在 Kubernetes 上部署 OpenStack 是什么体验
红蓝出 CP,OpenStack 和 Kubernetes 在一起会怎样?
背景
从去年开始就想深入地学习 Kubernetes,首先想到是在 OpenStack 上能比较轻松地玩转,所以去 尝试了 Magnum ,但是结果令人失望。
不过随着我搜索到更多的内容,发现一个有趣的事情:
那就是相较于在 OpenStack 之上部署 Kubernetes,通过 Kubernetes 去部署 OpenStack 似乎更流行。
特别当我去研究最近比较热门的边缘计算,发现 OpenStack 社区的两个相关项目,一个是 StarlingX,一个是 Airship,它们都是这样做的:先搭建 Kubernetes 集群,然后通过 OpenStack-Helm 部署容器化的 OpenStack。
但是这两个项目都还挺复杂,直接去部署它们遇到了不少坑,做了很多的前置操作,涉及到很多脚本代码,结果到搭建 K8s 步骤上还是卡住了。
于是我决定暂时先不管它们,直接跳到 OpenStack-Helm,至少让我先体验一下基于 Kubernetes 的 OpenStack 到底是啥样。
这样就又回到了起点:我得先有一套 Kubernetes 多节点集群,但是现在只有一套 OpenStack 环境,所以我仍然得先解决在 OpenStack 上搭建 Kubernetes 的问题。
经过了一番摸索,踩了不少坑,最后终于完成了这次尝试。
下面简单地分享下最终的效果,其中的过程涉及较多,后续再择机分享。
整个环境概况
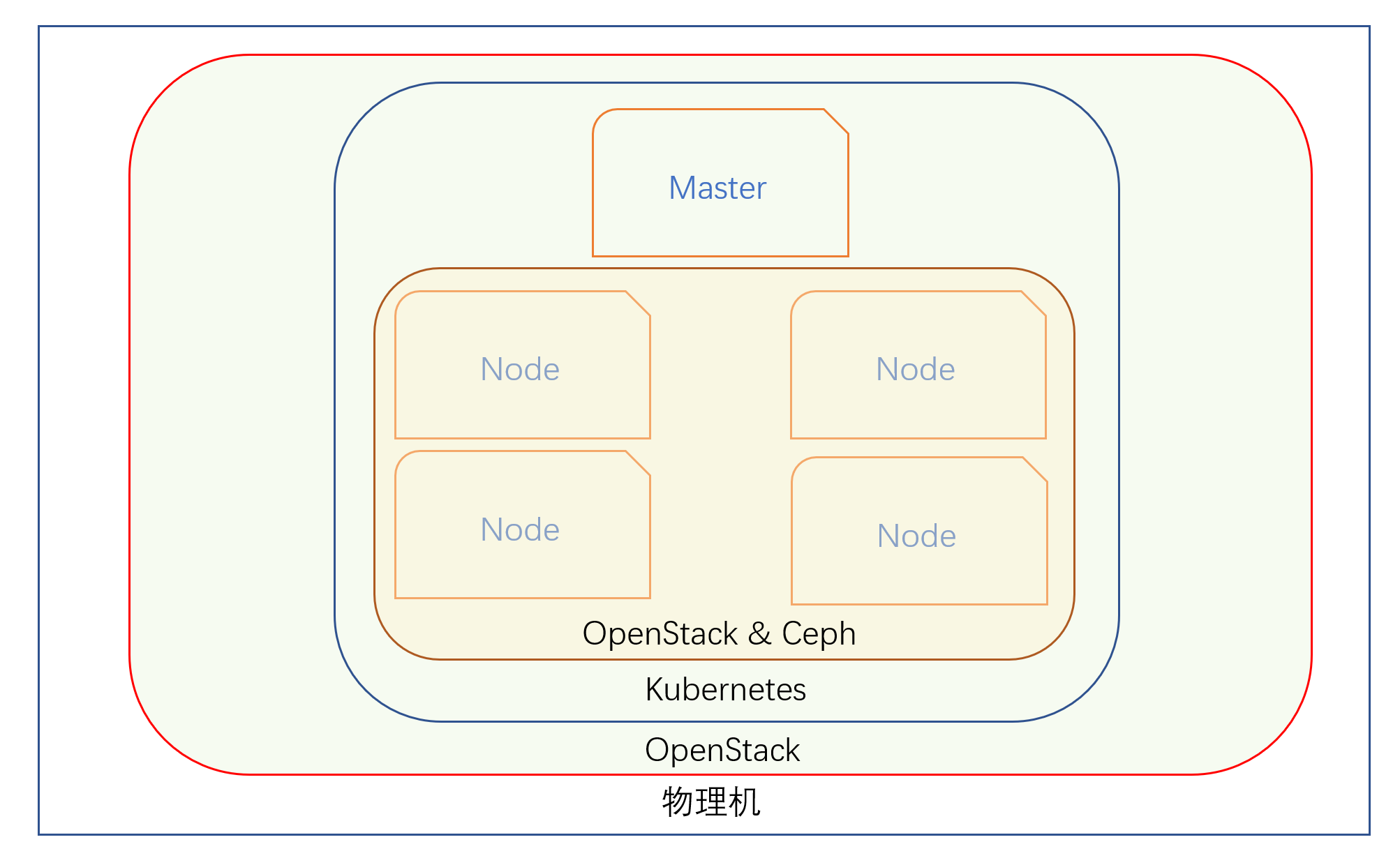
最上层:一个普通的 OpenStack 环境
在上面的 OpenStack 中用 cirros 镜像创建了一个虚机:
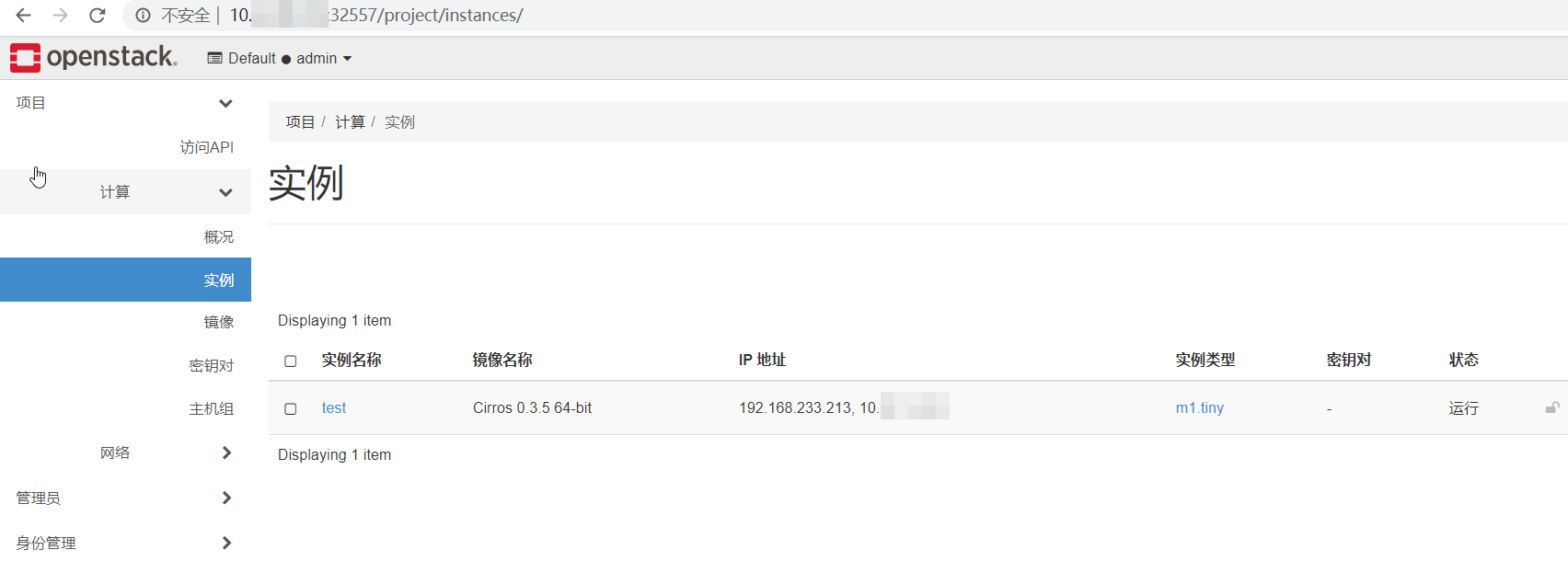
细心的你可能已经发现这里的端口号不是默认的 80,而是比较奇怪的 32557,这是因为这个 openstack 环境是搭建在 Kubernetes 集群上,而且通过 NodePort 暴露的服务。
在页面上查看 openstack 的系统信息:
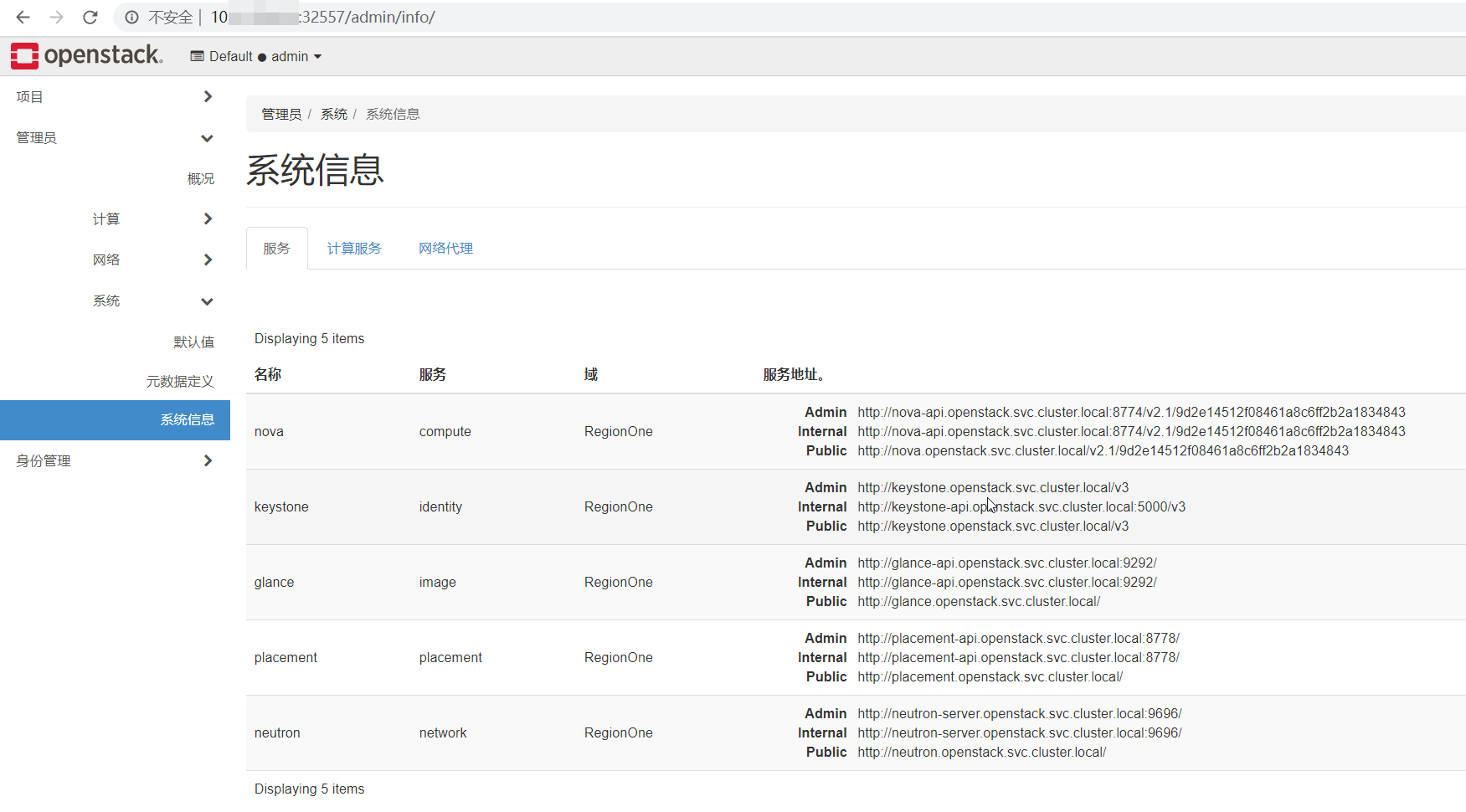
各个服务的 endpoints URL 都是以 *.openstack.svc.cluster.local 域名的形式,熟悉 Kubernetes 的应该看上去有点眼熟。
OpenStack 在 Kubernetes 中的细节
下面详细地看看 OpenStack 在集群中是怎么一回事:
Helm
全部使用 Helm 部署:

Ingress
Public 接口是通过 Ingress 暴露的:

Service
更多的内部接口则可以在 service 中看到:
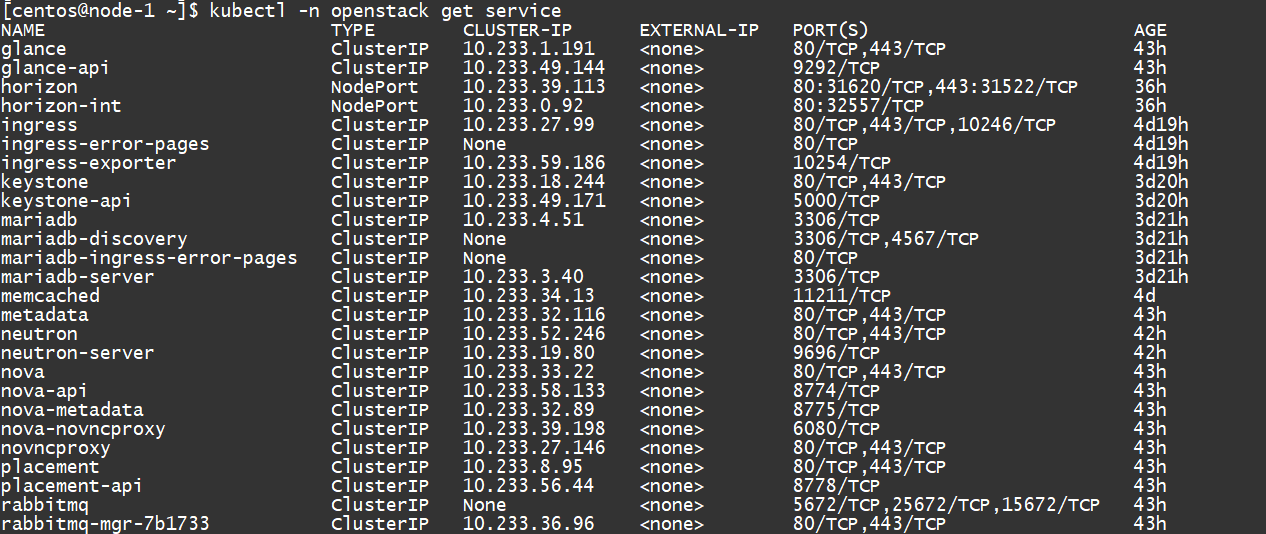
注意 horizon-int 对应的就是 Dashboard 服务,它的类型是 NodePort 而且映射的端口号是 32557
DaemonSet
各种 agent 包括计算节点、OVS、Libvirt 等,都是通过 DaemonSet :

StatefulSet
带状态的数据库和消息队列,以 StatefulSet 的形式:

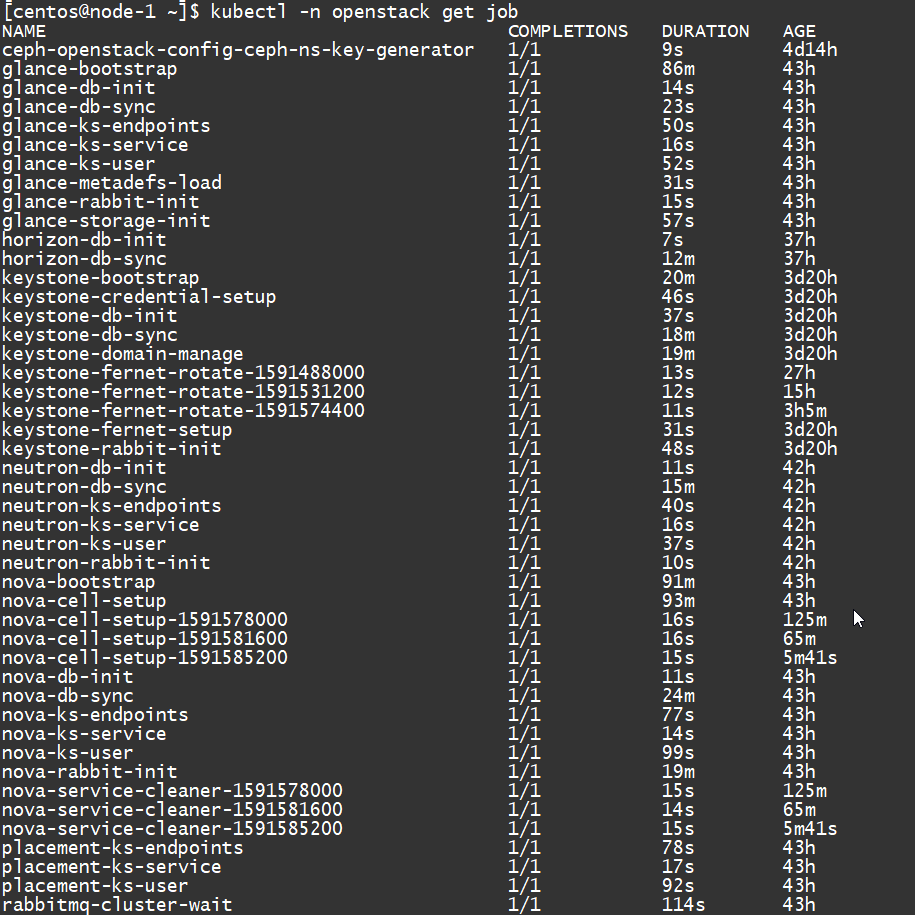
Job
还有部署过程中的各种任务,包括初始化数据库,注册 endpoint 等,都是以 job 方式执行的:
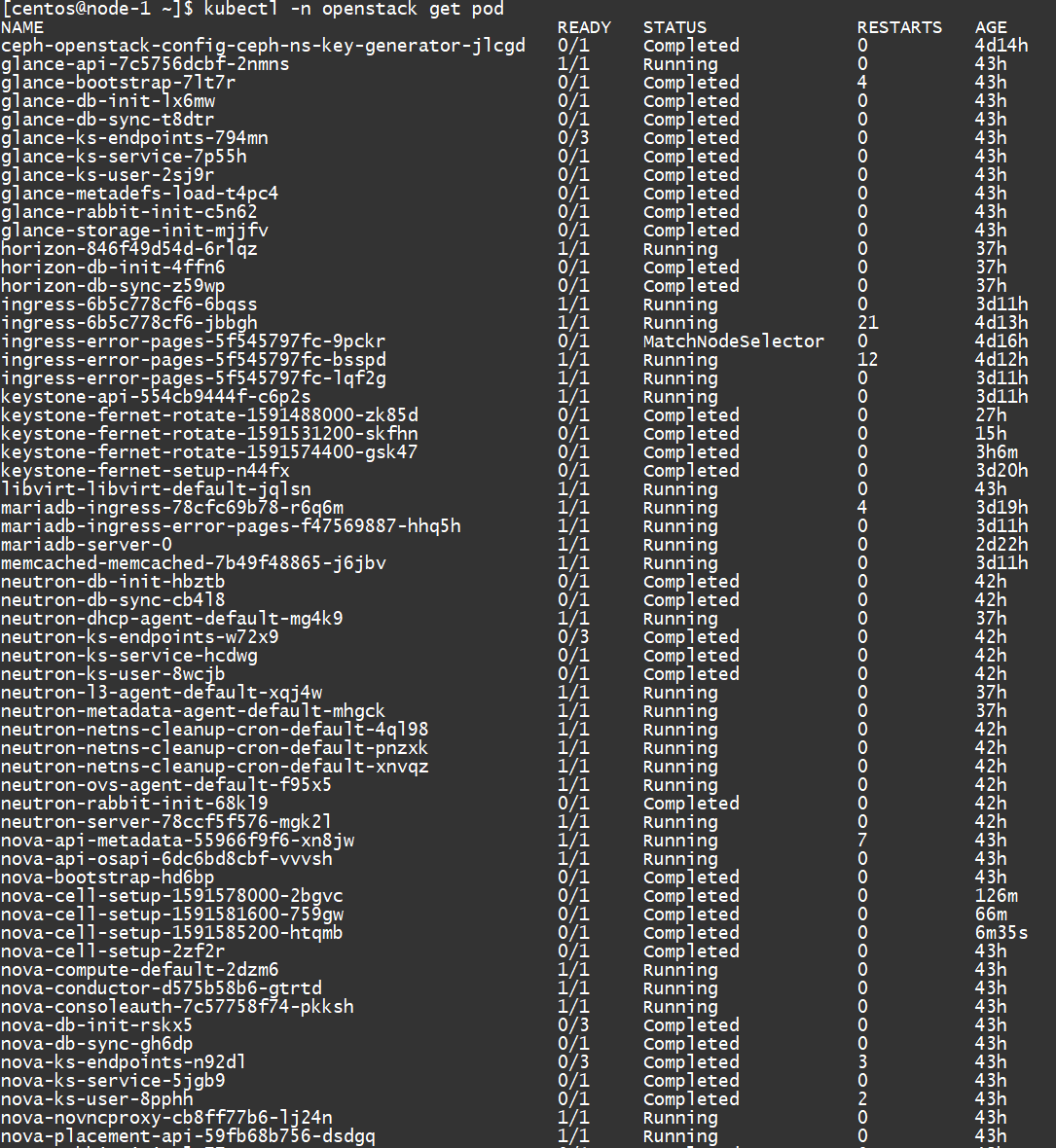
Pod
最终所有这些 pod 构成了这个 openstack 环境:
PV 和 PVC
当然还要用到持久化的卷存储,即 PersistentVolumeClaim 和 PersistentVolume :

Ceph
持久化存储由 ceph 提供,它们同样部署在当前集群中 :

中间层:Kubernetes on OpenStack
这个 Kubernetes 集群有 4 个节点,1 个 master 节点,3 个 worker 节点:

4 个节点都是底层 OpenStack 环境提供的虚机:
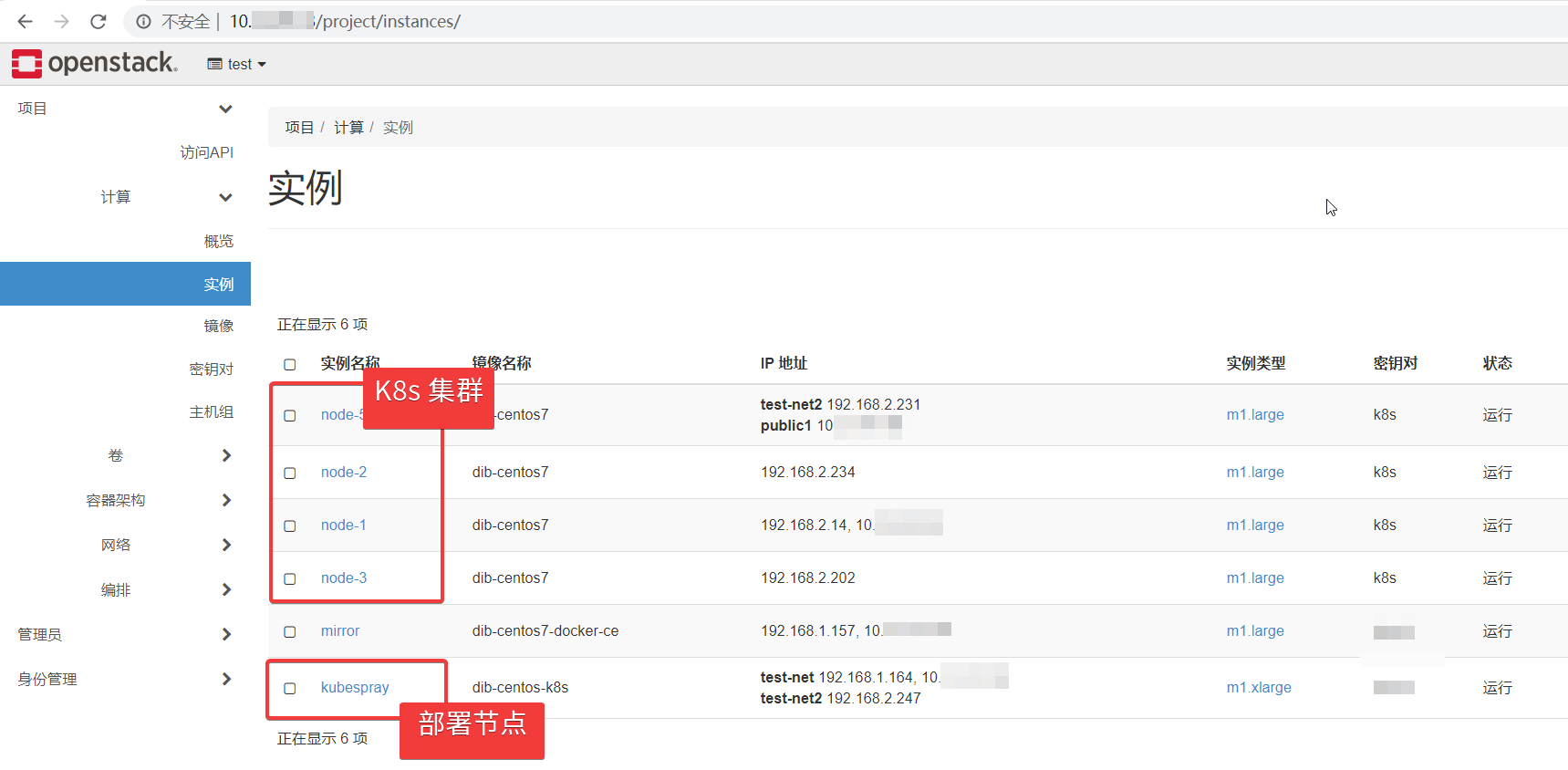
在 openstack 中部署 Kubernetes 的方案很多,在尝试了其中的一些(包括 magnum)之后,最终使用基于 Ansible 的 Kubespray 部署。为了简化操作,这套 Kubernetes 集群也并没有对接底层的 OpenStack。
手动创建了虚机之后,完成这样一套集群大概需要 20 分钟:
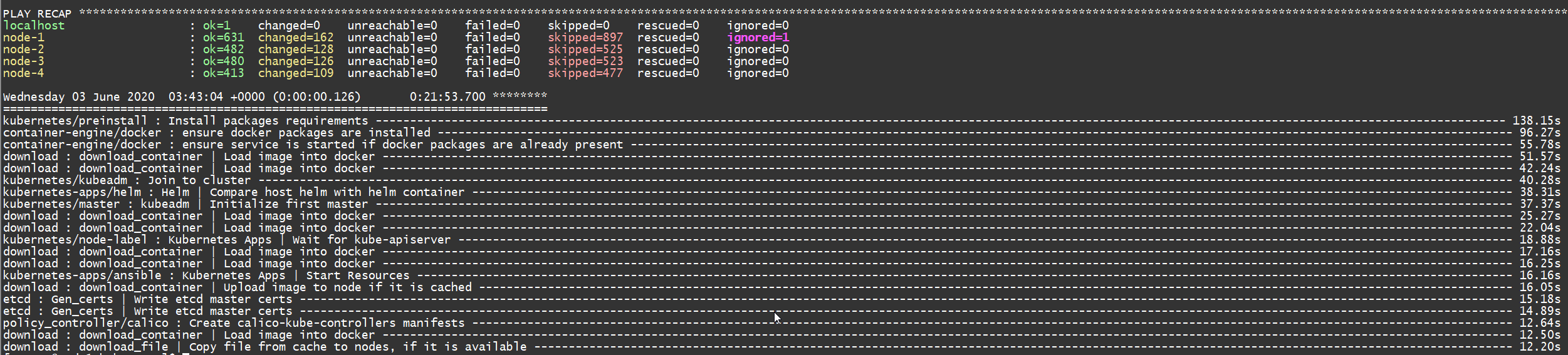
这里最初的 node-4 不幸被折腾挂了,所以上面显示的是后面新增的 node-5
最下层:基于 Kolla 的 OpenStack
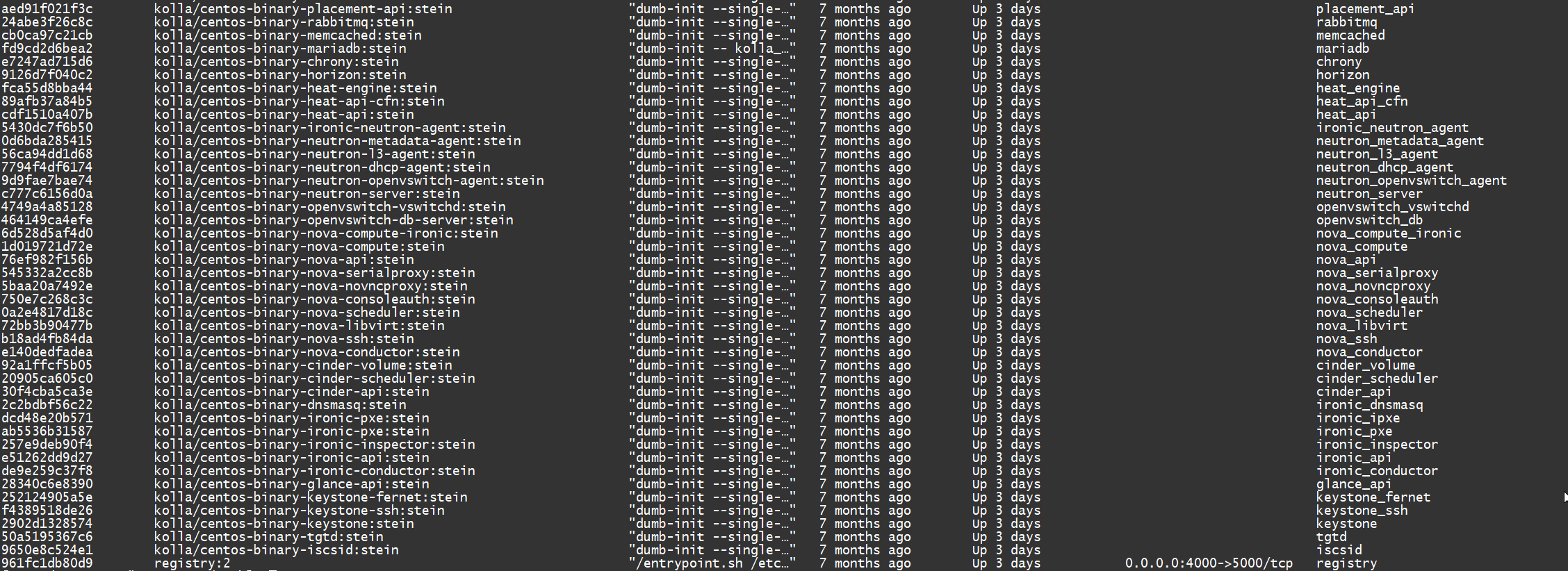
最底层的 openstack 是搭建在一台物理服务器上的 All-In-One 环境,使用 Kolla 作为部署工具。
Kolla 使用容器来部署 OpenStack,所以可以通过 docker ps 查看服务:
总结和思考
OpenStack 和 Kubernetes 的关系
一直以来 OpenStack 作为 IaaS 层,用来管理底层计算资源,而 Kubernetes 则被视作 PaaS 层,来管理应用和容器。在通常的架构图中,OpenStack 都是处在 Kubernetes 的下层,作为云计算平台提供诸如持久卷、负载均衡等资源。
事实上,OpenStack 系统本身就是一个微服务的架构,使用容器化部署,进而使用 Kubernetes 来管理已经是大势所趋。通过 Kubernetes 强大的容器编排能力,长久以来被诟病的 OpenStack 的部署难,升级难等问题可以得到有效解决。 在这次测试中,当中途遇到错误时,处理方式非常「简单粗暴」,直接删掉重来。管理面要求高可用?直接改 replicas 就行。Kubernetes 和 Helm 的强大功能令人印象深刻。
同时现在可以无缝引入云原生社区强大生态,例如 Prometheus,ELK 等,想用的话基本就是一键部署和接入。
由于 Kubernetes 基于云的设计,在私有云场景下,OpenStack 仍然是 Cloud Provider 的不二选择。不仅可以提供可用于部署集群的 Node 实例(虚机或裸金属),也能补充底层网络/存储资源的管理能力。
关于实际应用的思考
因为环境所限,这里最上层 OpenStack 已经是二次虚拟化了,显然没有实用价值,实际应用中需要有所变化。
我能想到的可行方案:
以虚拟机为主要工作负载的,容器作为补充的,可以考虑保留下面两层,通过 OpenStack 提供基于虚机的 Kubernetes 集群和容器服务。 以容器为主要工作负载的,可以考虑仅使用上面两层,在裸机上部署 Kubernetes。这样部署在上层的 OpenStack 就是一个用来供给虚机的服务,本质和部署一个网站没啥区别。 结合我们前面介绍的裸金属技术,保留所有三层,底层的 OpenStack 只负责提供裸金属实例,这样上面两层的作用和上一个方案类似。
当然,显而易见的,这样一套架构最大的问题就是太过于复杂。同时引入两套技术栈,对团队的要求较高。如果非要二选一,大多数的小公司会作何选择不言而喻。
你对 Kubernetes 和 OpenStack 之间关系有何想法,欢迎在评论区讨论。
感谢你的阅读,请继续关注「云计算实验室」
本文使用 mdnice 排版

 浙公网安备 33010602011771号
浙公网安备 33010602011771号