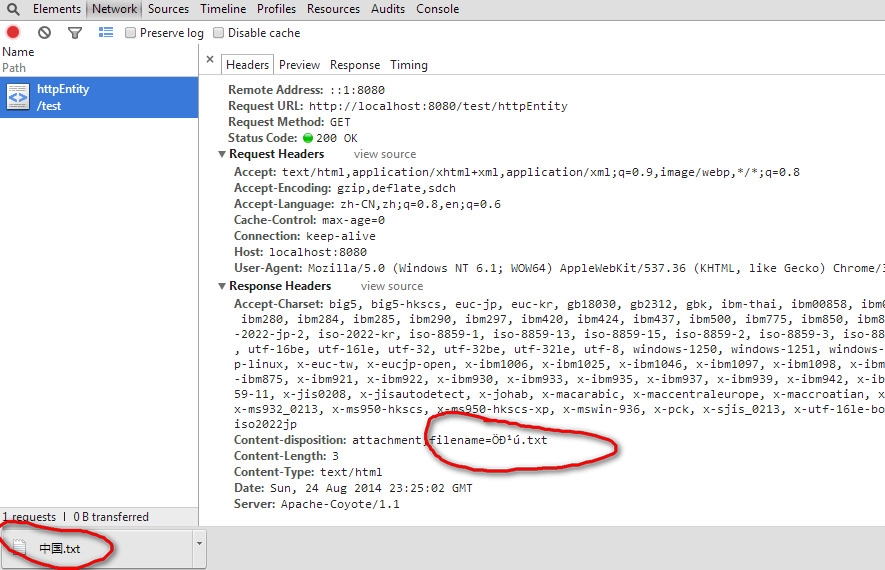
IE11为:
IE11和chrmoe都能正确显示,面对Content-disposition:attachment;filename=Öйú.txt,浏览器也必须进行如下类似的操作才能正确还原出"中国",new String("Öйú".getBytes("ISO-8859-1"),"GBK")。
这里就可以提出我们的疑问了,浏览器面对ä¸å½、Öйú都能正确还原出"中国",选择UTF-8还是GBK,它到底是怎么做到的呢?依据又是什么呢?难道它是要计算出概率?这便是我的疑问,还请大家一起探讨和研究。
接下来说说其他的解决方案:
解决方案二:可以对中文文件名使用url编码
@RequestMapping(value="/test/httpEntity",method=RequestMethod.GET)
public HttpEntity<String> testHttpEntity() throws UnsupportedEncodingException{
String body="abc";
HttpHeaders headers=new HttpHeaders();
headers.add("Content-disposition","attachment;filename="+URLEncoder.encode("中国","UTF-8")+".txt");
HttpEntity<String> ret=new HttpEntity<String>(body,headers);
return ret;
}
chrome为:
IE11为:
也能正常显示出"中国.txt"。
然而将该方案的UTF-8换成GBK,浏览器却不支持了。
如下:
@RequestMapping(value="/test/httpEntity",method=RequestMethod.GET)
public HttpEntity<String> testHttpEntity() throws UnsupportedEncodingException{
String body="abc";
HttpHeaders headers=new HttpHeaders();
headers.add("Content-disposition","attachment;filename="+URLEncoder.encode("中国","GBK")+".txt");
HttpEntity<String> ret=new HttpEntity<String>(body,headers);
return ret;
}
chrome为: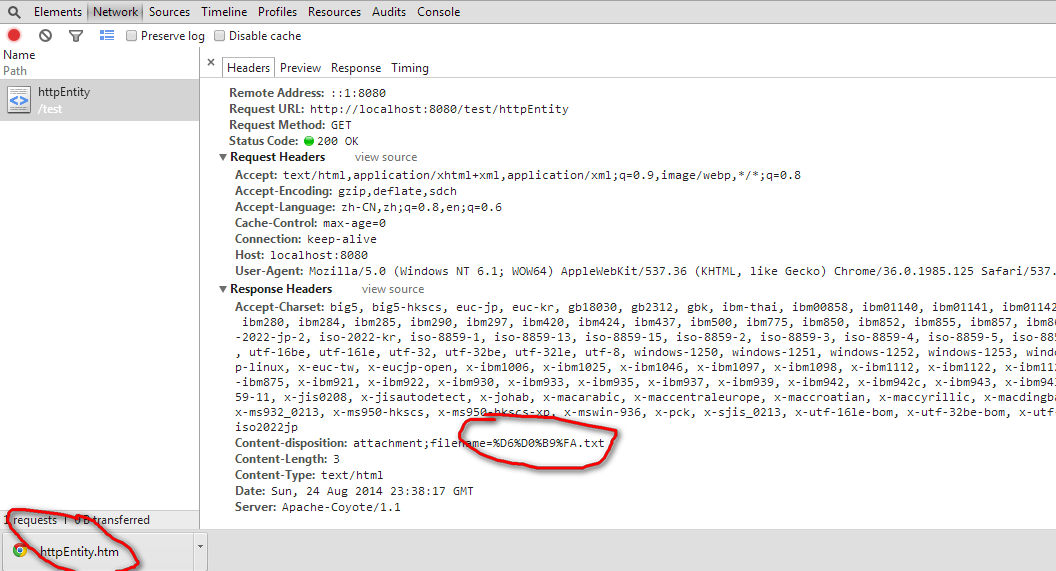
文件名也全变了。
IE11为:
这里就是说对于URL编码,支持UTF-8,其他的好像还不支持。
解决方案三:
使用最新的解决方案,即filename*=charset'lang'value。charset则是给浏览器指明以什么编码方式来还原中文文件名。
如filename*=UTF-8''value,其中value为原始数据的UTF-8形式的URL编码。
如下:
@RequestMapping(value="/HttpEntity",method=RequestMethod.GET)
public HttpEntity<String> testHttpEntity() throws UnsupportedEncodingException{
HttpHeaders headers=new HttpHeaders();//filename="+URLEncoder.encode("中国","UTF-8")+";
String body="abc";
headers.add("Content-Disposition","attachment;filename*=UTF-8''"+URLEncoder.encode("中国","UTF-8")+".txt");
HttpEntity<String> ret=new HttpEntity<String>(body, headers);
return ret;
}
chrome为: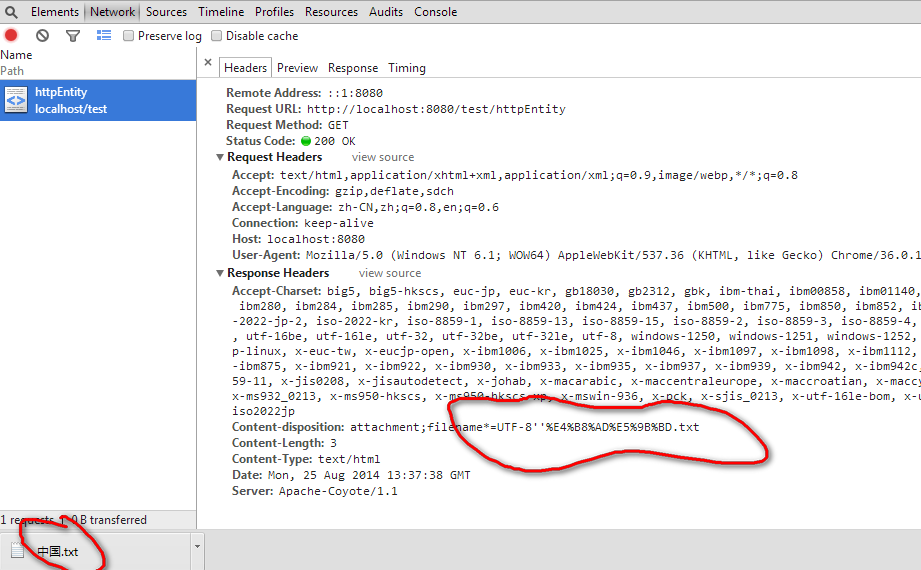
IE11为:
都能够正确显示。
若使用headers.add("Content-Disposition","attachment;filename*=GBK''"+URLEncoder.encode("中国","UTF-8")+".txt"),对此,chrome则是按照GBK方式来还原中文文件名的,所以就会变成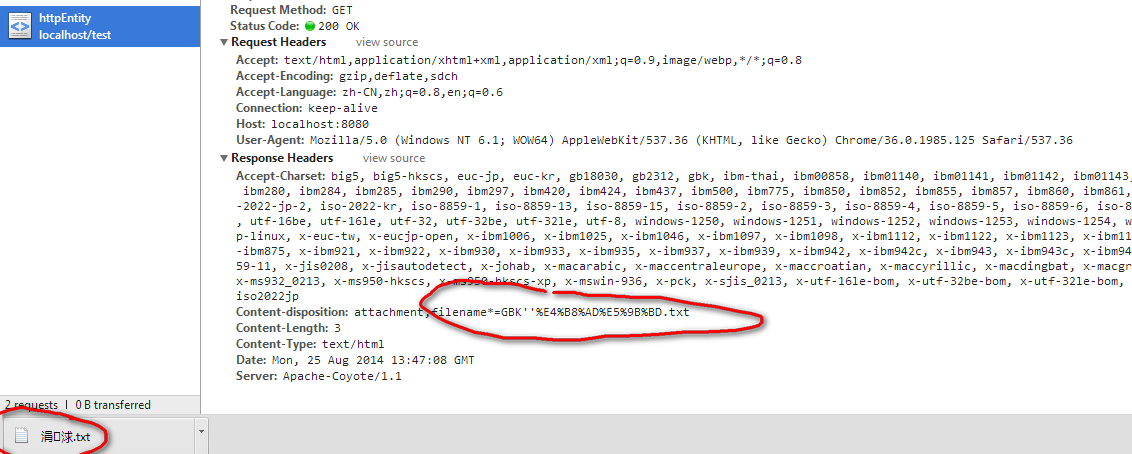
造成乱码。而IE11则直接是
若使用headers.add("Content-disposition","attachment;filename*=GBK''"+URLEncoder.encode("中国","GBK")+".txt")
chrome为: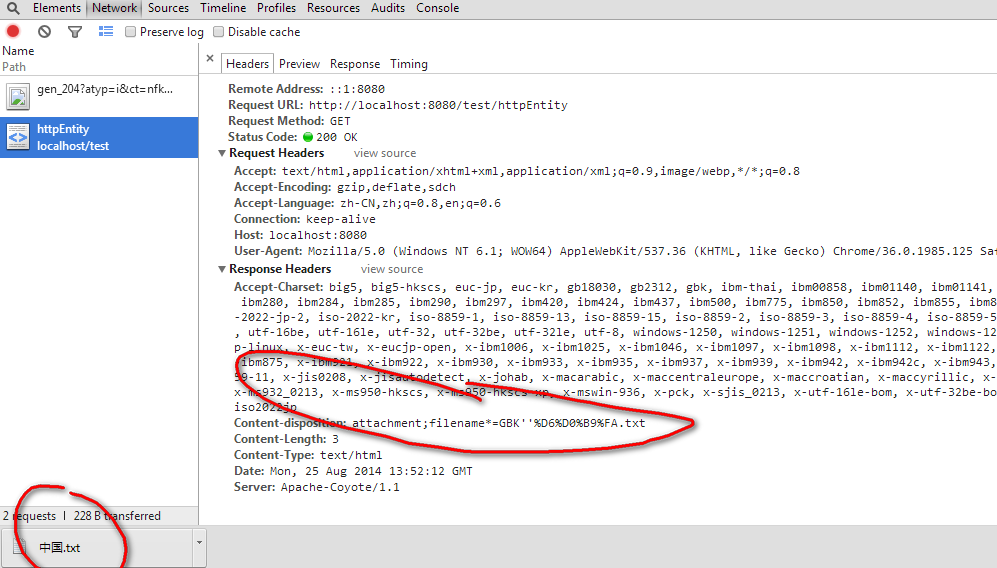
IE11为:
即IE11仅支持filename*=UTF-8编码形式的。
然后就是headers.add("Content-disposition","attachment;filename="+URLEncoder.encode("中国","UTF-8")+".txt;filename*=UTF-8''"+URLEncoder.encode("中国","UTF-8")+".txt");filename和filename*可以组合使用,来解决跨浏览器的问题。
