
自己的第一个网页
一、文件读写
Python对文本文件和二进制文件采用统一的操作步骤,即"打开—操作—关闭",打开不存在的文件可以创建文件,打开文件后文件处于占用状态,此时另一个进程不能操作这个文件。操作之后需要将文件关闭,关闭将释放对文件的控制使文件恢复存储状态
Python通过解释器内置的open函数打开一个文件,并实现该文件与一个程序变量的关联
<变量名>=open(<文件名>,<打开模式>)
文件使用结束后要使用close()方法关闭,使用方法:<变量名>.close()
文件内容的读取方法
|
操作方法 |
含义 |
|
<file>.read(size=-1) |
从文件中读入整个文件,如果给出参数,读入前size长度的字符串或字节流 |
|
<file>.readline(size=-1) |
从文件中读入一行内容,如果给出参数,读入该行前size长度的字符串或字节流 |
|
<file>.readlines(hint=-1) |
从文件中读入所有行,以每行为元素形成一个列表,如果给出参数,读入hint行 |
文件内容的写入方法
|
方法 |
含义 |
|
<file>.write(s) |
向文件写入一个字符串或字节流 |
|
<file>.write(lines) |
将一个元素全为字符串的列表写入文件 |
|
<file>.seek(offset) |
改变当前文件操作指针的位置,offset的值 0—文件开头 1—当前位置 2—文件结尾 |
实例代码
fname=input('请输入要写入的文件')
fo=open(fname,'w+')
ls=['2019','五四','一百周年','青年节']
fo.writelines(ls)
fo.seek(0)
for line in fo:
print(line)
fo.close()
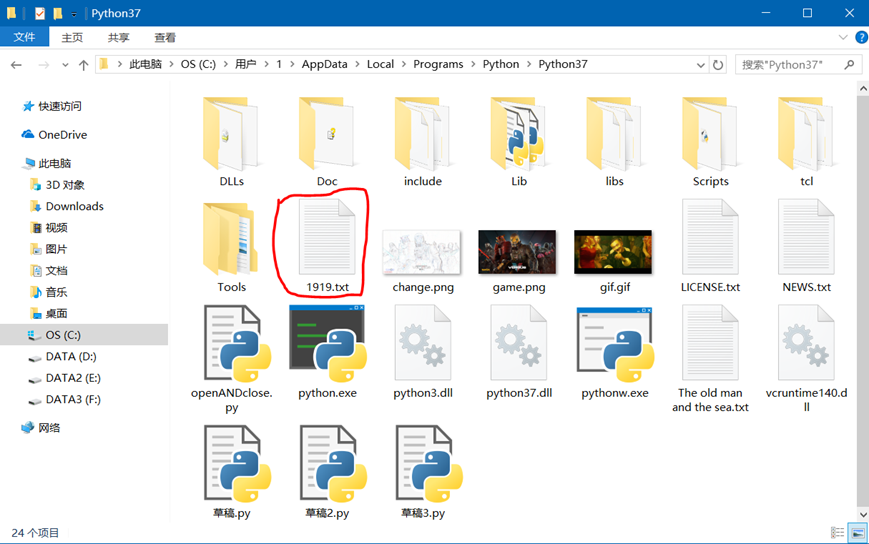
代码执行效果如下

因为1919.txt文件并不存在,而我们的打开模式是w+,所以会创建一个文件
二、xlsx格式文件转换为csv格式文件
代码如下
import pandas as pd
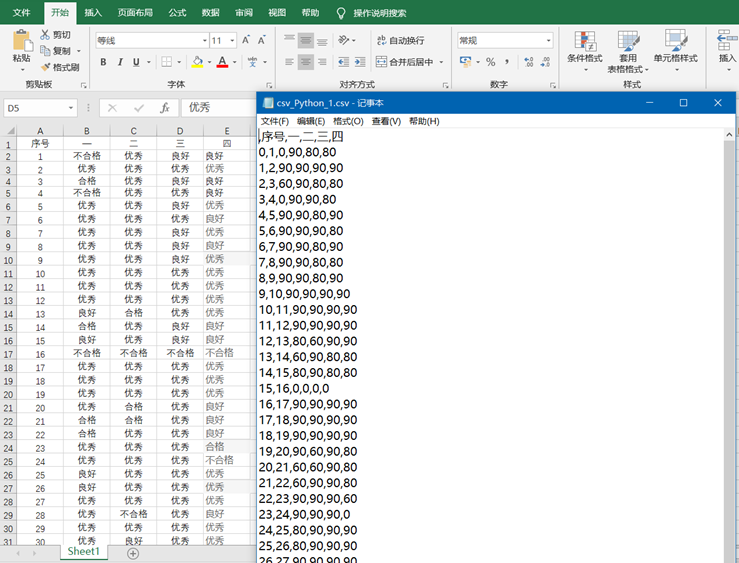
f=pd.read_excel('E:\\pythonHOMEWORK\\Python_1.xlsx')
f=f.replace('优秀','90')
f=f.replace('良好','80')
f=f.replace('合格','60')
f=f.replace('不合格','0')
f.to_csv('E:\\pythonHOMEWORK\\csv_Python_1.csv')
三、将CSV文件转换为html文件
HTML-超文本标记语言(Hyper Text Markup Language),标准通用标记语言下的一个应用。HTML 不是一种编程语言,而是一种标记语言(markup language),是网页制作所必备的。"超文本"就是指页面内可以包含图片、链接,甚至音乐、程序等非文字元素。超文本标记语言的结构包括"头"部分(英语:Head)、和"主体"部分(英语:Body),其中"头"部提供关于网页的信息,"主体"部分提供网页的具体内容。


以上,就是用python将成绩做各种处理得到的结果>_<
