kafka集群操作
搭建kafka集群(三个broker)
- 创建三个server.properties文件:
这里直接复制然后重命名原来的那个server.properties文件即可。
cp server.properties server1.properties
cp server.properties server2.properties
- 然后修改以下参数:
原来server.properties的参数:
#server1.properties
broker.id=0
listeners=PLAINTEXT://127.0.0.1:9093
advertised.listeners=PLAINTEXT://127.0.0.1:9093
log.dir=/home/admin/apps/kafka/data/kafka-logs
另外两个配置文件的参数:
#server1.properties
broker.id=1
listeners=PLAINTEXT://127.0.0.1:9094
advertised.listeners=PLAINTEXT://127.0.0.1:9094
log.dir=/home/admin/apps/kafka/data/kafka-logs-1
#server1.properties
broker.id=2
listeners=PLAINTEXT://127.0.0.1:9095
advertised.listeners=PLAINTEXT://127.0.0.1:9095
log.dir=/home/admin/apps/kafka/data/kafka-logs-2
- 在data目录中新建两个目录
cd data
mkdir kafka-logs-1
mkdir kafka-logs-2
- 启动kafka集群
启动zookeeper
./zookeeper-server-start.sh ../config/zookeeper.properties
启动kafka
#以守护进程的方式启动
./kafka-server-start.sh -daemon ../config/server.properties
./kafka-server-start.sh -daemon ../config/server1.properties
./kafka-server-start.sh -daemon ../config/server2.properties
- 查看kafka集群状态
因为kafka中的broker都是依靠zookeeper来维护,所以要查看kafka的broker,得通过zookeeper来查看。
首先要连接到zookeeper
./zookeeper-shell.sh 127.0.0.1:2182
查看broker的id
ls /brokers/ids
查询结果如下:
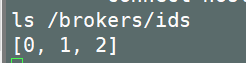
可以发现broker有三个id,刚好对应到我们创建的三个broker。
自此,kafka集群搭建成功!
副本的概念
在创建主题时,除了指明了主题的分区数以外,还指明了副本数,那么副本是⼀个什么概念呢?
下面我们创建有3个副本2个分区的topic:
./kafka-topics.sh --create --zookeeper 127.0.0.1:2182 --replication-factor 3 --partitions 2 --topic my-replicated-topic
副本是为了为主题中的分区创建多个备份,多个副本在kafka集群的多个broker中,会有⼀个副本作为leader,其他是follower。
查看topic情况:
./kafka-topics.sh --describe --zookeeper 127.0.0.1:2182 --topic my-replicated-topic

可以发现,我们刚刚创建的主题中包含2个分区和个副本。
0号分区的leader是1号副本,那么2号和0号副本都是follower。
0号分区的leader是2号副本,那么0号和1号副本都是follower。
剖析图:

-
leader:
kafka的写和读的操作,都发⽣在leader上。leader负责把数据同步给follower。当leader挂了,经过主从选举,从多个follower中选举产⽣⼀个新的leader。 -
follower
接收leader的同步的数据。 -
isr:
可以同步和已同步的节点会被存⼊到isr集合中。这⾥有⼀个细节:如果isr中的节点性能较差,会被踢出isr集合。 -
注意:
集群中有多个broker,创建主题时可以指明主题有多个分区(把消息拆分到不同的分区中存储),可以为分区创建多个副本,不同的副本存放在不同的broker⾥。
集群消费
(1)向集群中发送消息
./kafka-console-producer.sh --broker-list 127.0.0.1:9093,127.0.0.1:9094,127.0.0.1:9095 --topic my-replicated-topic
(2)从集群中消费消息
./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9093,127.0.0.1:9094,127.0.0.1:9095 --from-beginning --topic my-replicated-topic
(3)指定消费组来消费消息
./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9093,127.0.0.1:9094,127.0.0.1:9095 --from-beginning --consumer-property group.id=testGroup1 --topic my-replicated-topic
运行结果:


(4)分区分消费组的集群消费中的细节

- ⼀个partition只能被⼀个消费组中的⼀个消费者消费,⽬的是为了保证消费的顺序性,但是多个partion的多个消费者消费的总的顺序性是得不到保证的,那怎么做到消费的总顺序性呢?
- partition的数量决定了消费组中消费者的数量,建议同⼀个消费组中消费者的数量不要超过partition的数量,否则多的消费者消费不到消息。
- 如果消费者挂了,那么会触发rebalance机制,会让其他消费者来消费该分区。
kafka知识点目录
1.Linux环境部署kafka
2.Win10环境部署kafka
3.docker部署kafka
4.kafka的简单使用
5.kafka消息的细节
6.kafka主题和分区的概念
7.kafka集群操作
8.kafka生产者实现细节
9.kafka消费者实现细节
10.kafka集群中的controller、rebalance、HW
11.kafka中的优化问题
12.Kafka-eagle监控平台
13.kafka错误汇总

 浙公网安备 33010602011771号
浙公网安备 33010602011771号