
二次规划问题和常见求解框架
二次规划问题
Quadratic Program,QP
二次规划问题是非线性规划(Non-linear program,NLP)问题的特例,即当目标函数 为二次型且约束 , 在 为线性约束时的 NLP 问题即为 QP 问题,其一般形式如下:
上式中, 是对称矩阵, , , ,
相关术语
-
二次型,正定矩阵
-
二次型 ,其中对称矩阵 ; 二次型 和对称矩阵 具有一一对应关系
-
若 , 则二次型 为正定二次型; 正定二次型的充要条件为 其对应的对称矩阵的所有特征值大于 0; 或者其对应的对称矩阵的各阶主子式均为正
-
-
海森(Hessian)矩阵
- 假设有函数 ,如果在定义域中其二阶偏导数存在且连续,那么 的 Hessian 矩阵为一个 的方阵,定义为 , 根据二阶连续偏导和求导次序无关可知,Hessian 矩阵为对称矩阵。
LASSO 问题
LASSO 回归问题是在线性回归问题的基础上,加上 范数约束,来限制线性拟合的系数,保持一定的稀疏性。相比于岭回归 ( 范数约束),LASSO 回归对离群极端值具有较好的鲁棒性。LASSO 问题的形式如下:
其中 为系数向量 , 是数据矩阵, 是惩罚项权重。
LASSO 问题的等价二次规划问题为
半二次分裂算法
Half quadratic splitting,HQS
变量分裂法(Variable Spliting)
用于解决目标函数是两个函数之和的优化问题,如假设 g 是 n 维向量到 d 维向量的一个映射,优化目标函数为:
可以通过变量分裂将上式变为:
变量分裂之后可能比原问题更好解决。
半二次分裂
通常是将正则项中的原始变量进行变量替换,而后通过增广拉格朗日法(Augmented Lagrange Method,ALM)重写目标函数(包含原数据保真项,拉格朗日乘子项和二次惩罚项,这么做的目的是解耦的同时,简化计算。 图像复原中,目标函数为:
前一项为数据保真项(fidelity),后一项为惩罚项,通常只与去噪有关。通过 HQS 算法,引入辅助变量 z,把惩罚项的 x 替换为 z,并添加相应的等式约束条件:
由增广拉格朗日法(Augmented Lagrange Method,ALM)得到增广拉格朗日函数:
迭代求解:
两个子问题将原问题的保真项和先验项解耦分别求解。
(加速)迭代收缩阈值算法
(Fast) iterative shrinkage-thresholding algorithm, (F)ISTA
近端梯度下降
Proximal Gradient Algorithm, PGD
对于包含不可微部分的优化目标如 lasso 回归的求解,梯度下降等算法已不再适用。近端梯度下降即被用来解决包含不可导项的优化问题。研究如下问题:
其中, 是连续可导凸函数; 是连续的凸函数,可以是不光滑的(不可导,not necessarily differentiable)。对于函数 ,将其在 处做二阶泰勒展开,将其用来近似原函数得:
二阶导相对一阶导要难求很多,并且从时间复杂度的角度上来讲,求二阶导信息即 Hessian 矩阵要花去许多时间。根据Lipschitz continuous gradient,我们将二阶导用 代替,其中 , 为 n 阶单位矩阵,则
设原问题最优解为 ,则带入上式到原问题,并抛掉常数 ,凑平方得
定义临近点算子/近端算子 (proximal operator) 如下:
等价定义如下:
利用近端算子可以将原问题的最优解写为:
写为迭代求解形式(近端梯度下降的核心公式)为:
针对不同的 ,如 范数、 范数、 范数、二次函数等,近端算子都有着对应的闭式解 (closed-form)(或者说显式解),下面列出了几个简单的情况:
时, 时,,Elementwise hard-thresholding (硬阈值函数)
时,,Elementwise soft-thresholding (软阈值函数)
时,,Elementwise soft-thresholding (软阈值函数)
有时候在不同论文里面会看到 这种数学表达式,它其实就等价于
迭代收缩阈值算法
iterative shrinkage-thresholding algorithm,ISTA
一般的,我们将解决上述含不可导项的优化问题的近端梯度下降算法成为 ISTA 算法。具体应用中,ISTA 算法狭义上一般指不可导项为 范数的 LASSO 问题。
LASSO 问题中使用了 范数,故对应 的情况,此时的近端梯度下降迭代表达式可以写成:
其中 称为软阈值算子(soft-thresholding operator),也常写作 ,可以看到该算子即为近端算子中 的情况。
若 为标量,则有:
若 为向量,则 ,即为每个分量均做软阈值操作。进一步可以推导出如下表达式:
其中, 为对向量 的每个分量取绝对值后组成的向量; 表示取正,即 ; 表示两个矩阵的 Hadamard 乘积(element-wise product)。
软阈值迭代算法 (ISTA, iterative soft-thresholding algorithm),即为用软阈值作为包含 范数的目标函数的“梯度”,使用”梯度下降“来得到最优值的算法。回顾 LASSO 优化问题,可以得到:
所以 ISTA 算法的迭代公式为:
算法流程如下(该算法流程为一般形式的 ISTA 算法流程,即近端算子 为不可导项 对应的近端算子,特殊的,当不可导项 为 范数时,,下同):

ISTA 算法还有一种推广形式的迭代公式:
其中 。原始 ISTA 算法的迭代形式可以看做 的特例。当 或者 时可以将推广形式看做原始形式的 over/under related 版本。
文献中已经证明,当迭代步长取 的 Lipschitz 常数的倒数(即 )时,由 ISTA 算法生成的序列 的收敛速度为 显然为次线性收敛速度。然而固定步长的 ISTA 的缺点是:Lipschitz 常数 不一定可知或者可计算。例如,L1 范数约束的优化问题,其 Lipschitz 常数依赖于 的最大特征值。而对于大规模的问题,非常难计算。因此出现了 ISTA 算法的 Backtracking 版本,通过不断收缩迭代步长的策略使其收敛,算法流程如下:

加速迭代收缩阈值算法
fast iterative shrinkage-thresholding algorithm, FISTA
为了加速 ISTA 算法的收敛,文献中作者采用了著名的梯度加速策略Nesterov加速技术,使得 ISTA 算法的收敛速度从 变成 ,加速的 ISTA 算法称为 FISTA。FISTA 与 ISTA 算法相比,仅仅多了个 Nesterov 加速步骤,以极少的额外计算量大幅提高了算法的收敛速度。而且不仅在 FISTA 算法中,在几乎所有与梯度有关的算法中,Nesterov 加速技术都可以使用。FISTA 的算法流程如下:

当然,考虑到与 ISTA 同样的问题:问题规模大的时候,决定步长的 Lipschitz 常数计算复杂。FISTA 与 ISTA 一样,亦有其回溯算法。在这个问题上,FISTA 与 ISTA 并没有区别,上面也说了,FISTA 与 ISTA 的区别仅仅在于每一步迭代时近似函数起始点的选择。更加简明的说:FISTA 用一种更为聪明的办法选择序列 ,使得其基于梯度下降思想的迭代过程更加快速地趋近问题函数 的最小值。
带回溯的 FISTA 算法基本迭代步骤如下:

值得注意的是,在每一步迭代中,计算近似函数的起止点时,FISTA 使用前两次迭代过程的结果 ,对其进行简单的线性组合生成下一次迭代的近似函数起始点 yk。方法很简单,但效果却非常好。当然,这也是有理论支持的。关于 ISTA 和 FISTA 的具体理论推导可以看 原论文。
两步迭代收缩阈值算法
Two-step iterative shrinkage/thresholding, TwIST
TwIST 算法是 ISTA 算法的改进算法,其 two-step 是指该算法的每次迭代都依赖于前两次迭代的结果,而不仅是前一次迭代的结果。(F)ISTA 算法的收敛速度对线性观测矩阵具有很强的依赖性,当观测矩阵十分病态(ill-posed)时,该算法的收敛速度会很慢。TwIST 通过引入两步(或者说二阶, second order)非线性迭代策略克服了 ISTA 收敛速度的问题,在病态问题的求解中具有更快的收敛速度。 定义优化目标函数:
该目标函数是线性逆问题求解中的常规形式。其中, 是观察数据, 是一个线性操作符, 是一个正则项。该目标函数的第一项为数据保真项,第二项为先验项,二者通过正则化参数 控制权重。
TwIST 算法的迭代公式为:
对于 , 定义为
其中 (去噪函数,Moreau proximal mapping)定义为
当 时, 即为软阈值函数。更一般的,当 时为全变分(total variation, TV)、加权 范数以及加权 范数的 次方时对应的 的推导见 原论文。
广义交替投影算法
Generalized alternating projection, GAP
考虑优化问题:
该优化问题的本质为寻找一个和给定的线性流形(优化函数第二项)有非空交集的最小加权 范数球(优化函数第一项)。可以通过一系列交替投影求解该问题,引入辅助变量 将该问题先进行转化:
其中, 是与 有关的 Lagrangian 乘子。通过对 进行交替更新可以求解上述优化问题。具体来说,给定 时, 的更新是 在线性流形上的一个 Euclidean projection; 给定 , 的更新可以通过对 进行 groupwise 的 shrinkage(软阈值操作)来获得,两种情况下的更新都有解析(closed-form)解。具体迭代公式如下(假设 可逆):
其中关于 的更新较为复杂,详细推导见 原论文。(关于第二步中 Euclidean projection 解析解的推导:当给定 时,更新 的时候,求解的问题变为 ,通过变量替换 ,该问题变为矩阵分析中典型的最小范数解的问题,有相应的解析解,带入并反求 即得)
交替方向乘子法
Alternating direction method of multipilers, ADMM
考虑优化问题:
ADMM 的算法流程为:
关于 ADMM 的推导过程建议参考 ADMM算法的详细推导过程是什么? - 覃含章的回答
关于在实际场景中如果将问题转换为 ADMM 形式来求解,推荐参考 交替方向乘子法(ADMM)算法的流程和原理是怎样的? - 门泊东吴的回答,下面摘录其中一例,求解含有 范数的优化问题:
s 首先引入辅助变量 将上述问题转换为 ADMM 可以求解的形式:
使用 ADMM 的求解流程为:
其中 是软阈值函数。对于 LASSO 问题,上述 ,则 的解析解可以写成:
算子分裂二次规划求解算法
Operator splitting solver for quadratic programs, OSQP
考虑一般的(凸)二次规划(quadratic program,QP)问题:
其中
如果集合 ,其中 ,则上述问题转化为:
当 对所有元素均成立,或者对部分元素成立时,相应约束即变为等式约束。
将上述问题转换为可以利用 ADMM 算法求解的形式:
其中:
利用 ADMM 算法可以将上述优化问题分为三步迭代求解:
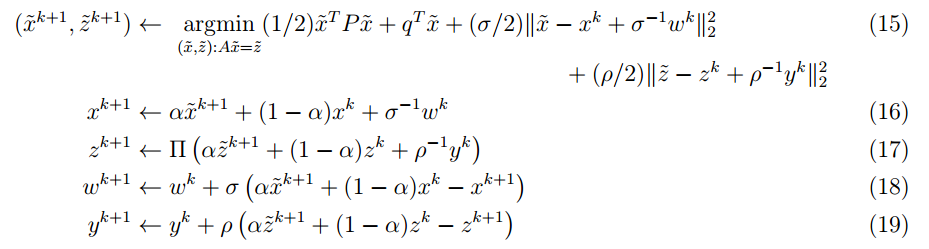
其中 为步长参数, 是松弛参数, 表示向 集合上的欧几里得投影(Euclidean projection)。根据 (16) 和 (18) 可以推出来 ,所以表示 的迭代更新的 (18) 式可以去掉。上述迭代的关键步骤在于 (15) 式,通过 KKT 条件可以推出其解析解为:
具体推导见 原论文。OSQP 算法的迭代步骤具体如下:

上述迭代步骤中,除了步骤 3 之外都很简单,因为它们仅包含向量加减,数乘以及投影操作,而且都是 component-wise separable 的操作,能够很容易的进行并行。下面以 LASSO 问题为例,将其转换为可以用 OSQP 求解的二次规划问题形式:
LASSO 问题的一般形式为:
其中, 是参数向量, 是数据矩阵, 是权重参数。将该问题转换为二次规划问题:
其中 是两个新引入的变量。转化为二次规划形式后的 LASSO 问题即可以用上述 OSQP 算法求解。
附录 Appendix
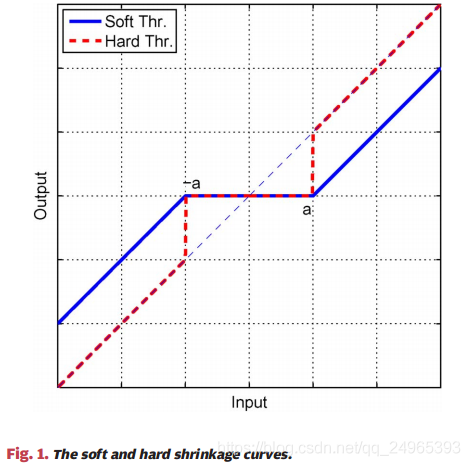
软阈值算子和硬阈值算子
soft-thresholding operator, hard-thresholding operator
软阈值算子的表达式
硬阈值算子的表达式
二者的图像如下:
Lipschitz 常数和 Lipschitz 连续
利普希茨连续的定义是:如果函数 在区间 上以常数 利普希茨连续,那么对于 ,有:
其中常数 称为 在区间 上的 Lipschitz 常数。除了 Lipschitz continuous 之外,Lipschitz continuous gradient 和 Lipschitz continuous Hessian 也是常用到的概念,它们都是由 Lipschitz continuous 概念延伸出来的。值得一提的是,很多论文中,尤其是关于凸优化的问题,Lipschitz continuous gradient的应用更为常见。
其中,如果函数 满足 Lipschitz continuous gradient,就意味着它的导数 满足 Lipschitz continuous,即如果函数 满足 Lipschitz continuous gradient,则:
其中,如果函数 满足 Lipschitz continuous Hessian,就意味着它的二阶导数 满足 Lipschitz continuous,即如果函数 满足 Lipschitz continuous Hessian,则:
从上面的定义中可以看出,利普希茨连续限制了函数 的局部变动幅度不能超过某常量。同样的道理,Lipschitz continuous gradient 和 Lipschitz continuous Hessian 则限制了函数的导函数和二阶导函数的局部变化幅度。
根据上述第二种 Lipschitz continuous gradient 条件可以有以下定理:
如果函数 在 上满足 Lipschitz continuous gradient,则对于任意 有:
根据上面的公式,去掉绝对值可以得到等价表达:
其余两种 Lipschitz continuous 条件也有相应的定理,具体定理与证明见 论文。
Nesterov 加速技术
Nesterov 加速技术由大神 Yurii Nesterov (内斯特罗夫) 于 1983 年提出来的,它与目前深度学习中用到的经典的动量方法(Momentum method)很相似,和动量方法的区别在于二者用到了不同点的梯度,动量方法采用的是上一步迭代点的梯度,而 Nesterov 方法则采用从上一步迭代点处朝前走一步处的梯度。在几乎所有与梯度有关的算法中,Nesterov 加速技术都可以使用。具体对比如下。
动量方法:
Nesterov 方法:
Reference
- HQS——Half Quadratic Splitting半二次方分裂
- 近端梯度下降与软阈值迭代:PGD and ISTA
- 软阈值迭代算法(ISTA)和快速软阈值迭代算法(FISTA)
- LASSO回归与L1正则化 西瓜书
- 【优化】利普希茨连续(Lipschitz continuous)及其应用
- FISTA的由来:从梯度下降法到ISTA & FISTA
- Nesterov加速和Momentum动量方法
- IST改进算法之Two-Step Iterative Shrinkage/Thresholding(TwIST)
- 交替方向乘子法(ADMM)算法的流程和原理是怎样的?
- ADMM算法的详细推导过程是什么? - 覃含章的回答
- 交替方向乘子法(ADMM)算法的流程和原理是怎样的? - 门泊东吴的回答
- Xiaotian13的博客 -凸优化
- Beck, Amir, and Marc Teboulle. “A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems.” SIAM Journal on Imaging Sciences 2, no. 1 (January 2009): 183–202. https://doi.org/10.1137/080716542.
- Bioucas-Dias, J.M., and M.A.T. Figueiredo. “A New TwIST: Two-Step Iterative Shrinkage/Thresholding Algorithms for Image Restoration.” IEEE Transactions on Image Processing 16, no. 12 (December 2007): 2992–3004. https://doi.org/10.1109/TIP.2007.909319.
- Zhou, Xingyu. “On the Fenchel Duality between Strong Convexity and Lipschitz Continuous Gradient.” ArXiv:1803.06573 [Math], March 17, 2018. http://arxiv.org/abs/1803.06573.
- Liao, Xuejun, Hui Li, and Lawrence Carin. “Generalized Alternating Projection for Weighted- Minimization with Applications to Model-Based Compressive Sensing.” SIAM Journal on Imaging Sciences 7, no. 2 (January 2014): 797–823. https://doi.org/10.1137/130936658.
- Stellato, Bartolomeo, Goran Banjac, Paul Goulart, Alberto Bemporad, and Stephen Boyd. “OSQP: An Operator Splitting Solver for Quadratic Programs.” Mathematical Programming Computation 12, no. 4 (December 2020): 637–72. https://doi.org/10.1007/s12532-020-00179-2.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步