在.NET Core中使用Irony实现自己的查询语言语法解析器
在之前《在ASP.NET Core中使用Apworks快速开发数据服务》一文的评论部分,.NET大神张善友为我提了个建议,可以使用Compile As a Service的Roslyn为语法解析提供支持。在此非常感激友哥给我的建议,也让我了解了一些Roslyn的知识。使用Roslyn的一个很大的好处是,框架无需依赖第三方的组件,并且Roslyn也是.NET Foundation的一个开源项目,为.NET语言提供编译服务,社区支持做的也非常出色。然而,经过一段时间的思考,我还是选择了一个折中的方案:在Apworks中使用Irony作为查询语言的语法解析器,与此同时,为查询语言语法解析提供可扩展的框架级支持。
那么问题来了:为什么我需要在Apworks中设计查询语言?Irony是什么?如何使用Irony实现自己的查询语言语法解析器?下面我就一一为大家介绍。
Apworks中的查询语言
很多体验过Apworks数据服务(Apworks Data Services)案例:TaskList的读者肯定有这样的感受:为什么每次我新建的任务项目(Task Item)都是出现在列表中不确定的位置?难道新建的任务就不应该放在最前面吗?是的,你的疑问没有错,在之前的TaskList中,的确存在这样的问题,因为那时候Apworks数据服务在返回任务列表时,还不支持查询和排序,也就是说,它只能默认以Id作为升序进行分页,返回所有的数据。当然,在最近一版的Apworks数据服务中,通过基于Irony的语法解析器,已经能够成功地支持查询和排序了。
如果你之前有仔细阅读《在ASP.NET Core中使用Apworks快速开发数据服务》一文,并按照文中的演练步骤实现过一个简单的RESTful服务的话,那么,请你重新在Visual Studio 2017中打开你的解决方案,将Apworks相关库更新到最新版本,然后不要修改任何代码,直接运行你的应用。等应用程序运行后,执行一次GET请求,URL中你就可以使用query作为查询条件输入了。比如,使用curl执行下面的命令:
curl -G "http://localhost:58928/api/customers" --data-urlencode "query=name sw \"fr\""
你将得到下面的结果:

可以看到,数据服务返回了所有Name字段以“fr”开头的客户信息。当然,还支持排序操作。比如执行下面的命令:
curl -G "http://localhost:58928/api/customers" --data-urlencode "sort=name d"
将得到下面的结果:

此时返回结果已经按Name字段倒序排列。
在Apworks中,查询语言支持以下操作和运算:
- 逻辑运算:AND OR NOT
- 关系运算:EQ(相等),NE(不等),LT(小于),LE(小于等于),GT(大于),GE(大于等于)
- 字符串运算:SW(以某字符串开头)、EW(以某字符串结尾)、CT(包含某字符串)
- 括号优先级
- 日期类型的比对
排序语言支持升序(用字母a表示)以及降序(用字母d表示),多个排序条件使用AND关键字连接。例如:name a AND email d,表示使用name字段做升序排序,并以email做降序排序。
以上就给大家大概介绍了一下Apworks数据服务对查询和排序的支持功能。设计这部分功能的需求是显而易见的:开发人员无需为一般的查询和排序功能自定义额外的接口。或许你会问,为何不使用已有的框架,比如OData。不错,OData的确可以提供统一的查询界面,做系统集成也会相对容易,但一方面我还是觉得OData太重,Apworks数据服务我希望能够提供更加简单便捷的功能;另一方面,看上去目前OData还不支持.NET Core(应该是不支持,我不太确定,有知道的朋友也欢迎留言指正)。
实现这套查询和排序语法,我使用的是一个.NET下开源的语法解析器生成工具集,它的名字叫做Irony。
Irony简介
Irony项目最开始是发布在微软的Codeplex代码托管服务上的,地址是:http://irony.codeplex.com/。在Codeplex上的好评数有51颗星,也已经很不错了。可惜的是,最近一次更新是在2013年12月,看起来已经停止维护了,不过之前使用了一下,感觉这个项目确实不错,不仅提供了开发库,而且还有一个图形化的语法解析器的测试工具,在写完自己的自定义语言的语法之后,还可以通过这个工具进行测试。于是,我把它迁移到了Github,成为我的一个公共repo,地址是:https://github.com/daxnet/irony。当然,我沿用了原有的MIT许可协议,并在首页的README.md中提供了原始地址(很可惜Codeplex将在年底关闭),并保留了开发者的名字。不仅如此,在一番踩坑之后,我把它迁移到了.NET Core平台。
在我的Irony Github Repo里,提供了一个非常简单的案例,就是实现四则混合运算的字符串解析,并计算最终结果。当然,这个案例也被包含在了这个项目的源代码里。大家可以自己下载查看。
Irony的一个特色就是运用了C#的运算符重载,使得语法定义借用了C#的编译功能(语法、类型检查等),简单直观,又不容易出错。比如,在如下案例中的语法定义类型中:
[Language("Expression Grammar", "1.0", "abc")]
public class ExpressionGrammar : Grammar
{
/// <summary>
/// Initializes a new instance of the <see cref="ExpressionGrammar"/> class.
/// </summary>
public ExpressionGrammar() : base(false)
{
var number = new NumberLiteral("Number");
number.DefaultIntTypes = new TypeCode[] { TypeCode.Int16, TypeCode.Int32, TypeCode.Int64 };
number.DefaultFloatType = TypeCode.Single;
var identifier = new IdentifierTerminal("Identifier");
var comma = ToTerm(",");
var BinOp = new NonTerminal("BinaryOperator", "operator");
var ParExpr = new NonTerminal("ParenthesisExpression");
var BinExpr = new NonTerminal("BinaryExpression", typeof(BinaryOperationNode));
var Expr = new NonTerminal("Expression");
var Term = new NonTerminal("Term");
var Program = new NonTerminal("Program", typeof(StatementListNode));
Expr.Rule = Term | ParExpr | BinExpr;
Term.Rule = number | identifier;
ParExpr.Rule = "(" + Expr + ")";
BinExpr.Rule = Expr + BinOp + Expr;
BinOp.Rule = ToTerm("+") | "-" | "*" | "/";
RegisterOperators(10, "+", "-");
RegisterOperators(20, "*", "/");
MarkPunctuation("(", ")");
RegisterBracePair("(", ")");
MarkTransient(Expr, Term, BinOp, ParExpr);
this.Root = Expr;
}
}
从中可以很容易理解:运算符(BinOp)包含+、-、*和/,而一个二元运算的表达式(BinExpr)由两个表达式(Expr)和一个运算符(BinOp)组成,而二元运算的表达式又是表达式(Expr)的一种。通过这样的语法定义,就可以使用Irony的Parser产生语法树了:
var language = new LanguageData(new ExpressionGrammar()); var parser = new Parser(language); var syntaxTree = parser.Parse(input);
怎么样,是不是非常方便?
在迁移Irony项目的同时,我还将Irony的测试工具Irony Grammar Explorer分离出来成为了一个单独的Github Repo。在你定义了上面的ExpressionGrammar类之后,编译你的程序集,然后就可以使用Irony Grammar Explorer进行测试了。比如,使用Irony Grammar Explorer打开Apworks.Querying.Parsers.Irony程序集,它将自动扫描程序集中所有的Grammar定义,然后让用户对各种Grammar进行测试。值得一提的是,在测试界面,Irony Grammar Explorer还能根据语法定义,自动产生语法高亮:

点击右边的语法树中的节点,即可定位到输入字符串的相应部分。比较有趣的一点是,在Irony Grammar Explorer的Github Repo里,还包含了一个语法定义的案例库:IronyExplorer.Samples,它包含了很多流行编程语言的语法定义。比如,下面是C# 3.5语言的语法测试效果:

有关Irony Grammar Explorer的其它功能,我就不一一介绍了,大家可以自己实践一下。总的来说,Irony可以帮助大家快速方便地实现语法解析器,而且功能也能够满足绝大多数需求,针对.NET Core的支持,也使得Irony能够直接被应用在跨平台的.NET应用程序中,并支持Docker部署。接下来的问题就更有趣了:我已经定义了自己的语法,并使用Irony Grammar Explorer通过了测试,接下来,我如何在我的应用程序中运用这个语法?换个方式问:我拿到了语法树后,该怎么办呢?
语法树的处理
虽然我们能够将字符串文本解析成一棵语法树,能够通过语法树来体现一个字符串中各个部分的含义,以及它们之间的关系,但是如何能够让计算机来读懂这棵树,并执行相应的任务呢?这就涉及到语法树的处理问题。参考编译原理,词法分析和语法分析已经由Irony完成,接下来的语义分析,就需要我们自己写代码了。
在Irony Repo的案例代码中,我们的目的是能够解析一个四则运算表达式,并计算出结果,于是,我们定义了下面的对象模型:
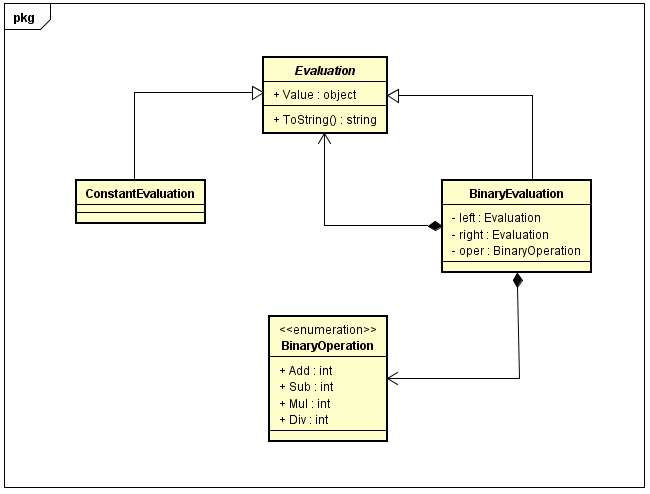
因此,只需要将解析的语法树转换成上面的对象模型,也就能够通过Evaluation.Value属性,得到计算的最终结果。从代码上看,向对象模型的转换,是通过递归的方式遍历语法树实现的:
private Evaluation PerformEvaluate(ParseTreeNode node)
{
switch (node.Term.Name)
{
case "BinaryExpression":
var leftNode = node.ChildNodes[0];
var opNode = node.ChildNodes[1];
var rightNode = node.ChildNodes[2];
Evaluation left = PerformEvaluate(leftNode);
Evaluation right = PerformEvaluate(rightNode);
BinaryOperation op = BinaryOperation.Add;
switch (opNode.Term.Name)
{
case "+":
op = BinaryOperation.Add;
break;
case "-":
op = BinaryOperation.Sub;
break;
case "*":
op = BinaryOperation.Mul;
break;
case "/":
op = BinaryOperation.Div;
break;
}
return new BinaryEvaluation(left, right, op);
case "Number":
var value = Convert.ToSingle(node.Token.Text);
return new ConstantEvaluation(value);
}
throw new InvalidOperationException($"Unrecognizable term {node.Term.Name}.");
}
以上完整代码请参考Evaluator的实现。整个案例及使用方式可以点击https://github.com/daxnet/irony#example查看。可以看到,使用Irony来实现一个四则混合运算的计算器还是非常方便的。
在Apworks中,我们需要的是能够将一个表达查询语义的语法树,转换成Lambda表达式,以便于后台数据库引擎能够直接执行Lambda表达式完成查询。通过数据库引擎执行Lambda表达式的优势是非常明显的,比如Entity Framework Core可以通过Lambda表达式生成高效的SQL语句并在数据库服务器上执行,性能方面也能兼顾得非常好。
类似的,我们使用.NET Expression的对象模型,通过遍历查询语句的语法树来生成表达式模型,最后转换成Lambda表达式即可。具体过程就不再赘述了,请参考Apworks的源代码。现在我们来看看实际效果。
假设我们的测试数据如下:
Customers.Add(new Customer { Id = 1, Email = "jim@example.com", Name = "jim", DateRegistered = DateTime.Now.AddDays(-1) });
Customers.Add(new Customer { Id = 2, Email = "tom@example.com", Name = "tom", DateRegistered = DateTime.Now.AddDays(-2) });
Customers.Add(new Customer { Id = 3, Email = "alex@example.com", Name = "alex", DateRegistered = DateTime.Now.AddDays(-3) });
Customers.Add(new Customer { Id = 4, Email = "carol@example.com", Name = "carol", DateRegistered = DateTime.Now.AddDays(-4) });
Customers.Add(new Customer { Id = 5, Email = "david@example.com", Name = "david", DateRegistered = DateTime.Now.AddDays(-5) });
Customers.Add(new Customer { Id = 6, Email = "frank@example.com", Name = "frank", DateRegistered = DateTime.Now.AddDays(-6) });
Customers.Add(new Customer { Id = 7, Email = "peter@example.com", Name = "peter", DateRegistered = DateTime.Now.AddDays(-7) });
Customers.Add(new Customer { Id = 8, Email = "paul@example.com", Name = "paul", DateRegistered = DateTime.Now.AddDays(1) });
Customers.Add(new Customer { Id = 9, Email = "winter@example.com", Name = "winter", DateRegistered = DateTime.Now.AddDays(2) });
Customers.Add(new Customer { Id = 10, Email = "julie@example.com", Name = "julie", DateRegistered = DateTime.Now.AddDays(3) });
Customers.Add(new Customer { Id = 11, Email = "jim@example.com", Name = "jim", DateRegistered = DateTime.Now.AddDays(4) });
Customers.Add(new Customer { Id = 12, Email = "brian@example.com", Name = "brian", DateRegistered = DateTime.Now.AddDays(5) });
Customers.Add(new Customer { Id = 13, Email = "david@example.com", Name = "david", DateRegistered = DateTime.Now.AddDays(6) });
Customers.Add(new Customer { Id = 14, Email = "daniel@example.com", Name = "daniel", DateRegistered = DateTime.Now.AddDays(7) });
Customers.Add(new Customer { Id = 15, Email = "jill@example.com", Name = "jill", DateRegistered = DateTime.Now.AddDays(8) });
下面调试单元测试,并查看所产生的Lambda表达式,可以看到,Lambda表达式正确产生,测试顺利通过:

总结
本文介绍了Apworks中自定义查询语句在Apworks数据服务中的应用,并介绍了查询语句和排序语句的实现方式,与此同时对Irony Grammar Parser进行了介绍。Apworks中查询语句的实现还是相对简单的,目前不支持内嵌对象的属性查询,比如Customer.Address.Country EQ “China” 这样的查询是不支持的。为了保证实现过程相对简单快速,今后也不打算支持。如果需要用到这种内嵌对象属性的查询,请扩展DataServiceController以实现自己的特定API来完成。
接下来我会介绍Entity Framework Core在Apworks数据服务中的使用(虽然已经预告了好几次了-_-!!)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号