SQL Server 分页编号的另一种方式
今天看书讲T-SQL,看到了UNBOUNDED PRECEDING,就想比对下ROW_NUMBER()的运行速度。
sql及相关的结果如下,数据库中的数据有5W+。
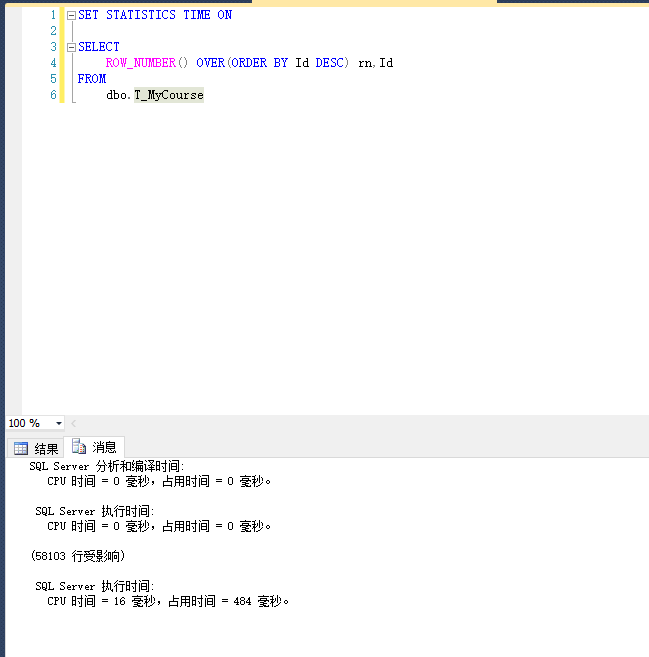
ROW_NUMBER():
SET STATISTICS TIME ON SELECT ROW_NUMBER() OVER(ORDER BY Id DESC) rn,Id FROM dbo.T_MyCourse
运行结果
UNBOUNDED PRECEDING
SET STATISTICS TIME ON SELECT SUM(1) OVER(ORDER BY Id DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) rn,Id FROM dbo.T_MyCourse
运行结果
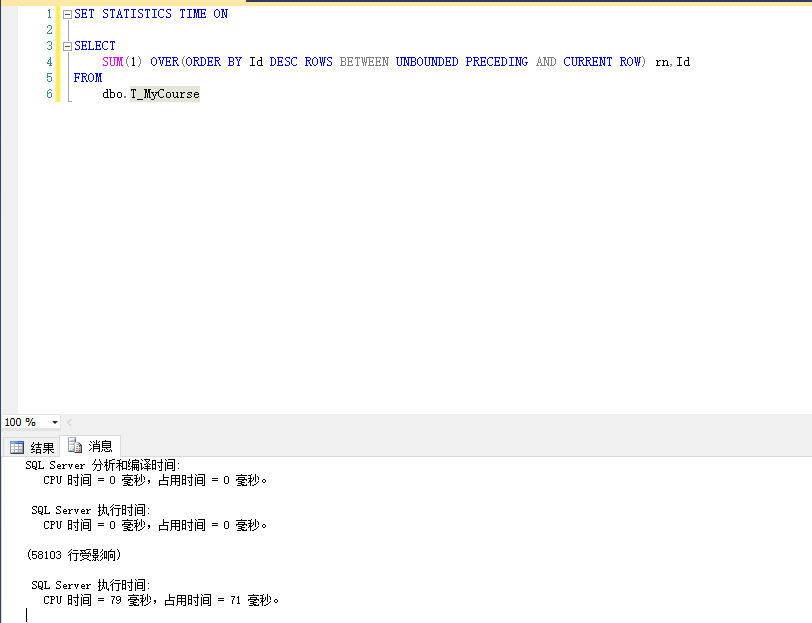
通过运行之后,看到结果,使用微软官方提供的方法进行编号排序,速度明显的提高。
不过我使用上述方法进行分页获取数据的时候结果又有点不一样。
分页获取数据:
ROW_NUMBER() 分页获取数据:
SET STATISTICS TIME ON SELECT * FROM ( SELECT ROW_NUMBER() OVER(ORDER BY Id DESC) rn,Id FROM dbo.T_MyCourse )a WHERE a.rn BETWEEN 55 AND 444

执行sql命令:DBCC DROPCLEANBUFFERS ,清除数据库缓存后的结果

UNBOUNDED分页获取数据:
SET STATISTICS TIME ON SELECT * FROM ( SELECT SUM(1) OVER(ORDER BY Id DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) rn,Id FROM dbo.T_MyCourse )a WHERE a.rn BETWEEN 22 AND 444

UNBOUNDED这个方式下执行了DBCC DROPCLEANBUFFERS 清除缓存的sql也没有用,执行时间没有变化。
通过上述结果,看到ROW_NUMBER()获取分页的数据明显更快,我猜测是微软对ROW_NUMBER()这个方法做了优化,可能是有缓存,读取的缓存中的数据然后进行分页。
如果有知道的网友,请评论告诉我,让我学习学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号