
上文solr源码分析之数据导入DataImporter追溯中提到了solr的工作流程,其核心是各种handler。
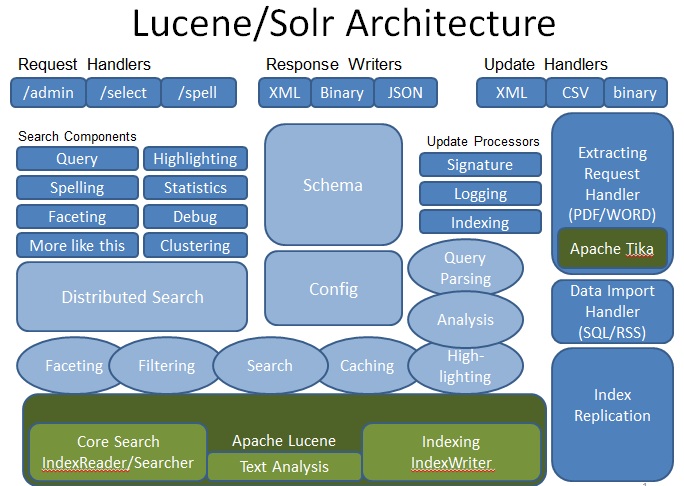
handler定义了各种search Component,
@Override public void handleRequestBody(SolrQueryRequest req, SolrQueryResponse rsp) throws Exception { List<SearchComponent> components = getComponents(); ResponseBuilder rb = new ResponseBuilder(req, rsp, components); }
然后调用组件的prepare方法:
if (timer == null) { // non-debugging prepare phase for( SearchComponent c : components ) { c.prepare(rb); } } else { // debugging prepare phase RTimer subt = timer.sub( "prepare" ); for( SearchComponent c : components ) { rb.setTimer( subt.sub( c.getName() ) ); c.prepare(rb); rb.getTimer().stop(); } subt.stop(); }
再调用组件的process方法:
if(!rb.isDebug()) { // Process for( SearchComponent c : components ) { c.process(rb); } } else { // Process RTimer subt = timer.sub( "process" ); for( SearchComponent c : components ) { rb.setTimer( subt.sub( c.getName() ) ); c.process(rb); rb.getTimer().stop(); } subt.stop(); // add the timing info if (rb.isDebugTimings()) { rb.addDebugInfo("timing", timer.asNamedList() ); } }
从源码上来分析一下search Component,searchComponent的结构如下:

以QueryComponent为例,理解一下它的工作原理。
prepare方法获取查询语句:
@Override public void prepare(ResponseBuilder rb) throws IOException { SolrQueryRequest req = rb.req; SolrParams params = req.getParams(); if (!params.getBool(COMPONENT_NAME, true)) { return; } SolrQueryResponse rsp = rb.rsp; // Set field flags ReturnFields returnFields = new SolrReturnFields( req ); rsp.setReturnFields( returnFields ); int flags = 0; if (returnFields.wantsScore()) { flags |= SolrIndexSearcher.GET_SCORES; } rb.setFieldFlags( flags ); String defType = params.get(QueryParsing.DEFTYPE, QParserPlugin.DEFAULT_QTYPE); // get it from the response builder to give a different component a chance // to set it. String queryString = rb.getQueryString(); if (queryString == null) { // this is the normal way it's set. queryString = params.get( CommonParams.Q ); rb.setQueryString(queryString); } try { QParser parser = QParser.getParser(rb.getQueryString(), defType, req); Query q = parser.getQuery(); if (q == null) { // normalize a null query to a query that matches nothing q = new MatchNoDocsQuery(); } rb.setQuery( q ); String rankQueryString = rb.req.getParams().get(CommonParams.RQ); if(rankQueryString != null) { QParser rqparser = QParser.getParser(rankQueryString, defType, req); Query rq = rqparser.getQuery(); if(rq instanceof RankQuery) { RankQuery rankQuery = (RankQuery)rq; rb.setRankQuery(rankQuery); MergeStrategy mergeStrategy = rankQuery.getMergeStrategy(); if(mergeStrategy != null) { rb.addMergeStrategy(mergeStrategy); if(mergeStrategy.handlesMergeFields()) { rb.mergeFieldHandler = mergeStrategy; } } } else { throw new SolrException(SolrException.ErrorCode.BAD_REQUEST,"rq parameter must be a RankQuery"); } } rb.setSortSpec( parser.getSort(true) ); rb.setQparser(parser); final String cursorStr = rb.req.getParams().get(CursorMarkParams.CURSOR_MARK_PARAM); if (null != cursorStr) { final CursorMark cursorMark = new CursorMark(rb.req.getSchema(), rb.getSortSpec()); cursorMark.parseSerializedTotem(cursorStr); rb.setCursorMark(cursorMark); } String[] fqs = req.getParams().getParams(CommonParams.FQ); if (fqs!=null && fqs.length!=0) { List<Query> filters = rb.getFilters(); // if filters already exists, make a copy instead of modifying the original filters = filters == null ? new ArrayList<Query>(fqs.length) : new ArrayList<>(filters); for (String fq : fqs) { if (fq != null && fq.trim().length()!=0) { QParser fqp = QParser.getParser(fq, null, req); filters.add(fqp.getQuery()); } } // only set the filters if they are not empty otherwise // fq=&someotherParam= will trigger all docs filter for every request // if filter cache is disabled if (!filters.isEmpty()) { rb.setFilters( filters ); } } } catch (SyntaxError e) { throw new SolrException(SolrException.ErrorCode.BAD_REQUEST, e); } if (params.getBool(GroupParams.GROUP, false)) { prepareGrouping(rb); } else { //Validate only in case of non-grouping search. if(rb.getSortSpec().getCount() < 0) { throw new SolrException(SolrException.ErrorCode.BAD_REQUEST, "'rows' parameter cannot be negative"); } } //Input validation. if (rb.getQueryCommand().getOffset() < 0) { throw new SolrException(SolrException.ErrorCode.BAD_REQUEST, "'start' parameter cannot be negative"); } }
process方法执行查询:
/** * Actually run the query */ @Override public void process(ResponseBuilder rb) throws IOException { LOG.debug("process: {}", rb.req.getParams()); SolrQueryRequest req = rb.req; SolrParams params = req.getParams(); if (!params.getBool(COMPONENT_NAME, true)) { return; } SolrIndexSearcher searcher = req.getSearcher(); StatsCache statsCache = req.getCore().getStatsCache(); int purpose = params.getInt(ShardParams.SHARDS_PURPOSE, ShardRequest.PURPOSE_GET_TOP_IDS); if ((purpose & ShardRequest.PURPOSE_GET_TERM_STATS) != 0) { statsCache.returnLocalStats(rb, searcher); return; } // check if we need to update the local copy of global dfs if ((purpose & ShardRequest.PURPOSE_SET_TERM_STATS) != 0) { // retrieve from request and update local cache statsCache.receiveGlobalStats(req); } SolrQueryResponse rsp = rb.rsp; IndexSchema schema = searcher.getSchema(); // Optional: This could also be implemented by the top-level searcher sending // a filter that lists the ids... that would be transparent to // the request handler, but would be more expensive (and would preserve score // too if desired). String ids = params.get(ShardParams.IDS); if (ids != null) { SchemaField idField = schema.getUniqueKeyField(); List<String> idArr = StrUtils.splitSmart(ids, ",", true); int[] luceneIds = new int[idArr.size()]; int docs = 0; for (int i=0; i<idArr.size(); i++) { int id = searcher.getFirstMatch( new Term(idField.getName(), idField.getType().toInternal(idArr.get(i)))); if (id >= 0) luceneIds[docs++] = id; } DocListAndSet res = new DocListAndSet(); res.docList = new DocSlice(0, docs, luceneIds, null, docs, 0); if (rb.isNeedDocSet()) { // TODO: create a cache for this! List<Query> queries = new ArrayList<>(); queries.add(rb.getQuery()); List<Query> filters = rb.getFilters(); if (filters != null) queries.addAll(filters); res.docSet = searcher.getDocSet(queries); } rb.setResults(res); ResultContext ctx = new ResultContext(); ctx.docs = rb.getResults().docList; ctx.query = null; // anything? rsp.add("response", ctx); return; } // -1 as flag if not set. long timeAllowed = params.getLong(CommonParams.TIME_ALLOWED, -1L); if (null != rb.getCursorMark() && 0 < timeAllowed) { // fundamentally incompatible throw new SolrException(SolrException.ErrorCode.BAD_REQUEST, "Can not search using both " + CursorMarkParams.CURSOR_MARK_PARAM + " and " + CommonParams.TIME_ALLOWED); } SolrIndexSearcher.QueryCommand cmd = rb.getQueryCommand(); cmd.setTimeAllowed(timeAllowed); req.getContext().put(SolrIndexSearcher.STATS_SOURCE, statsCache.get(req)); SolrIndexSearcher.QueryResult result = new SolrIndexSearcher.QueryResult(); // // grouping / field collapsing // GroupingSpecification groupingSpec = rb.getGroupingSpec(); if (groupingSpec != null) { try { boolean needScores = (cmd.getFlags() & SolrIndexSearcher.GET_SCORES) != 0; if (params.getBool(GroupParams.GROUP_DISTRIBUTED_FIRST, false)) { CommandHandler.Builder topsGroupsActionBuilder = new CommandHandler.Builder() .setQueryCommand(cmd) .setNeedDocSet(false) // Order matters here .setIncludeHitCount(true) .setSearcher(searcher); for (String field : groupingSpec.getFields()) { topsGroupsActionBuilder.addCommandField(new SearchGroupsFieldCommand.Builder() .setField(schema.getField(field)) .setGroupSort(groupingSpec.getGroupSort()) .setTopNGroups(cmd.getOffset() + cmd.getLen()) .setIncludeGroupCount(groupingSpec.isIncludeGroupCount()) .build() ); } CommandHandler commandHandler = topsGroupsActionBuilder.build(); commandHandler.execute(); SearchGroupsResultTransformer serializer = new SearchGroupsResultTransformer(searcher); rsp.add("firstPhase", commandHandler.processResult(result, serializer)); rsp.add("totalHitCount", commandHandler.getTotalHitCount()); rb.setResult(result); return; } else if (params.getBool(GroupParams.GROUP_DISTRIBUTED_SECOND, false)) { CommandHandler.Builder secondPhaseBuilder = new CommandHandler.Builder() .setQueryCommand(cmd) .setTruncateGroups(groupingSpec.isTruncateGroups() && groupingSpec.getFields().length > 0) .setSearcher(searcher); for (String field : groupingSpec.getFields()) { SchemaField schemaField = schema.getField(field); String[] topGroupsParam = params.getParams(GroupParams.GROUP_DISTRIBUTED_TOPGROUPS_PREFIX + field); if (topGroupsParam == null) { topGroupsParam = new String[0]; } List<SearchGroup<BytesRef>> topGroups = new ArrayList<>(topGroupsParam.length); for (String topGroup : topGroupsParam) { SearchGroup<BytesRef> searchGroup = new SearchGroup<>(); if (!topGroup.equals(TopGroupsShardRequestFactory.GROUP_NULL_VALUE)) { searchGroup.groupValue = new BytesRef(schemaField.getType().readableToIndexed(topGroup)); } topGroups.add(searchGroup); } secondPhaseBuilder.addCommandField( new TopGroupsFieldCommand.Builder() .setField(schemaField) .setGroupSort(groupingSpec.getGroupSort()) .setSortWithinGroup(groupingSpec.getSortWithinGroup()) .setFirstPhaseGroups(topGroups) .setMaxDocPerGroup(groupingSpec.getGroupOffset() + groupingSpec.getGroupLimit()) .setNeedScores(needScores) .setNeedMaxScore(needScores) .build() ); } for (String query : groupingSpec.getQueries()) { secondPhaseBuilder.addCommandField(new QueryCommand.Builder() .setDocsToCollect(groupingSpec.getOffset() + groupingSpec.getLimit()) .setSort(groupingSpec.getGroupSort()) .setQuery(query, rb.req) .setDocSet(searcher) .build() ); } CommandHandler commandHandler = secondPhaseBuilder.build(); commandHandler.execute(); TopGroupsResultTransformer serializer = new TopGroupsResultTransformer(rb); rsp.add("secondPhase", commandHandler.processResult(result, serializer)); rb.setResult(result); return; } int maxDocsPercentageToCache = params.getInt(GroupParams.GROUP_CACHE_PERCENTAGE, 0); boolean cacheSecondPassSearch = maxDocsPercentageToCache >= 1 && maxDocsPercentageToCache <= 100; Grouping.TotalCount defaultTotalCount = groupingSpec.isIncludeGroupCount() ? Grouping.TotalCount.grouped : Grouping.TotalCount.ungrouped; int limitDefault = cmd.getLen(); // this is normally from "rows" Grouping grouping = new Grouping(searcher, result, cmd, cacheSecondPassSearch, maxDocsPercentageToCache, groupingSpec.isMain()); grouping.setSort(groupingSpec.getGroupSort()) .setGroupSort(groupingSpec.getSortWithinGroup()) .setDefaultFormat(groupingSpec.getResponseFormat()) .setLimitDefault(limitDefault) .setDefaultTotalCount(defaultTotalCount) .setDocsPerGroupDefault(groupingSpec.getGroupLimit()) .setGroupOffsetDefault(groupingSpec.getGroupOffset()) .setGetGroupedDocSet(groupingSpec.isTruncateGroups()); if (groupingSpec.getFields() != null) { for (String field : groupingSpec.getFields()) { grouping.addFieldCommand(field, rb.req); } } if (groupingSpec.getFunctions() != null) { for (String groupByStr : groupingSpec.getFunctions()) { grouping.addFunctionCommand(groupByStr, rb.req); } } if (groupingSpec.getQueries() != null) { for (String groupByStr : groupingSpec.getQueries()) { grouping.addQueryCommand(groupByStr, rb.req); } } if (rb.doHighlights || rb.isDebug() || params.getBool(MoreLikeThisParams.MLT, false)) { // we need a single list of the returned docs cmd.setFlags(SolrIndexSearcher.GET_DOCLIST); } grouping.execute(); if (grouping.isSignalCacheWarning()) { rsp.add( "cacheWarning", String.format(Locale.ROOT, "Cache limit of %d percent relative to maxdoc has exceeded. Please increase cache size or disable caching.", maxDocsPercentageToCache) ); } rb.setResult(result); if (grouping.mainResult != null) { ResultContext ctx = new ResultContext(); ctx.docs = grouping.mainResult; ctx.query = null; // TODO? add the query? rsp.add("response", ctx); rsp.getToLog().add("hits", grouping.mainResult.matches()); } else if (!grouping.getCommands().isEmpty()) { // Can never be empty since grouping.execute() checks for this. rsp.add("grouped", result.groupedResults); rsp.getToLog().add("hits", grouping.getCommands().get(0).getMatches()); } return; } catch (SyntaxError e) { throw new SolrException(SolrException.ErrorCode.BAD_REQUEST, e); } } // normal search result searcher.search(result, cmd); rb.setResult(result); ResultContext ctx = new ResultContext(); ctx.docs = rb.getResults().docList; ctx.query = rb.getQuery(); rsp.add("response", ctx); rsp.getToLog().add("hits", rb.getResults().docList.matches()); if ( ! rb.req.getParams().getBool(ShardParams.IS_SHARD,false) ) { if (null != rb.getNextCursorMark()) { rb.rsp.add(CursorMarkParams.CURSOR_MARK_NEXT, rb.getNextCursorMark().getSerializedTotem()); } } if(rb.mergeFieldHandler != null) { rb.mergeFieldHandler.handleMergeFields(rb, searcher); } else { doFieldSortValues(rb, searcher); } doPrefetch(rb); }

微信公众号: 架构师日常笔记 欢迎关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号