helm v3 调试 k8s elasticsearch集群(5)
上次我们已经通过helm部署了es的release,es集群是起来了,功能也正常,这次我们模拟测试,简单验证es的功能与性能。
测试主要分:
- 节点宕机
- 存储不足
- 待完善
本次测试,将master设replicas为3,data设置为3,client设置为2,因为只需调试时用kibana,设置1即可(可不用设置)。
调整es-client节点
# 停掉原有client的release
helm uninstall es-c -nelk
# 编辑副本为2
vim es-client.yaml
---
replicas: 1 -> replicas: 2
---
# 重新install release
helm install es-client -f es-client.yaml elastic/elasticsearch -nelk --version 6.8.18 --debug > client.log
删除原来的的pvc,pv
# 删除data/master节点的pvc
kubectl delete persistentvolumeclaim/helm-data-helm-data-0 -nelk
kubectl delete persistentvolumeclaim/helm-master-helm-master-0 -nelk
# 删除data/master节点的pv
kubectl delete pv/tets-pv -nelk
kubectl delete pv/tets-pv-d -nelk
新建pv,pvc,由于测试的master数量为3,data数量为3,所以应该设置6份pv, storageclass不变。
local-pv-d-0.yaml
local-pv-d-1.yaml
local-pv-d-2.yaml
local-pv-m-0.yaml
local-pv-m-1.yaml
local-pv-m-2.yaml
由于master节点主要用于负责集群间的管理工作,存储可以设置小些,data 节点,负责存储数据, 设置大些;client节点,负责代理 ElasticSearch Cluster 集群,负载均衡,不用设置存储卷。
master节点
# local-pv-m-0.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: test-pv-m-0
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local: # local类型
path: /mnt/m # 节点上的具体路径
nodeAffinity: # 这里就设置了节点亲和
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1 # 这里我们使用node01节点,该节点有/data/vol1路径
---
# local-pv-m-1.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: test-pv-m-1
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local: # local类型
path: /mnt/m # 节点上的具体路径
nodeAffinity: # 这里就设置了节点亲和
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node2 # 这里我们使用node01节点,该节点有/data/vol1路径
---
# local-pvc-m-2.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: test-pv-m-2
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local: # local类型
path: /mnt/m # 节点上的具体路径
nodeAffinity: # 这里就设置了节点亲和
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node3 # 这里我们使用node01节点,该节点有/data/vol1路径
---
# local-pvc-d-0.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: test-pv-d-0
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local: # local类型
path: /mnt/data # 节点上的具体路径
nodeAffinity: # 这里就设置了节点亲和
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1 # 这里我们使用node01节点,该节点有/data/vol1路径
---
# local-pvc-d-1.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: test-pv-d-1
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local: # local类型
path: /mnt/data # 节点上的具体路径
nodeAffinity: # 这里就设置了节点亲和
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node2 # 这里我们使用node01节点,该节点有/data/vol1路径
---
# local-pvc-d-2.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: test-pv-d-2
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local: # local类型
path: /mnt/data # 节点上的具体路径
nodeAffinity: # 这里就设置了节点亲和
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node3 # 这里我们使用node01节点,该节点有/data/vol1路径
创建6个pv,建议按照下列顺序创建,否则创建一堆pv,pv处于游离状态,在install release的时候,bound的pv可能乱序,即master和data乱序
# 先创建master的pv, 然后install release
kubectl apply -f local-pv-m-0.yaml -nelk
kubectl apply -f local-pv-m-1.yaml -nelk
kubectl apply -f local-pv-m-2.yaml -nelk
# master install release后,再创建data的pv,然后install data的release
kubectl apply -f local-pv-d-0.yaml -nelk
kubectl apply -f local-pv-d-1.yaml -nelk
kubectl apply -f local-pv-d-2.yaml -nelk
查看pv创建状态:
kubectl get pv,pvc -nelk

可以看到pv全部处于bound状态。
下面更改es-master.yaml/es-data.yaml,修改对应的存储及replicas 1->3:
# es-master.yaml
---
# 集群名称
clusterName: "helm"
# 节点所属群组
nodeGroup: "master"
# Master 节点的服务地址,这里是Master,不需要
masterService: ""
# 节点类型:
roles:
master: "true"
ingest: "false"
data: "false"
# 节点数量,做为 Master 节点,数量必须是 node >=3 and node mod 2 == 1
replicas: 3 # master eligible nodes,master的候选节点为3
minimumMasterNodes: 2 # 为防止脑裂,建议设置: 候选主节点数/2+1,即 3/2 + 1 = 2
esMajorVersion: ""
esConfig:
# elasticsearch.yml 的配置,主要是数据传输和监控的开关及证书配置
elasticsearch.yml: |
xpack:
security:
enabled: true
transport:
ssl:
enabled: true
verification_mode: certificate
keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
monitoring:
collection:
enabled: true
# 设置 ES 集群的 elastic 账号密码为变量
extraEnvs:
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: elastic-credentials
key: username
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: elastic-credentials
key: password
envFrom: []
# 挂载证书位置
secretMounts:
- name: elastic-certificates
secretName: elastic-certificates
path: /usr/share/elasticsearch/config/certs
# 镜像拉取来源,我对镜像做了一些简单的修改,故放置于自建的 harbor 里。
image: "docker.elastic.co/elasticsearch/elasticsearch"
imageTag: "6.8.18"
imagePullPolicy: "IfNotPresent"
imagePullSecrets:
- name: registry-secret
podAnnotations: {}
labels: {}
# ES 的 JVM 内存
esJavaOpts: "-Xmx512m -Xms512m" # 机器内存小时,不要设置太大,另外master节点功能主要是协调器,如索引的创建、集群管理等
# ES 运行所需的资源
resources:
requests:
cpu: "500m"
memory: "1Gi"
limits:
cpu: "500m"
memory: "1Gi"
initResources: {}
sidecarResources: {}
# ES 的服务 IP,如果没有设置这个,服务有可能无法启动。
networkHost: "0.0.0.0"
# ES 的存储配置
volumeClaimTemplate:
storageClassName: "local-storage" # 本地存储
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Gi
# PVC 开关
persistence:
enabled: true
labels:
enabled: false
annotations: {}
# rbac 暂未详细研究
rbac:
create: false
serviceAccountAnnotations: {}
serviceAccountName: ""
# 镜像部署选择节点
# nodeSelector:
# kubernetes.io/hostname: node1
# 容忍污点,如果 K8S 集群节点较少,需要在 Master 节点部署,需要使用此项
tolerations:
- operator: "Exists"
-------------es-data
# es-data.yaml
---
# 集群名称,必须和 Master 节点的集群名称保持一致
clusterName: "helm"
# 节点类型
nodeGroup: "data"
# Master 节点服务名称
masterService: "helm-master"
# 节点权限,为 True 的是提供相关服务,Data 节点不需要 Master 权限
roles:
master: "false"
ingest: "true"
data: "true"
# 节点数量
replicas: 3 # 作为数据节点,设置多些,一般根据主分片及副本数确定max的扩展节点数,max = num_shards + num_replicas * num_shards
esMajorVersion: "6"
esConfig:
# elasticsearch.yml 配置,同 Master 节点配置
elasticsearch.yml: |
xpack:
security:
enabled: true
transport:
ssl:
enabled: true
verification_mode: certificate
keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
monitoring:
collection:
enabled: true
extraEnvs:
# 同 Master 节点配置
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: elastic-credentials
key: username
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: elastic-credentials
key: password
envFrom: []
secretMounts:
# 证书挂载,同 Master 节点配置
- name: elastic-certificates
secretName: elastic-certificates
path: /usr/share/elasticsearch/config/certs
image: "docker.elastic.co/elasticsearch/elasticsearch"
imageTag: "6.8.18"
imagePullPolicy: "IfNotPresent"
imagePullSecrets:
- name: registry-secret
podAnnotations: {}
labels: {}
# ES节点的 JVM 内存分配,根据实际情况进行增加
esJavaOpts: "-Xmx512m -Xms512m"
# ES 运行所需的资源
resources:
requests:
cpu: "1000m"
memory: "1Gi"
limits:
cpu: "1000m"
memory: "1Gi"
initResources: {}
sidecarResources: {}
# ES 的服务 IP,如果没有设置这个,服务有可能无法启动。
networkHost: "0.0.0.0"
# ES 数据存储
volumeClaimTemplate:
storageClassName: "local-storage"
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Gi
# PVC 开关
persistence:
enabled: true
labels:
enabled: false
annotations: {}
# rbac 暂未详细研究
rbac:
create: false
serviceAccountAnnotations: {}
serviceAccountName: ""
# 镜像部署选择节点
# nodeSelector:
# elk-rolse: data
# 容忍污点,如果 K8S 集群节点较少,需要在 Master 节点部署,需要使用此项
tolerations:
- operator: "Exists"
helm安装master/data的release:
helm install es-m -nelk -f es-master.yaml elastic/elasticsearch --version 6.8.18 --debug > master.log
helm install es-d -nelk -f es-data.yaml elastic/elasticsearch --version 6.8.18 --debug > data.log
查看po的运行状况
等待一会,待集群自动发现后,全部处于ready状态:

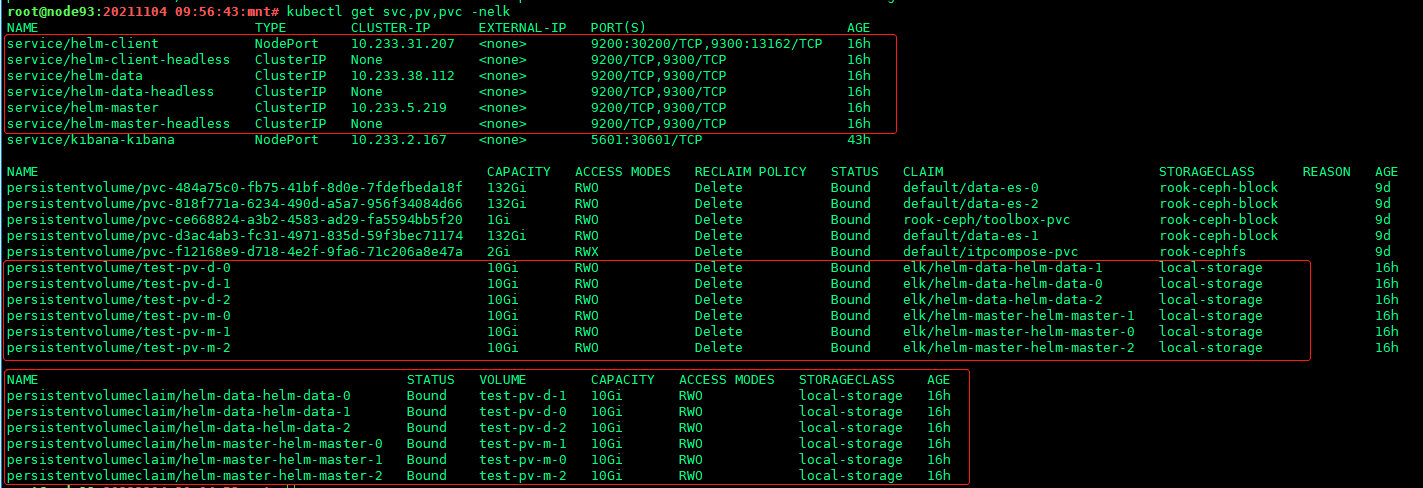
查看svc,pv,pvc的状态
可以看到svc全部成功,pv全部bound, 随着es-roleX.yaml的release的创建,pvc自动创建,也全部bound状态
es的discovery.zen使用单播unicast机制来发现处于同一集群名下的es实例,cluster.name,即通过绑定集群主节点的headless的svc来发现同一集群下的机器,具体见如下:
root@node91:20211104 10:08:10:es-values# grep -C 5 headless master.log
---
# Source: elasticsearch/templates/service.yaml
kind: Service
apiVersion: v1
metadata:
name: helm-master-headless
labels:
heritage: "Helm"
release: "es-m"
chart: "elasticsearch"
app: "helm-master"
--
chart: "elasticsearch"
app: "helm-master"
annotations:
esMajorVersion: "6"
spec:
serviceName: helm-master-headless
selector:
matchLabels:
app: "helm-master"
replicas: 3
podManagementPolicy: Parallel
--
fieldRef:
fieldPath: metadata.name
- name: discovery.zen.minimum_master_nodes
value: "2"
- name: discovery.zen.ping.unicast.hosts
value: "helm-master-headless"
- name: cluster.name
value: "helm"
- name: network.host
value: "0.0.0.0"
- name: ES_JAVA_OPTS
root@node91:20211104 10:08:17:es-values# grep -C 5 headless data.log
---
# Source: elasticsearch/templates/service.yaml
kind: Service
apiVersion: v1
metadata:
name: helm-data-headless
labels:
heritage: "Helm"
release: "es-d"
chart: "elasticsearch"
app: "helm-data"
--
chart: "elasticsearch"
app: "helm-data"
annotations:
esMajorVersion: "6"
spec:
serviceName: helm-data-headless
selector:
matchLabels:
app: "helm-data"
replicas: 3
podManagementPolicy: Parallel
--
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.zen.ping.unicast.hosts
value: "helm-master-headless"
- name: cluster.name
value: "helm"
- name: network.host
value: "0.0.0.0"
- name: ES_JAVA_OPTS
root@node91:20211104 10:08:40:es-values# grep -C 5 headless client.log
---
# Source: elasticsearch/templates/service.yaml
kind: Service
apiVersion: v1
metadata:
name: helm-client-headless
labels:
heritage: "Helm"
release: "es-c"
chart: "elasticsearch"
app: "helm-client"
--
chart: "elasticsearch"
app: "helm-client"
annotations:
esMajorVersion: "6"
spec:
serviceName: helm-client-headless
selector:
matchLabels:
app: "helm-client"
replicas: 2
podManagementPolicy: Parallel
--
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.zen.ping.unicast.hosts
value: "helm-master-headless"
- name: cluster.name
value: "helm"
- name: network.host
value: "0.0.0.0"
- name: ES_JAVA_OPTS
查看集群健康状况:
任意节点下curl, 因为es是去中心化的(peer to peer, p2p),访问任意一个节点,返回结果都是一样的
# curl -u elastic:elastic123456 http://172.22.118.91:30200/_cluster/health?pretty
---
{
"cluster_name" : "helm",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 8, # 3-master,3-data,2-client
"number_of_data_nodes" : 3, # 3-data
"active_primary_shards" : 12,
"active_shards" : 24,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
---
在kibana上查看节点的情况:

可看到master-2节点是集群的主节点。
进一步查看索引indices的状态:

新建一批index,设置其shards和replicas的数目,由于data节点测试的节点数为3个,建议主分片的shards数量也设置为3个,另外副本分片replicas的数量设置大于等于1,也不要过大,否则导致副本分片没有分配到节点上,总之考虑高可用的情况下,保证分片都可被分配到节点上,应该设置每个节点都有主分片,副本分片最好大于等于1,性能随着副本数增加成开口下下抛物线型。
health-tips:
green: 分片都分配到节点上,集群可用
yellow: 有分片没有分配到节点上,但可以使用,分片数量设置不合理
red: 集群不可用
遇到问题
1.helm install release时,etcdserver request请求超时
报错:

2.重启install release集群时,需要清理挂载path


 浙公网安备 33010602011771号
浙公网安备 33010602011771号