
Scrapy框架基本使用_对内容提取出来的url的进一步跟进
- 创建项目

- 创建爬虫


- 项目结构
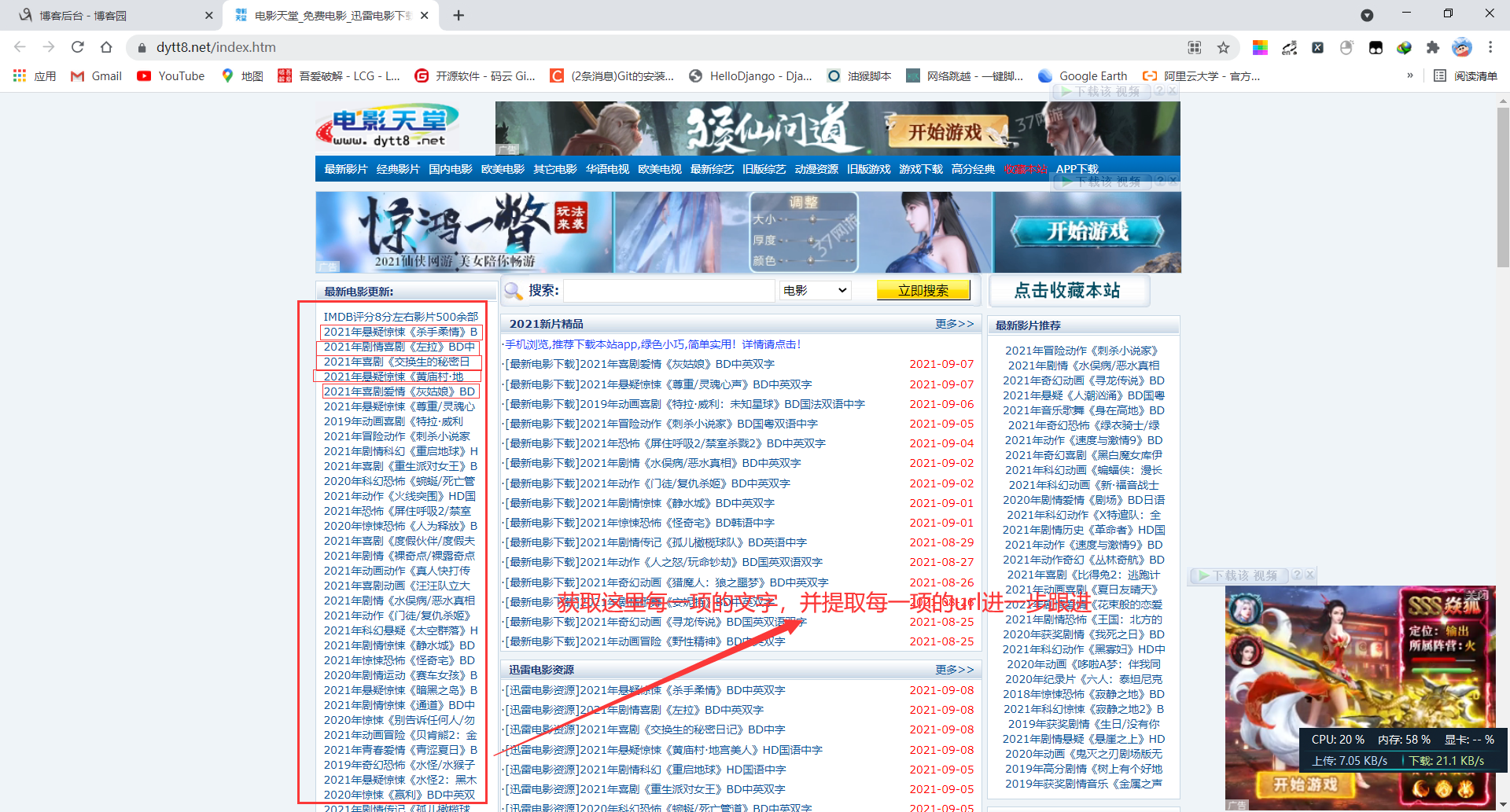
- 规定要爬取的内容,如下
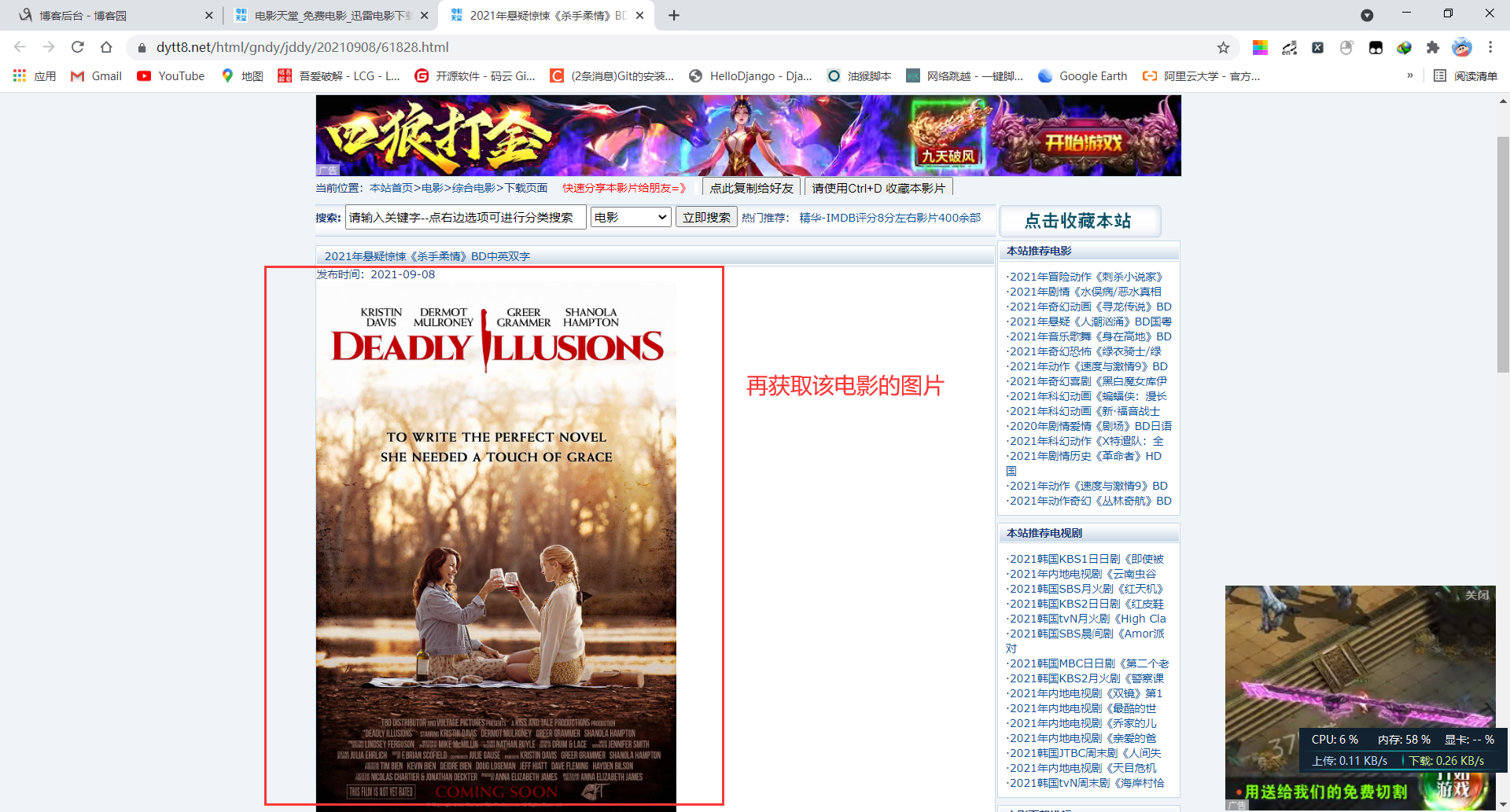
随便点击一项进入
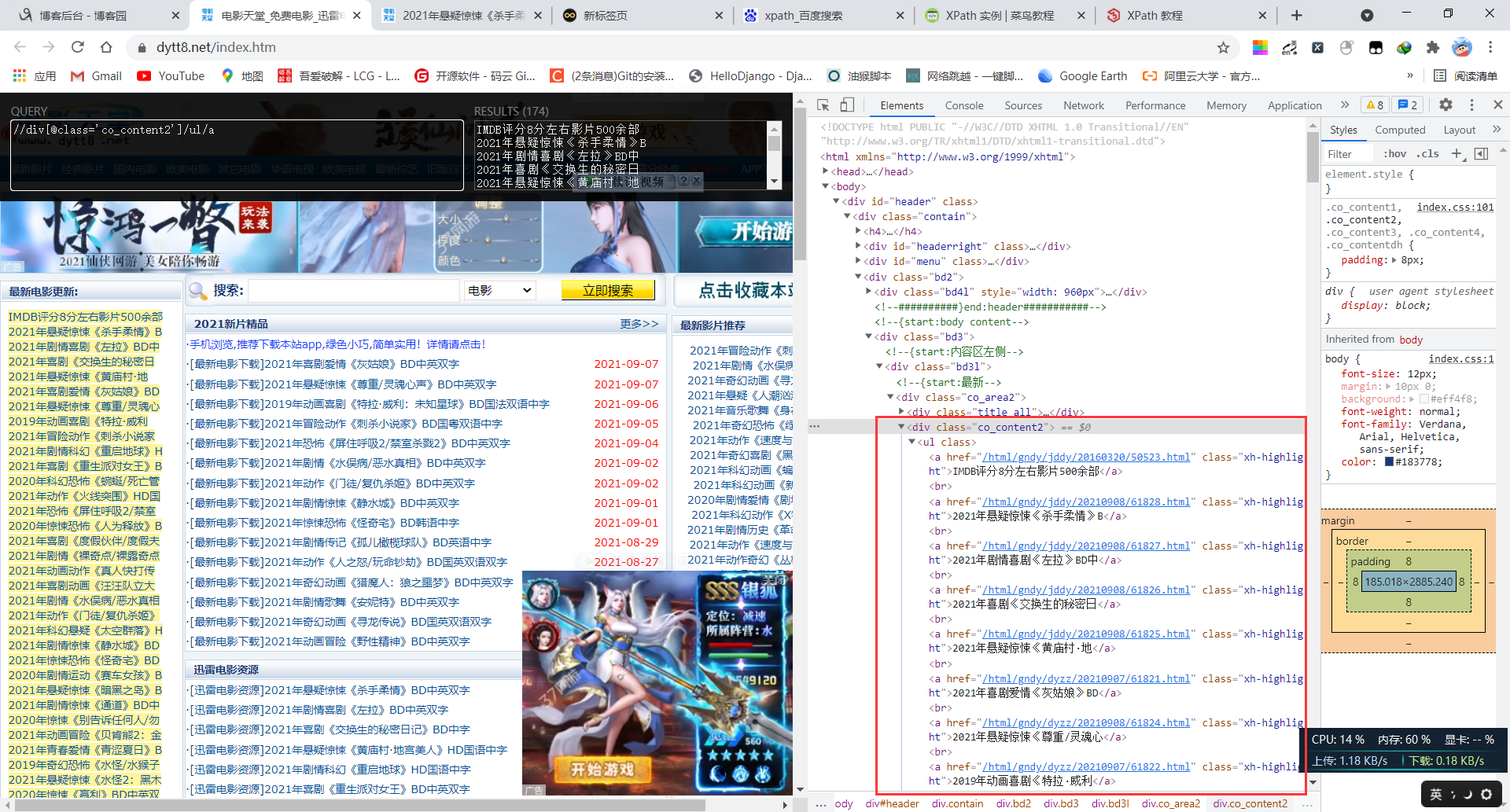
- 对其编写xpath表达式
5.1 提取描述文字xpath表达式
5.2 提取链接xpath表达式
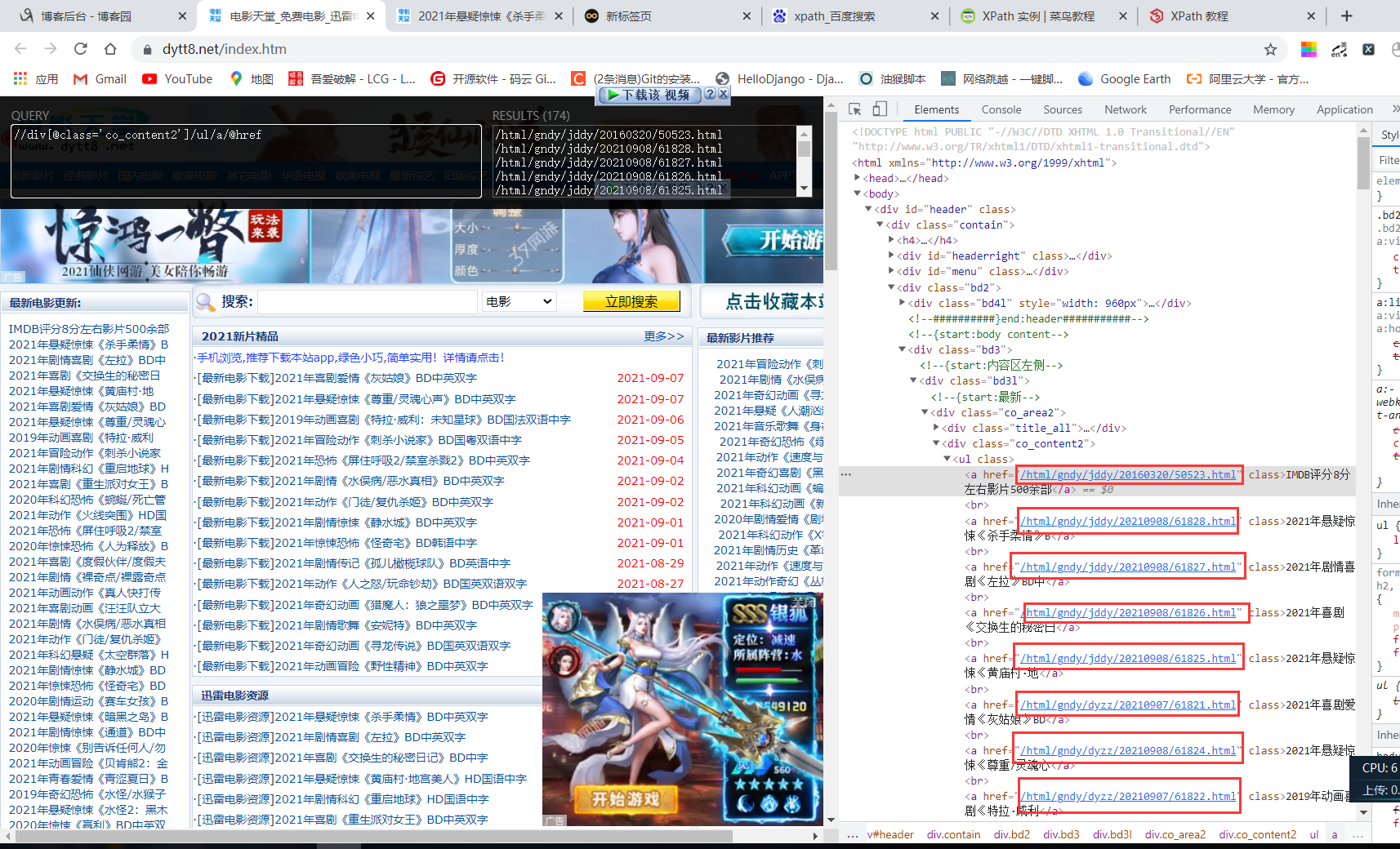
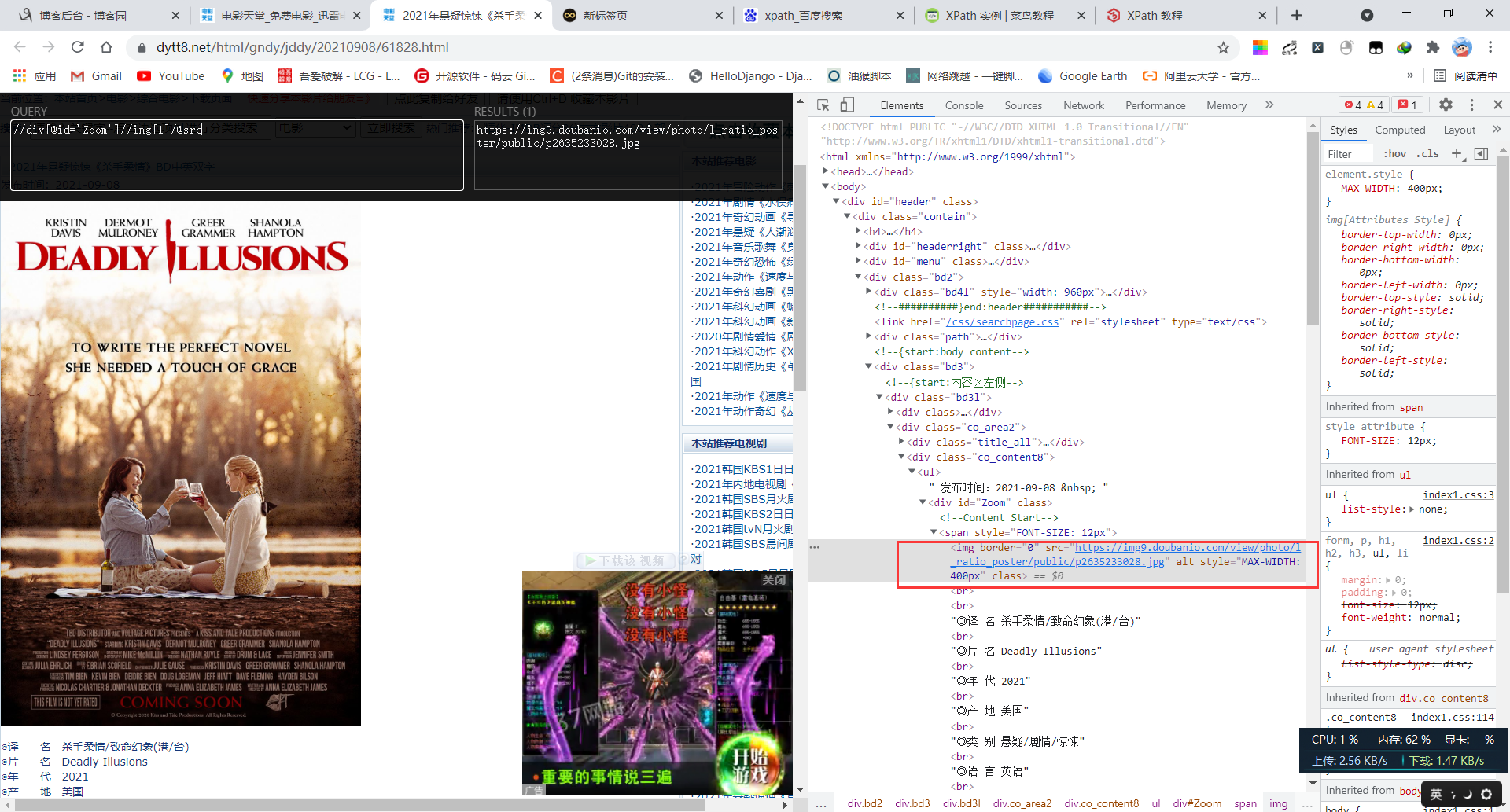
5.3 图片链接提取xpath表达式
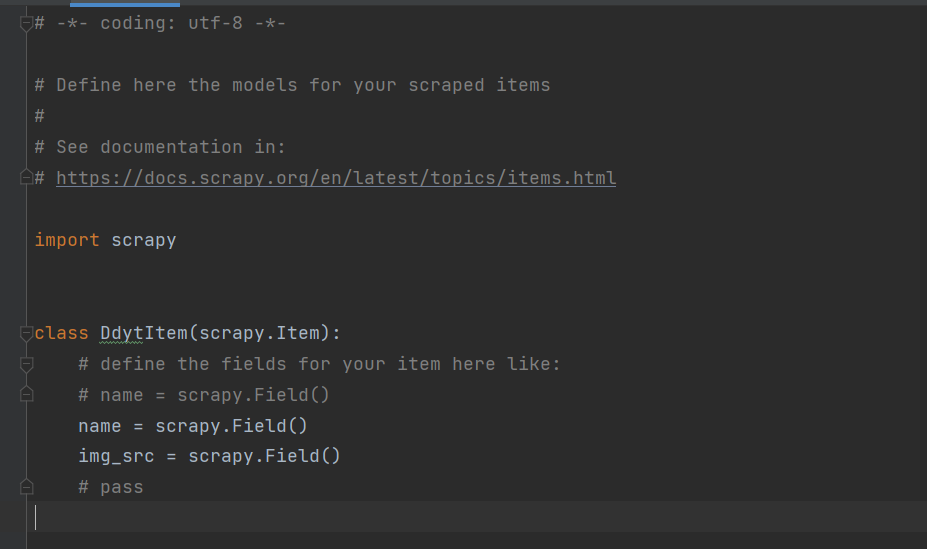
- 定义Item
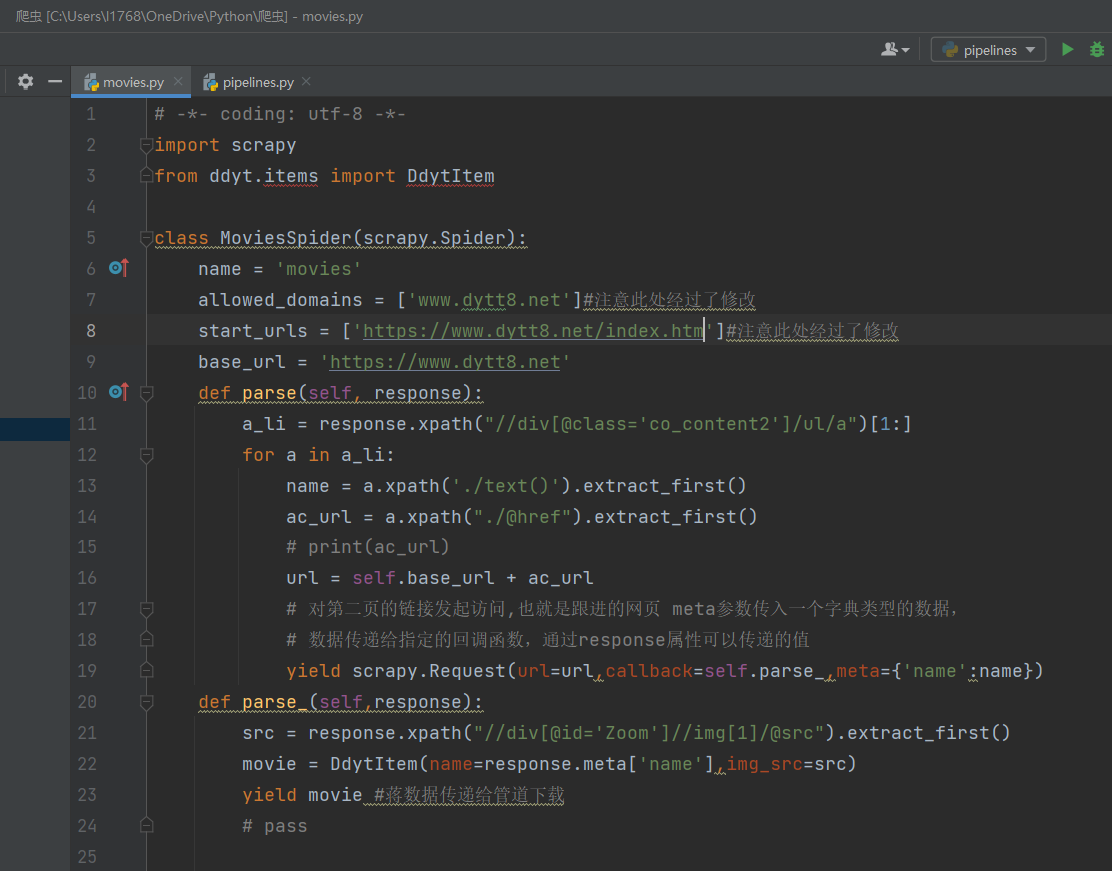
7.编写parse函数
8.编写管道函数
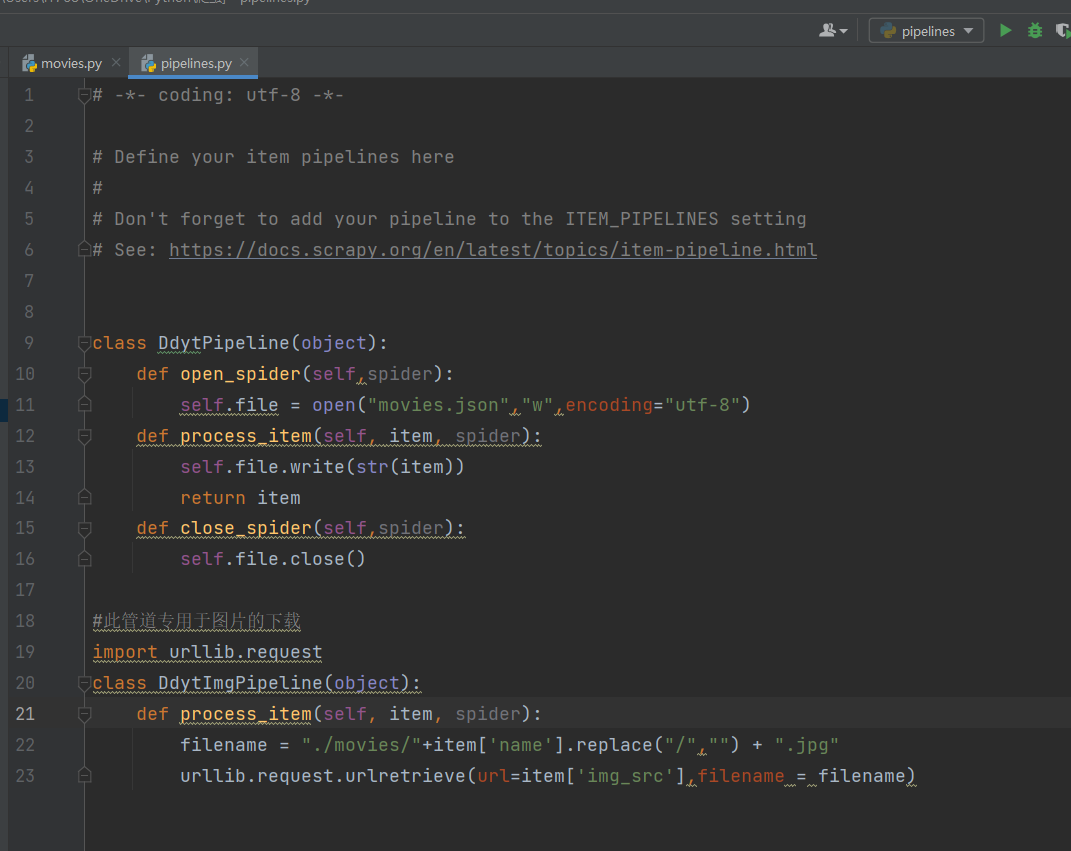
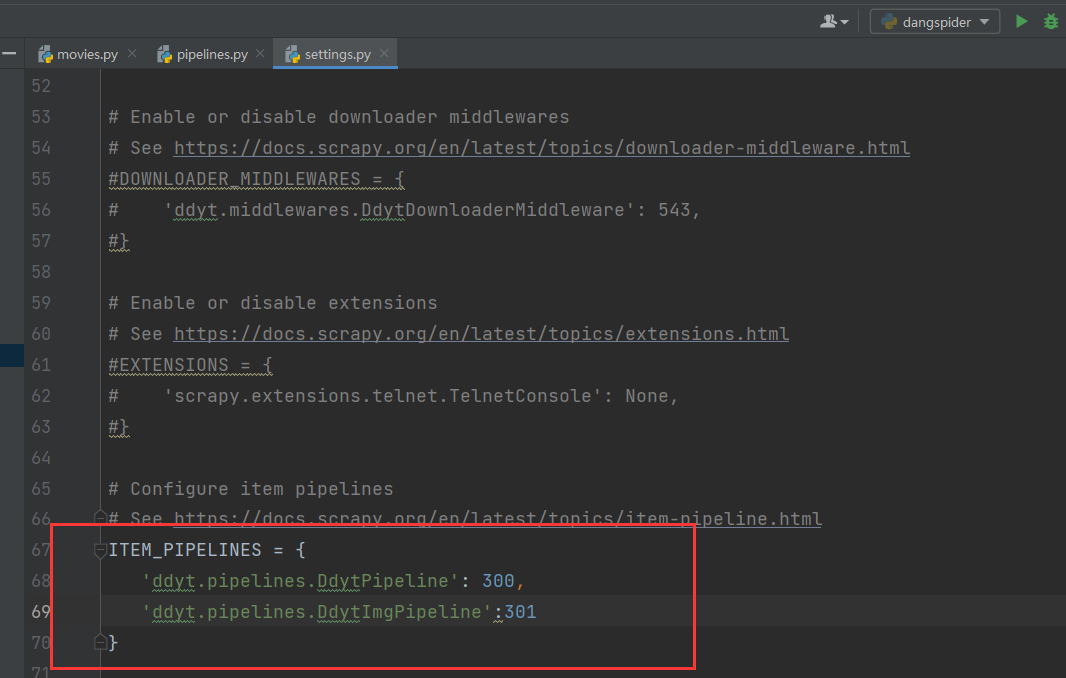
10.开启管道
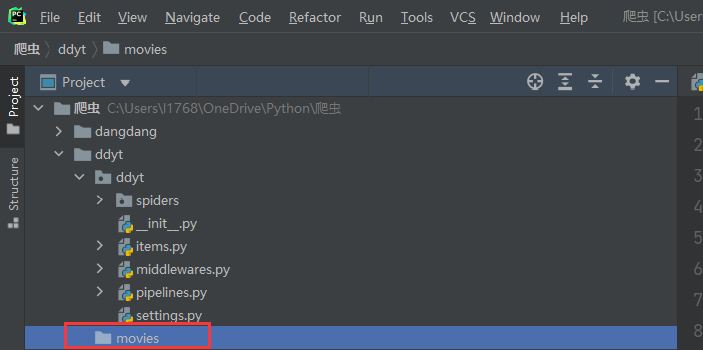
- 创建movies文件夹
- 启动爬虫

- 结果
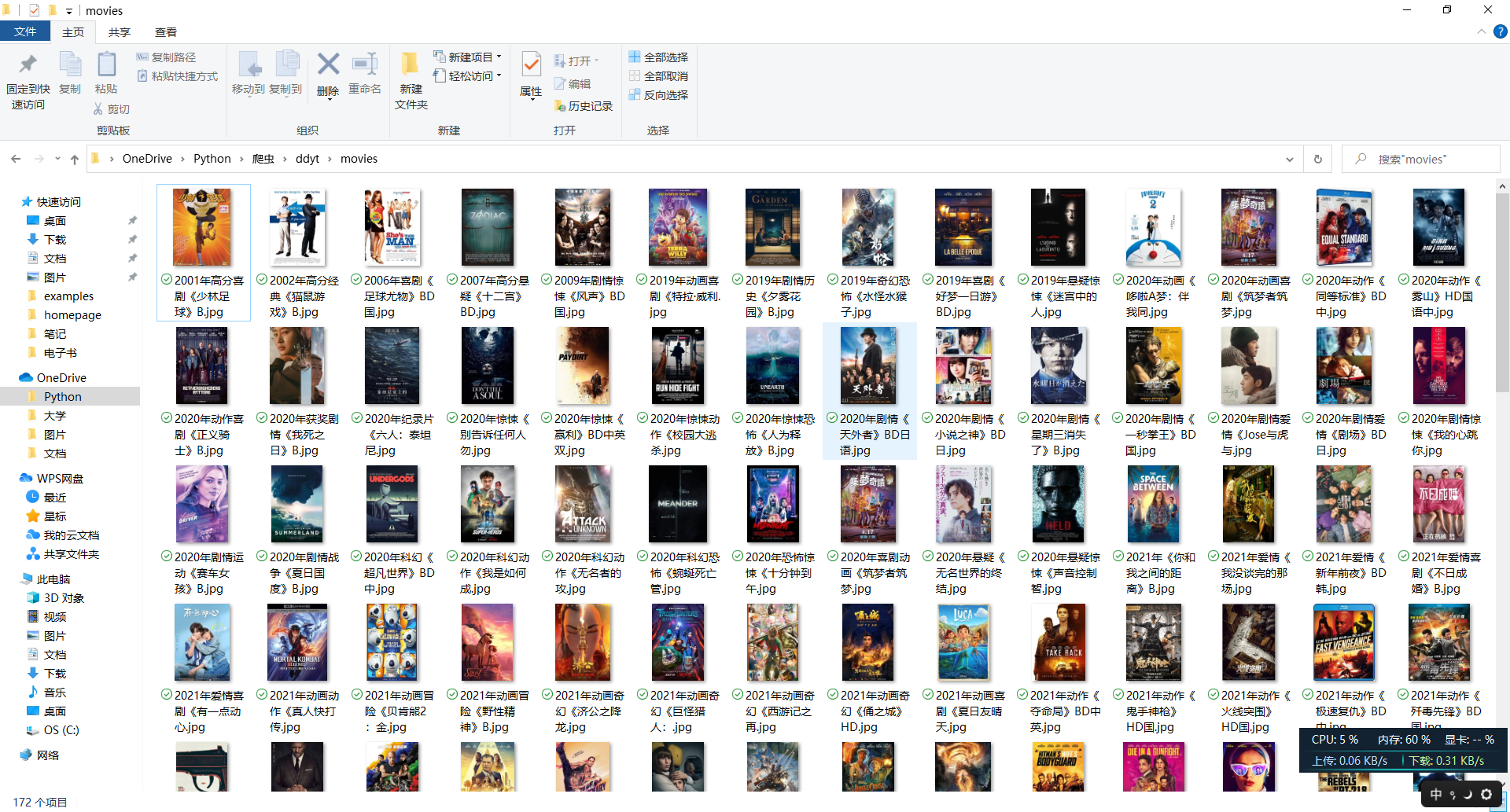
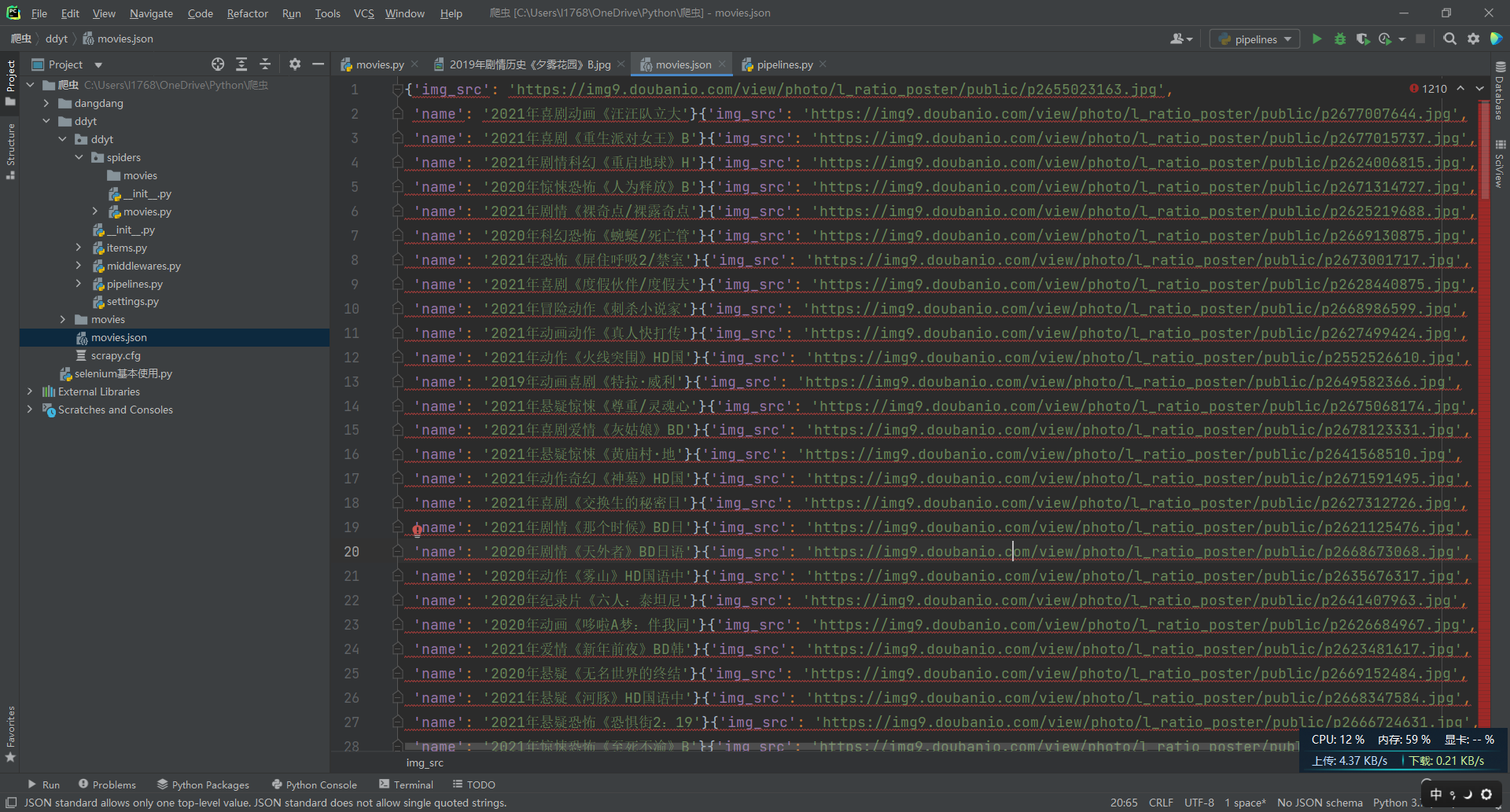
- emmm 除开第一个标签有173条数据,只爬取了172条数据,不知道原因出在哪儿。。。
“热爱是所有的理由和答案”。
