
性能优化的流程详解
一、流程图

在上述通用流程的四个步骤当中,步骤2和3我们会在接下来两个部分重点进行介绍。首先我们来看一下,在准备阶段和测试阶段,我们需要做一些什么。
二、准备阶段
首先,需要对我们进行调优的对象进行详尽的了解,所谓知己知彼,百战不殆。
a. 对性能问题进行粗略评估,过滤一些因为低级的业务逻辑导致的性能问题。譬如,线上应用日志级别不合理,可能会在大流量时导致 CPU 和磁盘的负载飙高,这种情况调整日志级别即可;
b. 了解应用的的总体架构,比如应用的外部依赖和核心接口有哪些,使用了哪些组件和框架,哪些接口、模块的使用率较高,上下游的数据链路是怎么样的等;
c. 了解应用对应的服务器信息,如服务器所在的集群信息、服务器的 CPU/内存信息、安装的 Linux 版本信息、服务器是容器还是虚拟机、所在宿主机混部后是否对当前应用有干扰等;
其次,我们需要获取基准数据,然后结合基准数据和当前的一些业务指标,确定此次性能优化的最终目标。
a. 使用基准测试工具获取系统细粒度指标。可以使用若干 Linux 基准测试工具(eg. jmeter、ab、loadrunnerwrk、wrk等),得到文件系统、磁盘 I/O、网络等的性能报告。除此之外,类似 GC、Web 服务器、网卡流量等信息,如有必要也是需要了解记录的;
b. 通过压测工具或者压测平台(如果有的话),对应用进行压力测试,获取当前应用的宏观业务指标,譬如:响应时间、吞吐量、TPS、QPS、消费速率(对于有 MQ 的应用)等。压力测试也可以省略,可以结合当前的实际业务和过往的监控数据,去统计当前的一些核心业务指标,如午高峰的服务 TPS。
二、测试阶段
进入到这一阶段,说明我们已经初步确定了应用性能瓶颈的所在,而且已经进行初步的调优了。检测我们调优是否有效的方式,就是在仿真的条件下,对应用进行压力测试。注意:由于 Java 有 JIT(just-in-time compilation)过程,因此压力测试时可能需要进行前期预热。如果压力测试的结果符合了预期的调优目标,或者与基准数据相比,有很大的改善,则我们可以继续通过工具定位下一个瓶颈点,否则,则需要暂时排除这个瓶颈点,继续寻找下一个变量。
a. 性能瓶颈点通常呈现 2/8 分布,即80%的性能问题通常是由20%的性能瓶颈点导致的,2/8 原则也意味着并不是所有的性能问题都值得去优化;
b. 性能优化是一个渐进、迭代的过程,需要逐步、动态地进行。记录基准后,每次改变一个变量,引入多个变量会给我们的观测、优化过程造成干扰;
c. 不要过度追求应用的单机性能,如果单机表现良好,则应该从系统架构的角度去思考; 不要过度追求单一维度上的极致优化,实际环境是多系统、多服务的整体架构在工作,如可能过度追求 CPU 的性能而忽略了内存方面的瓶颈;
d. 选择合适的性能优化工具,可以使得性能优化取得事半功倍的效果;
e. 整个应用的优化,应该与线上系统隔离,新的代码上线应该有降级方案。
三、瓶颈点分析工具箱
性能优化其实就是找出应用存在性能瓶颈点,然后设法通过一些调优手段去缓解。性能瓶颈点的定位是较困难的,快速、直接地定位到瓶颈点,需要具备下面两个条件:
-
恰到好处的工具;
-
一定的性能优化经验。
工欲善其事,必先利其器,我们该如何选择合适的工具呢?不同的优化场景下,又该选择那些工具呢?
首选,我们来看一下大名鼎鼎的「性能工具(Linux Performance Tools-full)图」,想必很多工程师都知道,它出自系统性能专家 Brendan Gregg。该图从 Linux 内核的各个子系统出发,列出了我们在对各个子系统进行性能分析时,可使用的工具,涵盖了监测、分析、调优等性能优化的方方面面。除了这张全景图之外,Brendan Gregg 还单独提供了基准测试工具(Linux Performance Benchmark Tools)图、性能监测工具(Linux Performance Observability Tools)图等,更详细的内容请参考 Brendan Gregg 的网站说明。
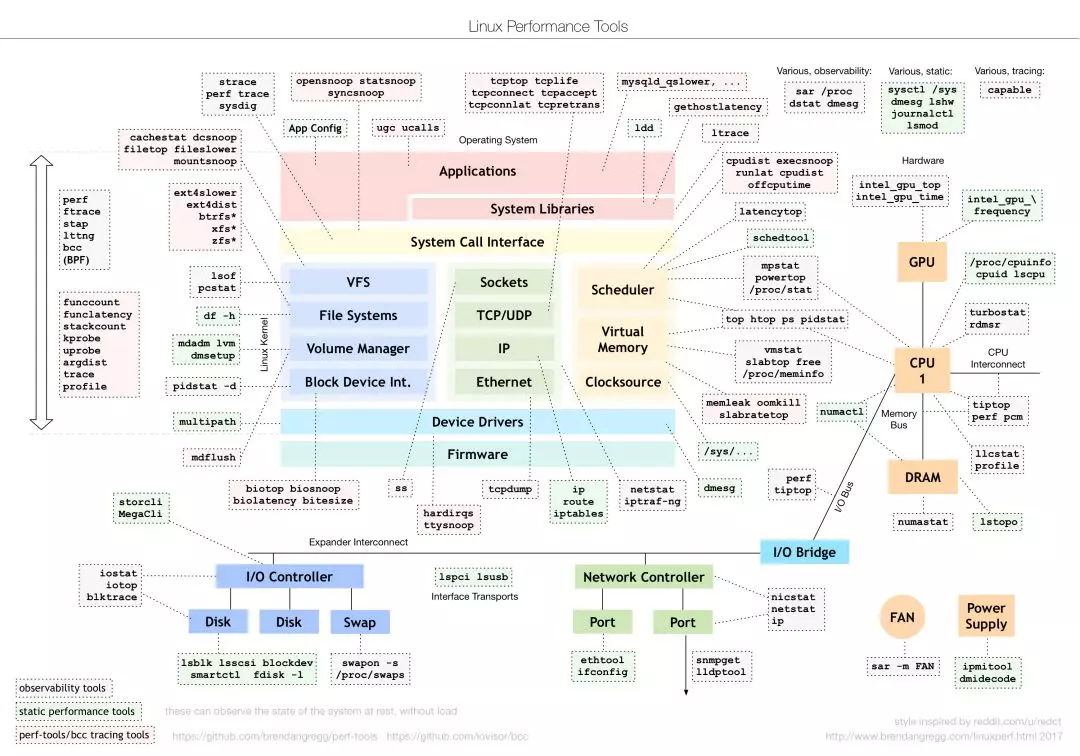
上面这张图非常经典,是我们做性能优化时非常好的参考资料,但事实上,我们在实际运用的时候,会发现可能它并不是最合适的,原因主要有下面两点:
1)对分析经验要求较高。上面这张图其实是从 Linux 系统资源的角度去观测性能指标的,这要求我们对 Linux 各个子系统的功能、原理要有所了解。举例:遇到性能问题了,我们不会拿每个子系统下的工具都去试一遍,大多数情况是:我们怀疑某个子系统有问题,然后根据这张图上列举的工具,去观测或者验证我们的猜想,这无疑拔高了对性能优化经验的要求;
2)适用性和完整性不是很好。我们在分析性能问题时,从系统底层自底向上地分析是较低效的,大多数时候,从应用层面去分析会更加有效。性能工具(Linux Performance Tools-full)图只是从系统层一个角度给出了工具集,如果从应用层开始分析,我们可以使用哪些工具?哪些点是我们首先需要关注的?
鉴于上面若干痛点,下面给出了一张更为实用的「性能优化工具图谱」,该图分别从系统层、应用层(含组件层)的角度出发,列举了我们在分析性能问题时首先需要关注的各项指标(其中?标注的是最需要关注的),这些点是最有可能出现性能瓶颈的地方。需要注意的是,一些低频的指标或工具,在图中并没有列出来,如 CPU 中断、索引节点使用、I/O事件跟踪等,这些低频点的排查思路较复杂,一般遇到的机会也不多,在这里我们聚焦最常见的一些就可以了。
对比上面的性能工具(Linux Performance Tools-full)图,下图的优势在于:把具体的工具同性能指标结合了起来,同时从不同的层次去描述了性能瓶颈点的分布,实用性和可操作性更强一些。系统层的工具分为CPU、内存、磁盘(含文件系统)、网络四个部分,工具集同性能工具(Linux Performance Tools-full)图中的工具基本一致。组件层和应用层中的工具构成为:JDK 提供的一些工具 + Trace 工具 + dump 分析工具 + Profiling 工具等。
这里就不具体介绍这些工具的具体用法了,我们可以使用 man 命令得到工具详尽的使用说明,除此之外,还有另外一个查询命令手册的方法:info。info 可以理解为 man 的详细版本,如果 man 的输出不太好理解,可以去参考 info 文档,命令太多,记不住也没必要记住:
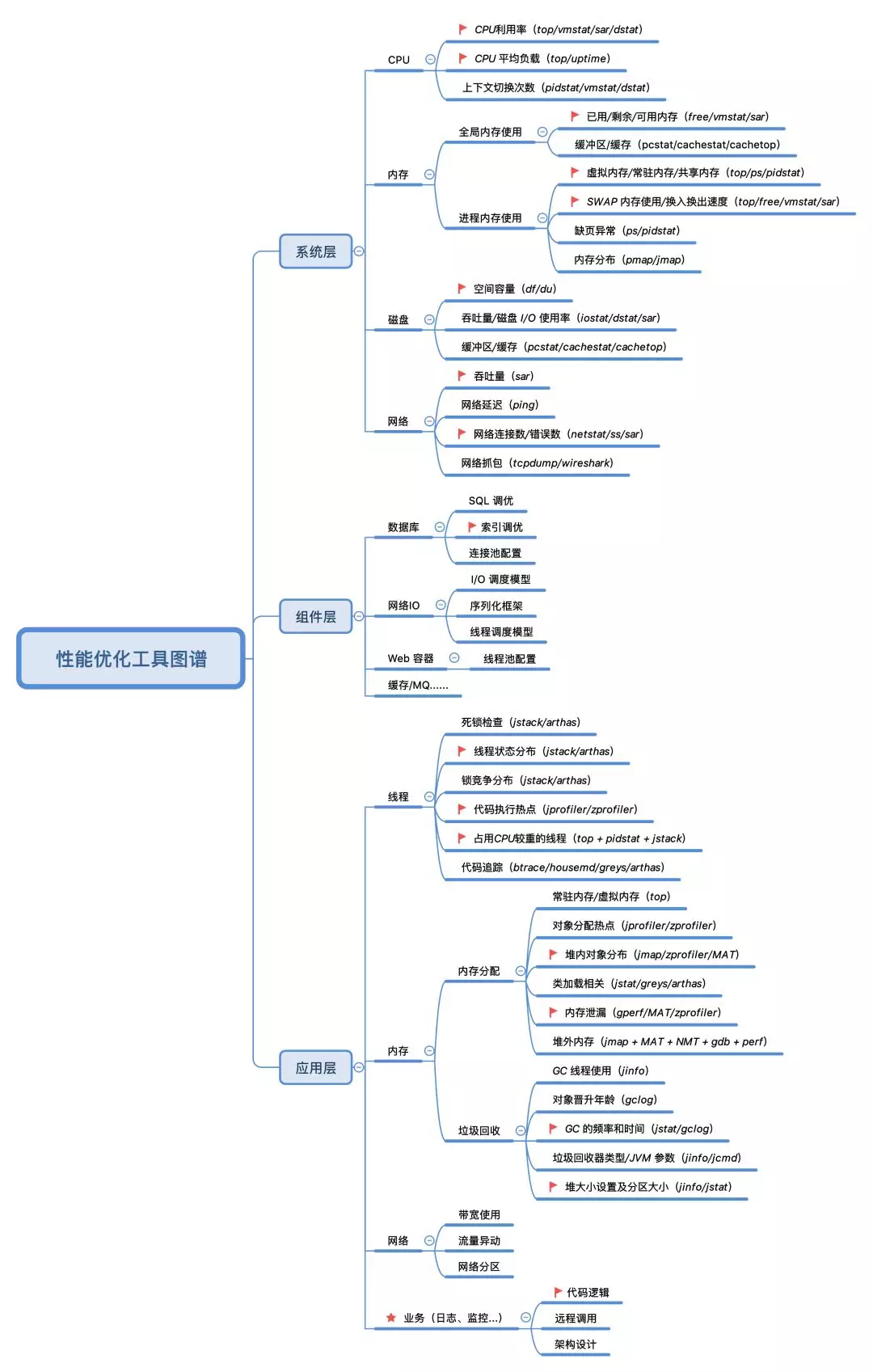
上面这张图该如何使用?下期再详细分享
四、常见调优思路有哪些?
在通过工具得到异常指标,初步定位瓶颈点后,如果进一步进行确认和调优?我们在这里提供一些可实践、可借鉴、可参考的性能调优「套路」,即:如何在众多异常性能指标中,找出最核心的那一个,进而定位性能瓶颈点,最后进行性能调优。以下会按照代码、CPU、内存、网络、磁盘等方向进行组织,针对对某一各优化点,会有系统的「套路」总结,便于思路的迁移实践。
1、代码相关
遇到性能问题,首先应该做的是检查否与业务代码相关——不是通过阅读代码解决问题,而是通过日志或代码,排除掉一些与业务代码相关的低级错误。性能优化的最佳位置,是应用内部。
2、 CPU 相关
我们更应该关注 CPU 负载,CPU 利用率高一般不是问题,CPU 负载 是判断系统计算资源是否健康的关键依据。
3、内存相关
内存分为系统内存和进程内存(含 Java 应用进程),一般我们遇到的内存问题,绝大多数都会落在进程内存上,系统资源造成的瓶颈占比较小。对于 Java 进程,它自带的内存管理自动化地解决了两个问题:如何给对象分配内存以及如何回收分配给对象的内存,其核心是垃圾回收机制。
4、磁盘I/O和网络I/O
以上是性能优化的流程详解,下篇再详细分享《性能常用优化工具实战》

