
一些排序算法的学习笔记
简述:把一个数组看成一个装水的桶,数组中的每个元素的值代表其质量。一开始这些元素被我用箩筐一把倒进桶里,在浮力影响下,这些元素根据自身的质量(值)自行沉浮。
值最大的沉入桶底,值最小的浮在桶顶,其它依次按自身值有序入座。
给个示例数组: var arr = [3,7,2,1,5,3,-4].map((e, i) => ({i, val: e}));
----------------------------------排序过程如下-----------------------------------------------
初始状态:3, 7, 2, 1,5,3, -4
第一轮把最大元素沉入桶底:
3, (7, 2 ), 1, 5, 3, -4 | 括弧中的2个元素需要交换,因为7 > 2,7沉下去,2要浮上去
3, 2, (7, 1), 5, 3, -4 | 括弧中的2个元素需要交换,因为7 > 1,7沉下去,1要浮上去
3, 2, 1, (7, 5), 3, -4 | 括弧中的2个元素需要交换,因为7 > 5,7沉下去,5要浮上去
3, 2, 1, 5, (7, 3), -4 | 括弧中的2个元素需要交换,因为7 > 3,7沉下去,3要浮上去
3, 2, 1, 5, 3, (7, -4) | 括弧中的2个元素需要交换,因为7 > -4,7沉下去,-4要浮上去
3, 2, 1, 5, 3, -4, 7
第一轮排序结束,最大的元素7沉入桶底,接下来只要排序除去7之外的arr.length - 1个元素了,即 3, 2, 1, 5, 3, -4
重复第二轮,第三轮,......,直至最后一轮(第六轮)完成最终的排序,结果为 [-4,1,2,3,3,5,7]
为什么总共要排序arr.length - 1轮?显然,最后一个元素-4本身是不需要排序的,因此比数组总数目少1。
代码实现:(1)设数组长度为len,最外层循环为len - 1次,用变量 i 计数, i ∈ [0, len -1);(2)内层循环用来依次比较和交换相邻的元素,用变量 j 来计数,arr[j] > arr[j +1]则交换swap(arr, j, j+1),
由于内层排序的元素数目随着总的排序轮数递增而递减,因此 j 的上界应该满足 j < len - 1 - i。
1 function bubbleSort(arr) { 2 for (let i = 0, len = arr.length; i < len - 1; i++) { 3 for (let j = 0; j < len - 1 - i; j++) { 4 if (arr[j].val > arr[j+1].val) { 5 let tmp = arr[j]; 6 arr[j] = arr[j+1]; 7 arr[j+1] = tmp; 8 } 9 } 10 } 11 }
输出结果:

发现索引为0值为3的元素在索引为5值为3的元素前面,和排序前的状态一致,表明冒泡排序是稳定排序。
从冒泡排序的过程知道,每轮排序比较都是前者严格大于后者才交换,因此最终对于值相等的元素初始位置状态未造成破坏,故是稳定排序。
时间复杂度计算:\(n-1 + n-2+ ... + 1 = n^2-n\),去掉常数项后为\(O(n^2)\)。
优化:
冒泡排序还可以进一步优化。
数组arr = [5, 8, 6, 3, 9, 2, 1, 7],len = 8,用上面的冒泡排序会执行7轮排序,每一轮排序结果如下:
第一轮:5, 6, 3, 8, 2, 1, 7, ( 9 )
第二轮:5, 3, 6, 2, 1, 7, ( 8, 9 )
第三轮:3, 5, 2, 1, 6, ( 7, 8, 9 )
第四轮:3, 2, 1, 5, ( 6, 7, 8, 9 )
第五轮:2, 1, 3, ( 5, 6, 7, 8, 9 )
第六轮:1, 2, ( 3, 5, 6, 7, 8, 9 )
第七轮:1, ( 2, 3, 5, 6, 7, 8, 9 )
观察发现第六轮排序结束整个数组已经是有序的了,但仍然执行了第七轮排序,第七轮其实是将1和2比较了一次,而这个在第六轮的时候是把2和1比较然后交换成有序序列,所以第七轮比较没有意义。
怎么优化?可以在每轮排序前设一个标志位isSorted = true,默认为true表示序列有序,然后在排序过程中如果发生交换操作则把isSorted置为false,在一轮排序结束时判断isSorted是否是true,若是true表明
本轮排序没有执行交换,没有执行交换证明整个数组是有序的,就break,中断外层循环结束,表明没必要执行后面多余的排序了。
代码:
1 function bubbleSort(arr) { 2 for (let i = 0, len = arr.length; i < len - 1; i++) { 3 let isSorted = true; 4 for (let j = 0; j < len - 1 - i; j++) { 5 if (arr[j].val > arr[j+1].val) { 6 let tmp = arr[j]; 7 arr[j] = arr[j+1]; 8 arr[j+1] = tmp; 9 isSorted = false; 10 } 11 } 12 if (isSorted) { 13 break; 14 } 15 // console.log(`第${i+1}轮`); 16 // console.log(arr.map(e => e.val)); 17 } 18 }
注释:优化后,其实第七轮排序还是执行了,第七轮执行的目的是检查数组是否有序,如果这个数组有序后还执行不止一轮的排序,那么还是能减少多余的排序的。假如排序算法优化前需要执行n次排序,
但前m次排序后数组已经有序,则优化后的代码实际能减少n - m + 1轮排序,+1是需要一轮排序来检查数组是否有序。
当前版本的冒泡排序其实还有进一步的优化空间, 但是由于这种入门级的排序算法在实际工作和生产中没有多少应用价值,就不做过多的笔记了。
简述:拿打牌比喻,你依次摸了5张牌,4、5、7、8、6,看一眼就把6那张牌插到5后面7前面组成一个顺子45678。五张牌的初态是前面四张是有序的,第五张牌6是小于前面2张牌,所以把6插入第一张不大于6的那张牌5的后面。而写程序时我们需要依次将6和8、7、5进行比较直到找到第一个小于6的元素或搜索到arr[0],从而确认6应该插入的位置,其实人看牌的时候大脑也执行了比较过程。 插入排序就是这个理。
----------------------------------排序过程如下-----------------------------------------------
用方括号包围的是有序区
初始状态:[3], 7, 2, 1,5,3, -4
第一轮: [3, 7], 2, 1, 5, 3, -4 // 7大于3,不需要交换,有序区长度加1
第二轮: [2, 3, 7], 1, 5, 3, -4 // 2小于7,2小于3,2和3交换,有序区长度加1
第三轮: [1, 2, 3, 7], 5, 3, -4 ...
第四轮: [1, 2, 3, 5, 7], 3, -4
第五轮: [1, 2, 3, 3, 5, 7], -4
第六轮: [-4, 1, 2, 3, 3, 5, 7]
编码思路:(1)首先我们假如数组左边从索引0开始维护了一个有序区,有序区默认有一个元素就是arr[0];(2)设有序区长度为m,我们遍历有序区右侧n - m个元素,对每个元素arr[i],将其与有序区右侧第一个元素arr[m-1](有序区中最大的元素)比较,如果arr[i] >= arr[m-1],则有序区长度增加1,即m++,i++重复之前操作;(3)j = m-1,如果arr[i] < arr[j],先用tmp临时保存arr[i]以避免多余的交换,用arr[j+1]替换arr[j] ,j--,不断重复,用前一个覆盖后一个位置的元素,直到在有序区中搜索第一个小于arr[i]的元素arr[k]或者到达下界j = 0了,终止循环,此时的j就是i应该插入的位置,arr[j] = tmp,完成替换。过程中要用临时变量k保存更新的j。
代码:
1 function insertSort(arr) { 2 for(let i = 1, len = arr.length; i < len; i++) { 3 if (arr[i].val >= arr[i-1].val) continue; 4 let tmp = arr[i], k = i; 5 for (let j = i-1; j >=0; j--) { 6 if (tmp.val < arr[j].val) { 7 arr[j+1] = arr[j]; 8 k = j; 9 } else { 10 break; 11 } 12 } 13 arr[k] = tmp; 14 } 15 }
插入排序的时间复杂度:\(O(n^2) \),属于稳定排序。
如果初始状态存在很长的有序区,那么实际要比较交换的次数就会少很多,复杂度会接近线性。下面简单说明下:
设数组长度为n,初始有序区长度为m,则实际需要插入的元素为(n - m),则总的计算量大约为(n - m ) * m,当m很大或接近于n时,n-m就趋于0,试想如果有序区等于数组长度,即数组本身就有序的,那么就循环遍历数组一次,每次判断都是当前元素arr[i] > arr[i-1],复杂度就接近\(O(m)\).
简述:把一筐里面10个大小不一的桃子拿出来排成一个序列。从序列里挑一个最小的桃子跟序列第一个位置的桃子交换(如果刚好最小的桃子就在第一个位置就不用和自身交换了),接下来去掉第一个位置的桃子,从剩余的桃子中再挑一个最小的和第二个位置的桃子交换,不断重复这种操作,最后这个序列的桃子就是从小到大有序排列的了。这就是选择排序:)
----------------------------------排序过程如下-----------------------------------------------
用方括号包围的是有序区
初始状态:3, 7, 2, 1,5,3, -4
第一轮: [-4], 7, 2, 1, 5, 3, 3 // 遍历整个数组, 找到最小的-4,和一个元素3交换,第1个位置现在是最小的元素了
第二轮: [-4, 1], 2, 7, 5, 3, 3 // 从第二个位置开始遍历数组,找到最小的元素1和第二个位置元素交换
第三轮: [-4, 1, 2], 7, 5, 3, 3 ...
第四轮: [-4, 1, 2, 3], 5, 7, 3
第五轮: [-4, 1, 2, 3, 3], 7, 5
第六轮: [-4, 1, 2, 3, 3, 5, 7]
编码思路:1、设数组arr的长度为n,由于每次都从数组剩余部分(非有序区)中找最小的元素放到剩余部分的第一个位置,因此最外层循环次数可以确定为n-1,剩余最后一个元素肯定是最大的;
2、设数组有序区长度为m,遍历数组剩余部分长度为n - m,找最小元素需要循环n-m次,下界是j = m,上界是 j < n
3、找到最小的元素arr[k],与剩余部分的第一个位置arr[m]进行交换, swap(arr, k, m)
1 function selectSort(arr) { 2 for(let i = 0, len = arr.length; i < len - 1; i++) { 3 let minIndex = i; 4 for (let j = i + 1; j < len; j++) { 5 if (arr[j].val < arr[minIndex].val) { 6 minIndex = j; 7 } 8 } 9 let tmp = arr[i]; 10 arr[i] = arr[minIndex]; 11 arr[minIndex] = tmp; 12 } 13 }
从下面的排序结果看,相同的val的3在排序后原本的顺序颠倒了,索引为5的节点排到索引为0的节点前面了,选择排序是不稳定排序。不稳定的原因在于选取后续的最小元素与第一个位置元素进行交换的时候容易打乱原本值相同的节点位置。

选择排序时间复杂度也是\(O(n^2)\),如果数组本身比较有序,这对选择排序每次寻找最小元素也没什么帮助。选择排序对输入的数据不敏感,复杂度依然没有变化,而插入排序相对就会有更好的性能。
简介:有一盒宝石,宝石的价值大多不一样,每个宝石上面有个标签标识了价值。我把宝石从盒子里随机取出来排成一个序列,然后我想通过调整某些宝石的位置以使宝石按价值从小到大依次排列。首先我取第一个宝石作为分割点pivot,把价值小于pivot的宝石挪到pivot左边,价值大于pivot的挪到pviot的右边。现在序列被分割成三部分:两个子序列leftPart和rigthPart、pivot,显然leftPart中的宝石价值小于rightPart中宝石价值,而pivot宝石当前所处的位置不会再改变了,就是其在最终有序序列中的位置。我们继续在对leftPart和rightPart序列分别重复前面的操作,宝石序列不断被新的pivot分割成更小的序列,当分割的子序列只有一个宝石,它不能继续划分了(可以假设若继续划分,则pviot就是它本身,左右两边的子序列为空),已经触及边界了。最后所有子序列的pviot都在划分挪动宝石的过程中交换到它们在最终有序序列中的位置,因此所有的宝石都排序完成了,这就是快速排序的基本原理:分而治之(按pviot分割序列)、交换(挪动宝石)。
编码思路:(1)数组arr长度是n = arr.length,分治法可用递归实现,定义递归函数quickSort(arr),每次分割后的数组我们都传入quickSort获取排序后的结果,不要先去想quickSort做了什么,先假设它直接返回了我们需要的结果;(2)试想下边界条件,如果arr中只有一个元素,那么pviot就是那一个元素,分割的左右子序列是空的,因此我们返回 [pivot] 就行了;(3)arr的长度大于1,我们取第一个元素为pviot,pivot = arr[0],然后定义2个空的子序列 leftPart = [], rightPart = [] 用于在遍历数组 arr 的时候分别存取小于 pivot 和大于等于 pivot 的元素;最后,在quickSort函数的底部我们依次对leftPart和rightPart执行递归调用,即 const leftOrderPart = quickSort(leftPart); const rightOrderPart = quickSort(rightPart),注意依次执行,递归调用的顺序不能错的;最后返回leftOrderPart、pviot、rightOrderPart连接组成的新的数组。
代码实现:
1 function quickSort(arr) { 2 const len = arr.length; 3 if (len <= 1) return arr; 4 const pivot = arr[0], leftPart = [], rightPart = []; 5 for (let i = 1; i < len; i++) { 6 if (arr[i].val < pivot.val) { 7 leftPart.push(arr[i]); 8 } else { 9 rightPart.push(arr[i]); 10 } 11 } 12 const leftOrderPart = quickSort(leftPart); 13 const rightOrderPart = quickSort(rightPart); 14 return leftOrderPart.concat([pivot]).concat(rightOrderPart); 15 }
时间复杂度计算:分治法每次一分为二总的复杂度是logN,加上每一轮栈中根据pivot交换数组元素的计算量约为N,因此总的复杂度是\(O(NlogN)\),如果pivot取的恰好是数组中的最值,复杂度为\(O(N^2)\),所以一般先把初始的数组随机打乱下再开始排序。
快速排序是不稳定排序。
快速排序实现起来是不是也很简单:) 。 但这个版本的代码实现只能帮助理解快速原理,性能还有很大问题。代码中每次分割数组的时候都创建了2个空数组来临时存储pviot两边的元素,随着数据量的增大和递归层次的加深,这在空间上是不小的开销,而且反复创建数组和销毁数组对象在内存分配和回收上也是性能开销。能不能实现一个原地算法,只是通过交换原数组中的元素来实现把pviot移动到最终的有序数组中的位置且确保其左右两边的元素分别不大于和不小于它呢?
优化:
思路:数组的第一个元素 arr[0] 是 pivot,右边 n-1 个位置可以用来存储分割的两个部分:\( leftPart=\left\{a_i | i \in [1, k] \right\},rightPart=\left\{ a_j | j \in [k + 1, n -1]\right\},a_i < pivot < a_j \) ;通过用pivot右边的元素和pivot进行比较不断调整右侧元素的位置来实现上面的目标。开始leftPart和rightPart位置上的元素一般不满足要求,我们需要不断交换两个集合中的元素来实现leftPart中的元素都小于pivot,rightPart中的元素都大于等于pivot。
做法:
(1)可以通过2个指针 i 、j 来分别表示 leftPart 集合的上边界和rightPart的下边界,用lo、hi指针分别表示 i 、j 的初始位置指针,lo = 0, hi = n (n表示数组长度),leftPart通过指针 i 从索引为 lo 的位置向右边扩充范围,rightPart 通过指针 j 从 hi 处开始向左边扩充范围,初始状态 i = lo, j = hi, leftPart 和 rightPart 区域长度均是0;
(2) i 先向右边移动,如果 arr[i] < pivot,证明当前位置元素归属 leftPart集合,继续向右移动指针 i,如果 i == hi,此时触及了数组的上界,终止当前循环移位操作;如果 arr[i] >= pivot,那么 arr[i] 这个元素应该归属于 rightPart集合,终止当前移位操作;
(3)指针 i 移位操作终止了,现在轮到 指针 j 开始左移操作了,若 arr[j] >= pivot, 和指针 i 的操作逻辑类似,arr[j] 归属于 rightPart 集合,继续左移指针,j 触及数组下界 lo 时同样终止移位操作;若 arr[j] < pivot,则 arr[j] 应该归属于 leftPart 集合,终止移位操作;
(4)当 指针i 、j 都终止了移位操作,要判断各自终止原因再确认是否把 leftPart、rightPart 中遭遇到位置不合适(out of place)的元素互相交换以确保leftPart 和 rightPart 重新变得 “和谐”;若 i >= j,表明两个指针重合或互相越过对方了,则表明 leftPart 和 rightPart 的各自边界扩充已经完成,本轮 pivot 分割数组操作已完成,要开始下轮操作了,下轮操作对 leftPart 和 rightPart 部分分别递归重复上面的操作逻辑即可;若i < j 表明边界扩充仍在进行,此时交换 arr[i] 和 arr[j], 解决 leftPart 和 rightPart 中遭遇的元素位置不和谐问题;
(5)由 (4)知道当最终 leftPart 和 rightPart 划分完成时,i >= j,此时 j 处的位置应该是leftPart范围内了(包括leftPart的上边界),所以 arr[j] 肯定小于 pivot, j 应该是 pivot最终在有序数组中的最终位置,因此交换 pivot 和 arr[j], pivot原来在索引为 0 的位置,在leftPart集合左侧,现在 arr[j] 被交换过去刚好和 leftPart连续起来;为什么 pivot 不和 arr[i] 交换呢?这个想想应该很简单,i 一直向右边扩充,i >= j 时 i 很可能进入 rightPart 了,pivot交换到 rightPart 中, arr[i] 不小于 leftPart 集合中的元素,交换到 索引为 0 的位置,处于leftPart左侧肯定不对。具体这些都是编码过程的边界问题,边界问题有时候比较麻烦。
(6)一轮分割与交换完成后开始对 leftPart 和 rightPart 部分分别递归重复上面的操作逻辑,写法应该是这样,数组arr变量放在最外层作为全局的变量,分割与交换逻辑封装成partition函数,函数接受lo和hi并返回 j,定义sort函数调用partition函数传入lo, hi, 根据 lo、hi 和 partition函数返回的 j 来划分下一轮的 lo 和 hi,sort(lo, j -1); sort(j + 1, hi)。
代码实现: 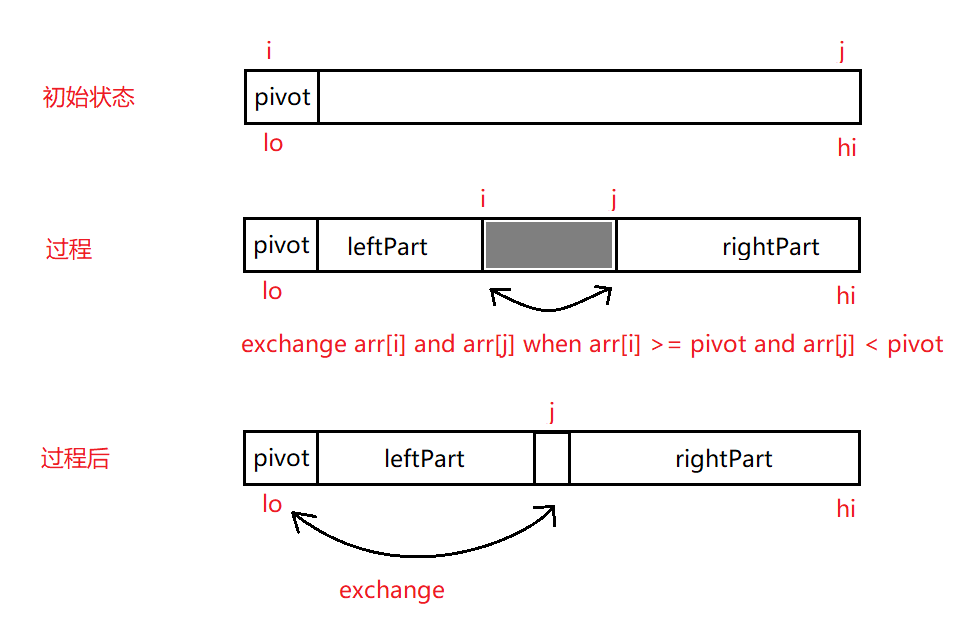
1 function quickSort(arr) { 2 const partition = (lo, hi) => { 3 let i = lo, j = hi + 1, pivot = arr[lo]; 4 while (true) { 5 while (arr[++i].val < pivot.val) if (i === hi) break; 6 while (arr[--j].val > pivot.val) if (j === lo) break; 7 if (i >= j) break; 8 exchange(arr, i, j); 9 // console.log(arr.slice(lo, hi + 1).map(e => e.val)); 10 } 11 12 exchange(arr, lo, j); 13 // console.log('j = '+j); 14 // console.log(arr.slice(lo, hi + 1).map(e => e.val)); 15 return j; 16 }; 17 18 const sort = (lo, hi) => { 19 if (hi <= lo) return; 20 let pivotIndex = partition(lo, hi); 21 sort(lo, pivotIndex - 1); 22 sort(pivotIndex + 1, hi); 23 }; 24 25 sort(0, arr.length - 1); 26 // console.log(arr.map(e => e.val)); 27 } 28 29 function exchange(arr, i, j) { 30 let tmp = arr[i]; 31 arr[i] = arr[j]; 32 arr[j] = tmp; 33 }
上面代码每次把元素(pivot)移动到最终有序数组中的位置处进行了大量交换,下面代码实现通过缓存覆盖的形式消除了多余的交换,代码更简洁:
1 function partition(arr, lo, hi) { 2 let pivot = arr[lo]; 3 while(lo < hi) { 4 while(lo < hi && arr[hi] >= pivot) hi--; 5 arr[lo] = arr[hi]; 6 7 while(lo < hi && arr[lo] <= pivot) lo++; 8 arr[hi] = arr[lo]; 9 } 10 arr[lo] = pivot; 11 return lo; 12 }; 13 14 function quickSort(arr, lo, hi) { 15 if(lo >= hi) return; 16 let p = partition(arr, lo, hi); 17 quickSort(arr, lo, p - 1); 18 quickSort(arr, p + 1, hi); 19 };
快速排序的应用示例:快速查找Top K 元素:
问题描述:返回数组arr中的第k大的元素,如:arr = [3,1,0,2,7,5,4,8,6],k = 3,则返回6。
思路:主要利用快速排序的parttion函数,控制partition返回的分割点位置p,由于求的是第k大的元素,快速排序数组从小到大排,则第k大的元素位置k = arr.length - k,p == k则直接返回结果arr[k], p < k 则 从[p+1, hi] 区间进行划分, p > k 则[lo, p-1] 区间进行划分。代码实现如下:
1 function partition(arr, lo, hi) { 2 let pivot = arr[lo]; 3 while(lo < hi) { 4 while(lo < hi && arr[hi] >= pivot) hi--; 5 arr[lo] = arr[hi]; 6 while(lo < hi && arr[lo] <= pivot) lo++; 7 arr[hi] = arr[lo]; 8 } 9 10 arr[lo] = pivot; 11 return lo; 12 } 13 14 function findTopK(arr, k) { 15 k = arr.length - k; // 第k大 16 // k = k - 1; // 第k小 17 let lo = 0, hi = arr.length - 1; 18 while (lo < hi) { 19 let p = partition(arr, lo, hi); 20 if (p === k) { 21 break; 22 } else if (p < k) { 23 lo = p + 1; 24 } else { 25 hi = p - 1; 26 } 27 } 28 return arr[k]; 29 }
三路快速排序:
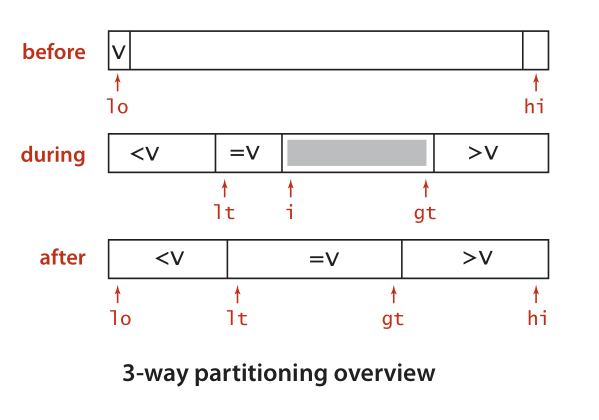
对包含大量重复的key的大数据集排序,快速排序还有一个专门的优化版本叫三路快速排序。前面讨论的是两路快排,对数组划分小于pivot和大于pivot两个部分,而三路快排则加了一个等于pivot的部分,对于数据集中有大量重复的元素, 这些重复key的元素会被移动到一个连续的区域,这个区域中元素位置固定了且区域后续不断扩大不会再进行内部排序了,节省了很多不必要的交换操作,因此提高了性能。 这个版本的三路快排是E. W. Dijkstra提出的。
代码:
/* * three way quick sort * best performance for larget set with many repeat keys */ function quick3waySortDijkstra(arr) { const sort = (lo, hi) => { if (hi <= lo) return; let lt = lo, i = lo + 1, gt = hi; let pivot = arr[lo]; while (i <= gt) { if (arr[i].val < pivot.val) { exchange(arr, lt++, i++); } else if (arr[i].val > pivot.val) { exchange(arr, i, gt--); } else { i++; } } sort(lo, lt - 1); sort(gt + 1, hi); }; sort(0, arr.length - 1); }
但是由于相对二路快排增加了太多的交换次数,导致对重复key很少的数据集排序性能不如二路快速排序。
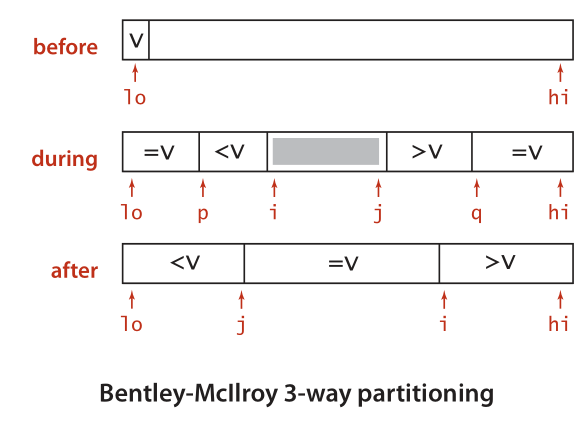
后来J. Bentley and D. McIlroy改善了三路快速排序的实现, 在重复key的元素不是很多的情况下交换次数和二路快排相比差距不大,性能方面取得了平衡。
代码:
/* * Improved the three way partition implementation * balance performance for larget set with many repeat keys or not */ function quick3waySortBentleyMcIlroy(arr) { const sort = (lo, hi) => { if (hi <= lo) return; let p = lo + 1, i = lo + 1, j = hi, q = hi, v = arr[lo]; while (true) { while (i <= j) { if (arr[i].val < v.val) { i++; } else if (arr[i].val === v.val) { exchange(arr, i++, p++); } else { break; } } while (j >= i) { if (arr[j].val > v.val) { j--; } else if (arr[j].val === v.val) { exchange(arr, j--, q--); } else { break; } } if (i >= j) { break; } exchange(arr, i++, j--); } // swap items with equal keys into position for (let k = lo; k < p; k++) { exchange(arr, k, j--); } for (let k = hi; k > q; k--) { exchange(arr, k, i++); } sort(lo, j); sort(i, hi); }; sort(0, arr.length - 1); }
简介:有一箩筐大小不一的苹果,把它们随机取出来排成一个序列然后给它们排序。我先从中间一分为二,把苹果分成2个子序列,对2个子序列的苹果继续分别重复执行当前一分为二的操作。当我分割分割分割,分到最后得到2个只有一个苹果的子序列怎么办?这时候不能再分割了,只有一个苹果的子序列是有序的,开始合并有序的子序列,把两个有序的子序列合并成一个有序的序列,继续向上合并,直到所有序列都合并完成,最后整个序列有序了,这个就是归并排序的思路。
编码思路:重点是怎么合并有序序列,如果2个子序列都只有一个苹果,直接比较交换放到一个数组中就行了。如果一个序列3个苹果,一个序列5苹果,要怎么比较和交换呢?设2个子序列arr1 = [1, 4, 7], arr2 = [2, 3, 5, 9],创建一个长度等于arr1.length + arr2.length的数组arr用于存储合并后的数组元素;由于2个待合并的序列都是有序的,我们循环依次从arr1、arr2中取苹果,然后比较2个苹果大小,把小的苹果取出来放到arr中,比如arr1中取的苹果是1, arr2中取的苹果是2,先把1放进arr中,再继续从取走苹果的序列中取苹果4和arr2中还未取走的苹果2比较,显然2比较小,取走放到数组arr中,arr现在有2个苹果了[1, 2];不断重复这样每次取最小的苹果操作,直到2个子序列都没苹果了,如果某个序列中的苹果先取完了,那么剩余的序列的所有苹果依次取出放到arr中就行了。看来合并有序序列的操作也不复杂:)。
代码实现:
1 function mergeSort(arr) { 2 if (arr.length <= 1) return arr; 3 const len = arr.length; 4 const mid = len >> 1; 5 6 let arr1 = mergeSort(arr.slice(0, mid)); 7 let arr2 = mergeSort(arr.slice(mid, len)); 8 9 let result = []; 10 while (arr1.length > 0 && arr2.length > 0) { 11 if (arr1[0].val <= arr2[0].val) { 12 result.push(arr1.shift()); 13 } else { 14 result.push(arr2.shift()) 15 } 16 } 17 if (arr1.length !== 0) { 18 result.push(...arr1); 19 } 20 if (arr2.length !== 0) { 21 result.push(...arr2); 22 } 23 24 return result; 25 }
归并排序时间复杂度是\(O(NlogN)\)。从合并有序序列的操作可以发现val相同的元素顺序不会被打乱,因此是稳定排序。
上面的代码实现存在性能问题。由于每次合并操作都需要创建一个临时数组用来存放合并后的序列,若待排序的数据集很大,则创建临时数组也是一笔不小的性能开销;而且每次合并后是返回一个新数组,如果实现一个原地合并方法(in-place merge method)性能会更好些。
优化:先全局创建一个可动态扩容的数组help = [],每次执行合并操作时先把2个子序列的元素依次copy到help中对应索引位置,最后再把help中的元素copy到原数组中的对应位置完成合并,这样只需要一个全局的临时数组help并且每次都是原地修改原数组没有再返回新创建的数组,性能会更好。
代码:
function mergeSort(arr, lo = 0, hi = arr.length-1) { const help = []; const merge = (lo, hi) => { if (hi - lo < 1) return; const mid = lo + ((hi - lo) >> 1); merge(lo, mid); merge(mid + 1, hi); for (let i = lo; i <= hi; i++) { help[i] = arr[i]; } for (let k = lo, i = lo, j = mid + 1; k <= hi; k++) { if (i > mid) { arr[k] = help[j++]; } else if (j > hi) { arr[k] = help[i++]; } else if (help[i].val > help[j].val) { arr[k] = help[j++]; } else { arr[k] = help[i++]; } } } merge(lo, hi); }
简介:有一筐仙桃,个头都很大,但不是都一样大。现在我把仙桃在桌子上堆个金字塔来招待一只猴子,金字塔顶放最小的仙桃。猴子客人非常高兴,但它有点怪,每次都拿塔顶最小的桃子吃,想把较大的仙桃留到最后享受。它每拿走塔顶的仙桃享用时我都匆忙地调整金字塔,把余下最小的仙桃再挪到塔顶。不断重复这种操作,直到金字塔只剩一个仙桃了,这个肯定是最大的仙桃,我也不用调整金字塔,猴子拿走最大的仙桃欢快地向我告别。如果我每次记录下猴子拿走的仙桃尺寸,发现是从小到大的有序序列。这整个过程就类似给仙桃排序,就是堆排序的大致思路。
思路:堆排序中的堆是二叉堆,分大顶堆和小顶堆, 是用完全二叉树实现的数据结构。以小顶堆为例,堆顶是最小的元素,二叉堆有自我调节功能(sink和swim),我取走堆顶的最小元素后,堆会自动把余下最小的元素上浮(swim)到堆顶,而这个过程中发生比较,大的元素下沉(sink)。当然可以每次把取走堆顶元素依次插入到一个结果数组result中,这个result数组最后肯定就是有序序列,但这样空间复杂度是\(O(N)\)了。可以这样优化,因为堆是完全二叉树,子节点位置能通过父节点位置直接计算得到(若parent位置是 i , 则左子节点位置是 2 * i + 1,右子节点位置是 2 * i + 2),因此可以用顺序存储结构存储堆;定义堆顶为数组表头元素,每次将堆顶元素与数组倒数第k(k初始值为1)个元素交换,调节堆的长度为n - k,k是数组末尾追加的元素,当k = n,整个数组就是有序的了。
代码:
function heapSort(arr) { const sink = (parentIndex, length) => { let temp = arr[parentIndex]; let childIndex = 2 * parentIndex + 1; while (childIndex < length) { // 如果有右子节点且右子节点值大于左子节点,则定位到右子节点 if (childIndex + 1 < length && arr[childIndex + 1].val > arr[childIndex].val) { childIndex++; } // 如果父节点大于任何一个子节点的值,直接跳出 if (temp.val >= arr[childIndex].val) { break; } arr[parentIndex] = arr[childIndex]; parentIndex = childIndex; childIndex = 2 * childIndex + 1; } arr[parentIndex] = temp; }; /* * 1、把无序数组构建成大顶堆 * 从最后一个非叶子节点开始执行下沉操作,设最后一个非叶子节点位置是k, * 则左子节点位置是2k + 1,右子节点位置是2k + 2,最后一个叶子节点可能是左子节点或右子节点, * 因此 len = 2k + 1 + 1 或 len = 2k + 2 + 1, k = Math.floor((len - 2) / 2) * k = (len - 2) >> 1 */ for (let i = (arr.length - 2) >> 1; i >= 0; i--) { sink(i, arr.length); } // 2、循环删除堆顶元素,移到集合末尾,调节堆产生新的堆顶 for (let i = arr.length - 1; i > 0; i--) { // 最后一个元素和第一个元素交换 let temp = arr[i]; arr[i] = arr[0]; arr[0] = temp; // 下沉调整大顶堆 sink(0, i); } }
堆排序时间复杂度\(O(NlogN)\),空间复杂度\(O(1)\)。
堆排序是不稳定排序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号