【转】头插法和尾插法
HashMap在JDK1.8为什么改用使用尾插法
因为 1.7头插法扩容时,头插法会使链表发生反转,多线程环境下会产生环;
A 线程在插入节点 B,B 线程也在插入,遇到容量不够开始扩容,重新 hash,放置元素,采用头插法,后遍历到的 B 节点放入了头部,这样形成了环。
1、假设容器大小为2,数组0 的链表上初始有个 A节点。A线程和B线程同时插入B节点。
2、B线程cup占用、头指针指向A节点后 cup被A线程占用。
3、A线程插入节点B时,刚好hash 到数组0,则该链表 为 B —> A。
4、B线程 插入节点B时,发现内存不够,进行resize扩容操作,恰巧节点rehash后也是在同一个位置上。该方法实现的机制就是将每个链表转化到新链表,并且链表中的位置发生反转(链表转置)。现在为 A —> B。
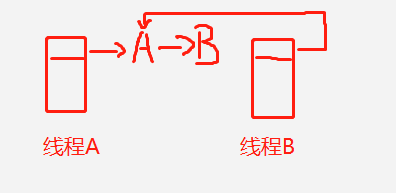
5、B实现插入节点B操作后就形成了环。
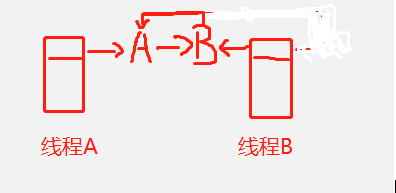
以上参考自:https://blog.csdn.net/weixin_42373997/article/details/112085344?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_baidulandingword-0&spm=1001.2101.3001.4242、https://blog.csdn.net/csdn_1107/article/details/108236495
以下转载自:https://blog.csdn.net/qq_40938077/article/details/80216563
方法1:头插法
基本思路:
定义一个链表类型的指针l,指针l指向的是链表的首地址,而不是链表的第一个数,指针l指向的下一个链表类型才是链表的第一个数,每次往链表中加数都加到链表中的第1个位置(即指针l指向的位置)。

代码:
最好自己看代码在纸上模拟一下过程
#include<bits/stdc++.h> using namespace std typedef struct Node { int value; struct Node *next; }node,*linkedlist; linkedlist linkedlistcreath()//返回的是该链表的地址 { node *l=(node*)malloc(sizeof(node)); l->next=NULL; int number; while (scanf("%d",&number)!=EOF) { node *p=(node*)malloc(sizeof(node));//新建一个node结构并为其申请空间 p->value=number;//给新建的node结构赋值 p->next=l->next;//赋值p所指的节点(就是l所指的节点,即链表的第2个节点) l->next=p;//将l所指的节点更新为p点 } return l;//返回头节点地址 }

方法2:尾插法
基本思路:
还是先定义一个链表类型的指针l,指针l指向的是链表的首地址,而不是链表的第一个数,指针l指向的下一个链表类型才是链表的第一个数,然后定义一个r指针,保证r指针始终指向链表的最后一个位置上的节点,然后让新加的节点加入到r指针指向的节点的后面。

代码如下:
最好自己看代码在纸上模拟一下过程
#include<bits/stdc++.h> using namespace std; typedef struct Node { int value; struct Node *next; } node,*linkedlist; linkedlist linkedlistcreatt()//返回的是该链表的地址 { node *l=(node*)malloc(sizeof(node)); l->next=NULL; node *r;//r指向的始终是该链表的最后一个node结构 r=l;//这个地方是地址之间的赋值,所以对r操作就相当于对l操作,即对链表最后一个node结构操作 int number; while (scanf("%d",&number)!=EOF) { node *p=(node*)malloc(sizeof(node));//新建一个node结构并为其申请空间 p->value=number;//给新建的node结构赋值 r->next=p;//将p插入到链表的最后一个node结构的后面 p->next=NULL;//此时p已经是链表的最后一个了,给p的next赋值 r=p;//让r等于链表的最后一个node结构,即p节点 } return l;//返回头节点的地址 }

转载:https://blog.csdn.net/qq_40938077/article/details/80216563

 浙公网安备 33010602011771号
浙公网安备 33010602011771号