
orchestrator-Raft集群部署
本文简要说明下orchestrator的Raft集群部署,其实部署很简单主要是好好研究下配置文件的配置,这里我的样例配置文件暂时只适用于我们这块业务
如果您自己使用请根据情况自行修改。
主要通过配置文件,守护进程、代理配置(官方推荐通过代理把请求都打在Leader上)三部分说明
机器信息:
192.168.1.100
192.168.1.101
192.168.1.102
一共三台机器,三台机器分别部署
1. 配置文件
{ "Debug": true, "EnableSyslog": false, "ListenAddress": ":3000", "AgentsServerPort": ":3001", "MySQLTopologyUser": "orc_client_user", "MySQLTopologyPassword": "orc_client_user_password", "MySQLTopologyCredentialsConfigFile": "", "MySQLTopologySSLPrivateKeyFile": "", "MySQLTopologySSLCertFile": "", "MySQLTopologySSLCAFile": "", "MySQLTopologySSLSkipVerify": true, "MySQLTopologyUseMutualTLS": false, # 这里我使用的是sqlite数据库,如果使用mysql数据库请自己修改 "BackendDB": "sqlite3", "SQLite3DataFile": "/export/orc-sqlite3.db", "MySQLOrchestratorHost": "192.168.1.100", "MySQLOrchestratorPort": 3358, "MySQLOrchestratorDatabase": "orchestrator", "MySQLOrchestratorUser": "orchestrator_rw", "MySQLOrchestratorPassword": "orchestrator_pwd", "MySQLOrchestratorCredentialsConfigFile": "", "MySQLOrchestratorSSLPrivateKeyFile": "", "MySQLOrchestratorSSLCertFile": "", "MySQLOrchestratorSSLCAFile": "", "MySQLOrchestratorSSLSkipVerify": true, "MySQLOrchestratorUseMutualTLS": false, "MySQLConnectTimeoutSeconds": 5, "DefaultInstancePort": 3306, "SkipOrchestratorDatabaseUpdate": false, "SlaveLagQuery": "", "DiscoverByShowSlaveHosts": true, "InstancePollSeconds": 30, "UnseenInstanceForgetHours": 240, "SnapshotTopologiesIntervalHours": 0, "InstanceBulkOperationsWaitTimeoutSeconds": 10, "HostnameResolveMethod": "none", "MySQLHostnameResolveMethod": "none", "SkipBinlogServerUnresolveCheck": true, "ExpiryHostnameResolvesMinutes": 60, "RejectHostnameResolvePattern": "", "ReasonableReplicationLagSeconds": 10, "ProblemIgnoreHostnameFilters": [], "VerifyReplicationFilters": false, "ReasonableMaintenanceReplicationLagSeconds": 20, "CandidateInstanceExpireMinutes": 60, "AuditLogFile": "/tmp/orchestrator-audit.log", "AuditToSyslog": false, "RemoveTextFromHostnameDisplay": ".mydomain.com:3358", "ReadOnly": false, "AuthenticationMethod": "", "HTTPAuthUser": "", "HTTPAuthPassword": "", "AuthUserHeader": "", "PowerAuthUsers": [ "*" ], "ClusterNameToAlias": { "127.0.0.1": "test suite" }, "DetectClusterAliasQuery": "SELECT value FROM _vt.local_metadata WHERE name='ClusterAlias'", "DetectClusterDomainQuery": "", "DetectInstanceAliasQuery": "SELECT value FROM _vt.local_metadata WHERE name='Alias'", "DetectPromotionRuleQuery": "SELECT value FROM _vt.local_metadata WHERE name='PromotionRule'", "DataCenterPattern": "", "PhysicalEnvironmentPattern": "[.]([^.]+[.][^.]+)[.]mydomain[.]com", "DetectDataCenterQuery": "SELECT value FROM _vt.local_metadata where name='DataCenter'", "PromotionIgnoreHostnameFilters": [], "DetectSemiSyncEnforcedQuery": "SELECT @@global.rpl_semi_sync_master_wait_no_slave AND @@global.rpl_semi_sync_master_timeout > 1000000", "ServeAgentsHttp": false, "AgentsUseSSL": false, "AgentsUseMutualTLS": false, "AgentSSLSkipVerify": false, "AgentSSLPrivateKeyFile": "", "AgentSSLCertFile": "", "AgentSSLCAFile": "", "AgentSSLValidOUs": [], "UseSSL": false, "UseMutualTLS": false, "SSLSkipVerify": false, "SSLPrivateKeyFile": "", "SSLCertFile": "", "SSLCAFile": "", "SSLValidOUs": [], "StatusEndpoint": "/api/status", "StatusSimpleHealth": true, "StatusOUVerify": false, "AgentPollMinutes": 60, "UnseenAgentForgetHours": 6, "StaleSeedFailMinutes": 60, "SeedAcceptableBytesDiff": 8192, "PseudoGTIDPattern": "drop view if exists .*?`_pseudo_gtid_hint__", "PseudoGTIDMonotonicHint": "asc:", "DetectPseudoGTIDQuery": "", "BinlogEventsChunkSize": 10000, "SkipBinlogEventsContaining": [], "ReduceReplicationAnalysisCount": true, "FailureDetectionPeriodBlockMinutes": 60, "RecoveryPeriodBlockMinutes": 60, "RecoveryPeriodBlockSeconds": 3600, "RecoveryIgnoreHostnameFilters": [ ".*" ], "RecoverMasterClusterFilters": [ ".*" ], "RecoverIntermediateMasterClusterFilters": [ "_intermediate_master_pattern_" ], "OnFailureDetectionProcesses": [ "echo 'Detected {failureType} on {failureCluster}. Affected replicas: {countSlaves}' >> /tmp/recovery.log" ], "PreFailoverProcesses": [ "echo 'Will recover from {failureType} on {failureCluster}' >> /tmp/recovery.log" ], "PostFailoverProcesses": [ "echo '(for all types) Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log" ], "PostUnsuccessfulFailoverProcesses": [ "echo 'Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Promoted: {successorHost}:{successorPort}' >> /tmp/recovery.log", "curl -d '{\"isSuccessful\": {isSuccessful}, \"failureType\": \"{failureType}\", \"failureDescription\": \"{failureDescription}\", \"failedHost\": \"{failedHost}\", \"failedPort\": {failedPort}, \"failureCluster\": \"{failureCluster}\", \"failureClusterAlias\": \"{failureClusterAlias}\", \"failureClusterDomain\": \"{failureClusterDomain}\", \"countSlaves\": {countSlaves}, \"countReplicas\": {countReplicas}, \"isDowntimed\": {isDowntimed}, \"autoMasterRecovery\": {autoMasterRecovery}, \"autoIntermediateMasterRecovery\": {autoIntermediateMasterRecovery}, \"orchestratorHost\": \"{orchestratorHost}\", \"recoveryUID\": \"{recoveryUID}\", \"lostSlaves\": \"{lostSlaves}\", \"lostReplicas\": \"{lostReplicas}\", \"slaveHosts\": \"{slaveHosts}\", \"replicaHosts\": \"{replicaHosts}\"}' http://test.domain.com/api/failover" ], "PostMasterFailoverProcesses": [ "echo 'Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Promoted: {successorHost}:{successorPort}' >> /tmp/recovery.log", "curl -d '{\"isSuccessful\": {isSuccessful}, \"failureType\": \"{failureType}\", \"failureDescription\": \"{failureDescription}\", \"failedHost\": \"{failedHost}\", \"failedPort\": {failedPort}, \"failureCluster\": \"{failureCluster}\", \"failureClusterAlias\": \"{failureClusterAlias}\", \"failureClusterDomain\": \"{failureClusterDomain}\", \"countSlaves\": {countSlaves}, \"countReplicas\": {countReplicas}, \"isDowntimed\": {isDowntimed}, \"autoMasterRecovery\": {autoMasterRecovery}, \"autoIntermediateMasterRecovery\": {autoIntermediateMasterRecovery}, \"orchestratorHost\": \"{orchestratorHost}\", \"recoveryUID\": \"{recoveryUID}\", \"successorHost\": \"{successorHost}\", \"successorPort\": {successorPort}, \"lostSlaves\": \"{lostSlaves}\", \"lostReplicas\": \"{lostReplicas}\", \"slaveHosts\": \"{slaveHosts}\", \"successorAlias\": \"{successorAlias}\",\"replicaHosts\": \"{replicaHosts}\"}' http://test.domain.com/api/failover" ], "PostIntermediateMasterFailoverProcesses": [ "echo 'Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log" ], "CoMasterRecoveryMustPromoteOtherCoMaster": true, "DetachLostSlavesAfterMasterFailover": true, "ApplyMySQLPromotionAfterMasterFailover": true, "MasterFailoverLostInstancesDowntimeMinutes": 0, "PostponeSlaveRecoveryOnLagMinutes": 0, "OSCIgnoreHostnameFilters": [], "GraphiteAddr": "", "GraphitePath": "", "GraphiteConvertHostnameDotsToUnderscores": true, "RaftEnabled": true, "RaftDataDir": "/export/Data/orchestrator", "RaftBind": "192.168.1.100", "RaftAdvertise": "192.168.1.100", "DefaultRaftPort": 10008, "RaftNodes": [ "192.168.1.100", "192.168.1.101", "192.168.1.102", ] }
以上只列出了192.168.1.100的配置,另外两台机器的配置类似的修改就可以,主要注意需要修改RaftBind, RaftAdvertise对应的值即可,其他参数根据个人需要自己修改。
配置准备好后将程序打包防止在/export/App/orchestrator目录下
2. sqlite数据库文件配置
由于配置里面我们使用了sqlite数据库,所以需要将sqlite数据库文件放置在对应的目录下
3. 守护进程
参数配置文件准备好了,我们下面准备守护进程脚本,方便程序故障时重新启动
配置脚本信息如下:
#!/bin/bash # orchestrator daemon # chkconfig: 345 20 80 # description: orchestrator daemon # processname: orchestrator # Script credit: http://werxltd.com/wp/2012/01/05/simple-init-d-script-template/ # 执行路径,这个和我们防止可执行文件的路劲一致 DAEMON_PATH="/export/App/orchestrator" DAEMON=orchestrator DAEMONOPTS="-config /export/App/orchestrator/orchestrator.conf.json --verbose http" NAME=orchestrator DESC="orchestrator: MySQL replication management and visualization" PIDFILE=/var/run/$NAME.pid SCRIPTNAME=/etc/init.d/$NAME # Limit the number of file descriptors (and sockets) used by # orchestrator. This setting should be fine in most cases but a # large busy environment may # reach this limit. If exceeded expect # to see errors of the form: # 2017-06-12 02:33:09 ERROR dial tcp 10.1.2.3:3306: connect: cannot assign requested address # To avoid touching this script you can use /etc/orchestrator_profile # to increase this limit. ulimit -n 16384 # initially noop but can adjust according by modifying orchestrator_profile # - see https://github.com/github/orchestrator/issues/227 for more details. post_start_daemon_hook () { # by default do nothing : } # Start the orchestrator daemon in the background
# 这里需要注意的是我们启动后会把日志文件直接重定向到/export/Logs/orchestrator目录下面,查看日志直接在该目录查看即可 start_daemon () { # start up daemon in the background $DAEMON_PATH/$DAEMON $DAEMONOPTS >> /export/Logs/orchestrator/${NAME}.log 2>&1 & # collect and print PID of started process echo $! # space for optional processing after starting orchestrator # - redirect stdout to stderro to prevent this corrupting the pid info post_start_daemon_hook 1>&2 } # The file /etc/orchestrator_profile can be used to inject pre-service execution # scripts, such as exporting variables or whatever. It's yours! #[ -f /etc/orchestrator/orchestrator_profile ] && . /etc/orchestrator/orchestrator_profile case "$1" in start) printf "%-50s" "Starting $NAME..." cd $DAEMON_PATH PID=$(start_daemon) #echo "Saving PID" $PID " to " $PIDFILE if [ -z $PID ]; then printf "%s\n" "Fail" exit 1 elif [ -z "$(ps axf | awk '{print $1}' | grep ${PID})" ]; then printf "%s\n" "Fail" exit 1 else echo $PID > $PIDFILE printf "%s\n" "Ok" fi ;; status) printf "%-50s" "Checking $NAME..." if [ -f $PIDFILE ]; then PID=$(cat $PIDFILE) if [ -z "$(ps axf | awk '{print $1}' | grep ${PID})" ]; then printf "%s\n" "Process dead but pidfile exists" exit 1 else echo "Running" fi else printf "%s\n" "Service not running" exit 1 fi ;; stop) printf "%-50s" "Stopping $NAME" PID=$(cat $PIDFILE) cd $DAEMON_PATH if [ -f $PIDFILE ]; then kill -TERM $PID rm -f $PIDFILE # Wait for orchestrator to stop otherwise restart may fail. # (The newly restarted process may be unable to bind to the # currently bound socket.) while ps -p $PID >/dev/null 2>&1; do printf "." sleep 1 done printf "\n" printf "Ok\n" else printf "%s\n" "pidfile not found" exit 1 fi ;; restart) $0 stop $0 start ;; reload) PID=$(cat $PIDFILE) cd $DAEMON_PATH if [ -f $PIDFILE ]; then kill -HUP $PID printf "%s\n" "Ok" else printf "%s\n" "pidfile not found" exit 1 fi ;; *) echo "Usage: $0 {status|start|stop|restart|reload}" exit 1 esac
如果应用程序防止目录不一致,只需要对应的修改路径即可,其他信息不用修改
所有程序防止完成之后即可启动,看看是否能正常选举
4. haproxy代理
安装haproxy
yum install haproxy
配置文件
#--------------------------------------------------------------------- # Example configuration for a possible web application. See the # full configuration options online. # # http://haproxy.1wt.eu/download/1.4/doc/configuration.txt # #--------------------------------------------------------------------- #--------------------------------------------------------------------- # Global settings #--------------------------------------------------------------------- global # to have these messages end up in /var/log/haproxy.log you will # need to: # # 1) configure syslog to accept network log events. This is done # by adding the '-r' option to the SYSLOGD_OPTIONS in # /etc/sysconfig/syslog # # 2) configure local2 events to go to the /var/log/haproxy.log # file. A line like the following can be added to # /etc/sysconfig/syslog # # local2.* /var/log/haproxy.log # log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon # turn on stats unix socket stats socket /var/lib/haproxy/stats #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 #--------------------------------------------------------------------- # main frontend which proxys to the backends #--------------------------------------------------------------------- #frontend main *:5000 # acl url_static path_beg -i /static /images /javascript /stylesheets # acl url_static path_end -i .jpg .gif .png .css .js # # use_backend static if url_static # default_backend app #--------------------------------------------------------------------- # static backend for serving up images, stylesheets and such #--------------------------------------------------------------------- #backend static # balance roundrobin # server static 127.0.0.1:4331 check #--------------------------------------------------------------------- # round robin balancing between the various backends #--------------------------------------------------------------------- #backend app # balance roundrobin # server app1 127.0.0.1:5001 check # server app2 127.0.0.1:5002 check # server app3 127.0.0.1:5003 check # server app4 127.0.0.1:5004 check listen orchestrator stats enable bind *:9888 mode http stats refresh 30s stats uri /admin bind 0.0.0.0:80 process 1 bind 0.0.0.0:80 process 2 bind 0.0.0.0:80 process 3 bind 0.0.0.0:80 process 4 option httpchk GET /api/leader-check maxconn 20000 balance first retries 1 timeout connect 1000 timeout check 300 timeout server 30s timeout client 30s default-server port 3000 fall 1 inter 1000 rise 1 downinter 1000 on-marked-down shutdown-sessions weight 10 server 192.168.1.100 192.168.1.100:3000 check server 192.168.1.101 192.168.1.101:3000 check server 192.168.1.102 192.168.1.102:3000 check
重启haproxy服务
service haproxy status
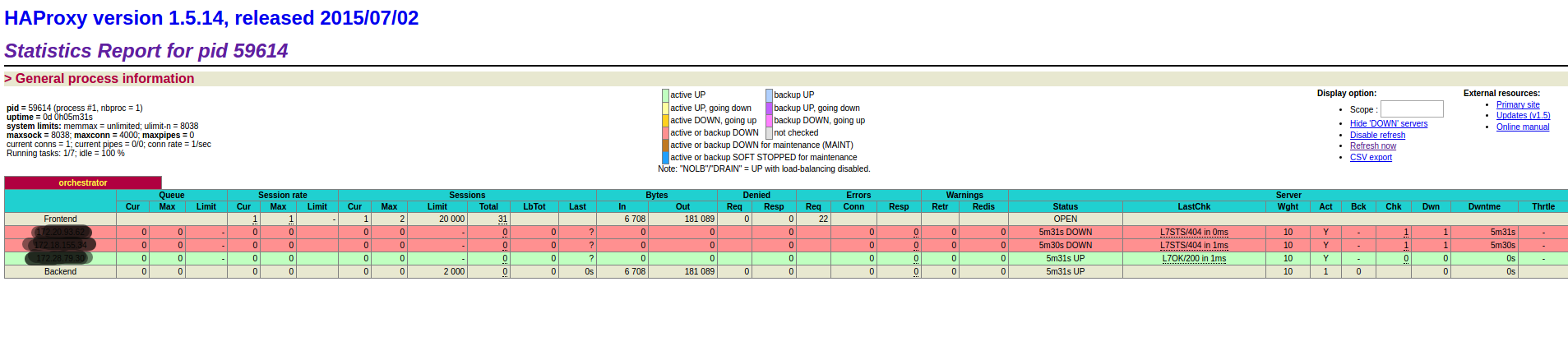
启动后查看监控页面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号