转自:http://www.blogjava.net/changedi/archive/2012/04/15/374226.html
vlist是一种列表的实现。结构如下图:
 (图来源wikipedia)
(图来源wikipedia)
类似链接表的结构,但是,不是线性的。它的结构基于一种2的幂次扩展,第一个链接节点包含了列表的前一半数据,第二个包含了剩下一半的一半,依次递归。节点的基本结构不像LinkedList的节点是双端队列,每个VListCell包含了下个节点的指针mNext和前一个节点的指针mPrev,同时内置一个数组mElems用来存放当前节点的数据集合,包含一个数字指针指向当前数组元素的位置。举个例子,如果有个Vlist包含10个元素,分别是1-10的整数,而且是按升序顺序插入的,那么vlist的结构数据时这样的: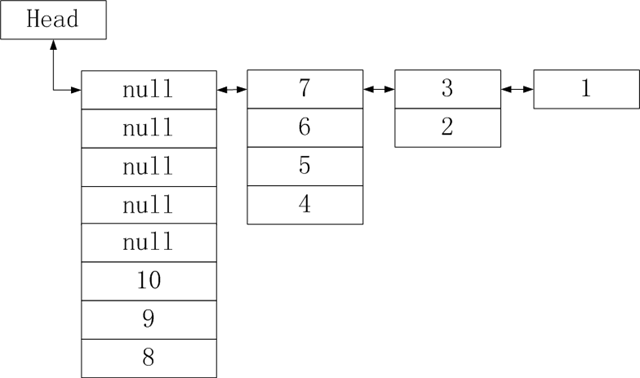
VList基于数组实现,在add操作时,每次会把元素插入到list的最前面一个节点内的mElems的最后一个位置,首先判断head,如果head的元素数组已经满了,那么就增加一个头节点并扩容其elems数组为2倍,然后插入到位置指针所指向的地方去,时间是O(1)的。而在get操作时,要首先定位第n个元素的位置,会进行一次locate定位操作,接着直接返回数组中的该locate位置即可。定位操作实质是二分的,但是因为VList本身就是一个单向的二分表,因此顺序判断即可,时间复杂度是平均O(1)和最坏情况O(log n)。对应get的set操作,复杂度和步骤完全一样。当然最最恶心的还是remove操作了,因为基于数组,且本身结构有意义(特定的),所以删除会复杂一些,首先一个O(log n)的locate定位,找到元素后,删掉之后,是把它之前的所有元素后移一位,当然这个移位操作并不是特别复杂,只要把当前节点的全部后移,然后如果当前节点有前驱节点,那么前驱的最后一个元素覆盖当前节点第一个元素,如此反复直到当前节点指针为空结束,时间复杂度是O(n)的。
我做了一个perf test来测试性能,发现这个不伦不类的list在arralist和linkedlist面前显得是脆弱的。那它的作用体现在哪里呢?简单的设计和良好的结构,满足add和get的平衡,对于list后半部分的数据的操作具有很好的性能,像个数组,但是又和其前半部分有快速的链接关系,对于其数组的不可变性也是最好的用于函数式编程的典范(来源于wikipedia的翻译)
源代码如下,继承了jdk中的AbstractList<T>:
1: public final class VList<T> extends AbstractList<T> { 2: 3: /** 4: * A single cell in the VList implementation. 5: */ 6: private static final class VListCell<T> { 7: public final T[] mElems; 8: public final VListCell<T> mNext; 9: 10: /* 11: * This field is not mutable because when new elements are added/deleted 12: * from the main list, the previous pointer needs to be updated. 13: * However, next links never change because the list only grows in one 14: * direction. 15: */ 16: public VListCell<T> mPrev; 17: 18: /* 19: * The number of unused elements in this cell. Alternatively, you can 20: * think of this as the index in the array in which the first used 21: * element appears. Both interpretations are used in this 22: * implementation. 23: */ 24: public int mFreeSpace; 25: 26: /** 27: * Constructs a new VListCell with the specified number of elements and 28: * specified next element. 29: * 30: * @param numElems 31: * The number of elements this cell should have space for. 32: * @param next 33: * The cell in the list of cells that follows this one. 34: */ 35: public VListCell(int numElems, VListCell<T> next) { 36: mElems = (T[]) new Object[numElems]; 37: mNext = next; 38: mPrev = null; 39: 40: /* Update the next cell to point back to us. */ 41: if (next != null) 42: next.mPrev = this; 43: 44: /* We have free space equal to the number of elements. */ 45: mFreeSpace = numElems; 46: } 47: } 48: 49: /** 50: * A utility struct containing information about where an element is in the 51: * VList. Methods that need to manipulate individual elements of the list 52: * use this struct to communicate where in the list to look for that 53: * element. 54: */ 55: private static final class VListLocation<T> { 56: public final VListCell<T> mCell; 57: public final int mOffset; 58: 59: public VListLocation(VListCell<T> cell, int offset) { 60: mCell = cell; 61: mOffset = offset; 62: } 63: } 64: 65: /* 66: * Pointer to the head of the VList, which contains the final elements of 67: * the list. 68: */ 69: private VListCell<T> mHead; 70: 71: /* Cached total number of elements in the array. */ 72: private int mSize; 73: 74: /** 75: * Adds a new element to the end of the array. 76: * 77: * @param elem 78: * The element to add. 79: * @return true 80: */ 81: @Override 82: public boolean add(T elem) { 83: /* If no free space exists, add a new element to the list. */ 84: if (mHead == null || mHead.mFreeSpace == 0) 85: mHead = new VListCell<T>(mHead == null ? 1 86: : mHead.mElems.length * 2, mHead); 87: 88: /* Prepend this element to the current cell. */ 89: mHead.mElems[(mHead.mFreeSpace--) - 1] = elem; 90: ++mSize; 91: 92: /* Success! */ 93: return true; 94: } 95: 96: /** 97: * Given an absolute offset into the VList, returns an object describing 98: * where that object is in the VList. 99: * 100: * @param index 101: * The index into the VList. 102: * @return A VListLocation object holding information about where that 103: * element can be found. 104: */ 105: private VListLocation<T> locateElement(int index) { 106: /* Bounds-check. */ 107: if (index >= size() || index < 0) 108: throw new IndexOutOfBoundsException("Position " + index + "; size " 109: + size()); 110: 111: /* 112: * Because the list is stored with new elements in front and old 113: * elements in back, we'll invert the index so that 0 refers to the 114: * final element of the array and size() - 1 refers to the first 115: * element. 116: */ 117: index = size() - 1 - index; 118: 119: /* 120: * Scan across the cells, looking for the first one that can hold our 121: * entry. We do this by continuously skipping cells until we find one 122: * that can be sure to hold this element. 123: * 124: * Note that each cell has mElems.length elements, of which mFreeSpace 125: * is used. This means that the total number of used elements in each 126: * cell is mElems.length - mFreeSpace. 127: */ 128: VListCell<T> curr = mHead; 129: while (index >= curr.mElems.length - curr.mFreeSpace) { 130: /* Skip past all these elements. */ 131: index -= curr.mElems.length - curr.mFreeSpace; 132: curr = curr.mNext; 133: } 134: 135: /* 136: * We're now in the correct location for what we need to do. The element 137: * we want can be found by indexing the proper amount beyond the free 138: * space. 139: */ 140: return new VListLocation<T>(curr, index + curr.mFreeSpace); 141: } 142: 143: /** 144: * Scans for the proper location in the cell list for the element, then 145: * returns the element at that position. 146: * 147: * @param index 148: * The index at which to look up the element. 149: * @return The element at that position. 150: */ 151: @Override 152: public T get(int index) { 153: VListLocation<T> where = locateElement(index); 154: 155: /* Return the element in the current position of this array. */ 156: return where.mCell.mElems[where.mOffset]; 157: } 158: 159: /** 160: * Returns the cached size. 161: * 162: * @return The size of the VList. 163: */ 164: @Override 165: public int size() { 166: return mSize; 167: } 168: 169: /** 170: * Sets an element at a particular position to have a particular value. 171: * 172: * @param index 173: * The index at which to write a new value. 174: * @param value 175: * The value to write at that position. 176: * @return The value originally held at that position. 177: */ 178: @Override 179: public T set(int index, T value) { 180: VListLocation<T> where = locateElement(index); 181: 182: /* Cache the element in the current position of this array. */ 183: T result = where.mCell.mElems[where.mOffset]; 184: where.mCell.mElems[where.mOffset] = value; 185: return result; 186: } 187: 188: /** 189: * Removes the element at the specified position from the VList, returning 190: * its value. 191: * 192: * @param index 193: * The index at which the element should be removed. 194: * @return The value held at that position. 195: */ 196: @Override 197: public T remove(int index) { 198: VListLocation<T> where = locateElement(index); 199: 200: /* Cache the value that will be removed. */ 201: T result = where.mCell.mElems[where.mOffset]; 202: 203: /* Invoke the helper to do most of the work. */ 204: removeAtPosition(where); 205: 206: return result; 207: } 208: 209: /** 210: * Removes the element at the indicated VListLocation. 211: * 212: * @param where 213: * The location at which the element should be removed. 214: */ 215: private void removeAtPosition(VListLocation<T> where) { 216: /* 217: * Scan backward across the blocks after this element, shuffling array 218: * elements down a position and copying the last element of the next 219: * block over to fill in the top. 220: * 221: * The variable shuffleTargetPosition indicates the first element of the 222: * block that should be overwritten during the shuffle-down. In the 223: * first block, this is the position of the element that was 224: * overwritten. In all other blocks, it's the last element. 225: */ 226: VListCell<T> curr = where.mCell; 227: for (int shuffleTargetPosition = where.mOffset; curr != null; curr = curr.mPrev, shuffleTargetPosition = (curr == null ? 0 228: : curr.mElems.length - 1)) { 229: /* 230: * Shuffle down each element in the current array on top of the 231: * target position. Note that in the final block, this may end up 232: * copying a whole bunch of null values down. This is more work than 233: * necessary, but is harmless and doesn't change the asymptotic 234: * runtime (since the last block has size O(n)). 235: */ 236: for (int i = shuffleTargetPosition - 1; i >= 0; --i) 237: curr.mElems[i + 1] = curr.mElems[i]; 238: 239: /* 240: * Copy the last element of the next array to the top of this array, 241: * unless this is the first block (in which case there is no next 242: * array). 243: */ 244: if (curr.mPrev != null) 245: curr.mElems[0] = curr.mPrev.mElems[curr.mPrev.mElems.length - 1]; 246: } 247: 248: /* 249: * The head just lost an element, so it has some more free space. Null 250: * out the lost element and increase the free space. 251: */ 252: ++mHead.mFreeSpace; 253: mHead.mElems[mHead.mFreeSpace - 1] = null; 254: 255: /* The whole list just lost an element. */ 256: --mSize; 257: 258: /* If the head is entirely free, remove it from the list. */ 259: if (mHead.mFreeSpace == mHead.mElems.length) { 260: mHead = mHead.mNext; 261: 262: /* 263: * If there is at least one block left, remove the previous block 264: * from the linked list. 265: */ 266: if (mHead != null) 267: mHead.mPrev = null; 268: } 269: } 270: 271: /** 272: * A custom iterator class that traverses the elements of this container in 273: * an intelligent way. The normal iterator will call get repeatedly, which 274: * is slow because it has to continuously scan for the proper location of 275: * the next element. This iterator works by traversing the cells as a proper 276: * linked list. 277: */ 278: private final class VListIterator implements Iterator<T> { 279: /* 280: * The cell and position in that cell that we are about to visit. We 281: * maintain the invariant that if there is a next element, mCurrCell is 282: * non-null and conversely that if mCurrCell is null, there is no next 283: * element. 284: */ 285: private VListCell<T> mCurrCell; 286: private int mCurrIndex; 287: 288: /* 289: * Stores whether we have something to remove (i.e. whether we've called 290: * next() without an invervening remove()). 291: */ 292: private boolean mCanRemove; 293: 294: /** 295: * Constructs a new VListIterator that will traverse the elements of the 296: * containing VList. 297: */ 298: public VListIterator() { 299: /* 300: * Scan to the tail using the "pointer chase" algorithm. When this 301: * terminates, prev will hold a pointer to the last element of the 302: * list. 303: */ 304: VListCell<T> curr, prev; 305: for (curr = mHead, prev = null; curr != null; prev = curr, curr = curr.mNext) 306: ; 307: 308: /* Set the current cell to the tail. */ 309: mCurrCell = prev; 310: 311: /* 312: * If the tail isn't null, it must be a full list of size 1. Set the 313: * current index appropriately. 314: */ 315: if (mCurrCell != null) 316: mCurrIndex = 0; 317: } 318: 319: /** 320: * As per our invariant, returns whether mCurrCell is non-null. 321: */ 322: public boolean hasNext() { 323: return mCurrCell != null; 324: } 325: 326: /** 327: * Advances the iterator and returns the element it used to be over. 328: */ 329: public T next() { 330: /* Bounds-check. */ 331: if (!hasNext()) 332: throw new NoSuchElementException(); 333: 334: /* Cache the return value; we'll be moving off of it soon. */ 335: T result = mCurrCell.mElems[mCurrIndex]; 336: 337: /* Back up one step. */ 338: --mCurrIndex; 339: 340: /* 341: * If we walked off the end of the buffer, advance to the next 342: * element of the list. 343: */ 344: if (mCurrIndex < mCurrCell.mFreeSpace) { 345: mCurrCell = mCurrCell.mPrev; 346: 347: /* 348: * Update the next get location, provided of course that we 349: * didn't just walk off the end of the list. 350: */ 351: if (mCurrCell != null) 352: mCurrIndex = mCurrCell.mElems.length - 1; 353: } 354: 355: /* Since there was indeed an element, we can remove it. */ 356: mCanRemove = true; 357: 358: return result; 359: } 360: 361: /** 362: * Removes the last element we visited. 363: */ 364: public void remove() { 365: /* Check whether there's something to remove. */ 366: if (!mCanRemove) 367: throw new IllegalStateException( 368: "remove() without next(), or double remove()."); 369: 370: /* Clear the flag saying we can do this. */ 371: mCanRemove = false; 372: 373: /* 374: * There are several cases to consider. If the current cell is null, 375: * we've walked off the end of the array, so we want to remove the 376: * very last element. If the current cell isn't null and the cursor 377: * is in the middle, remove the previous element and back up a step. 378: * If the current cell isn't null and the cursor is at the front, 379: * remove the element one step before us and back up a step. 380: */ 381: 382: /* Case 1. */ 383: if (mCurrCell == null) 384: VList.this.remove(size() - 1); 385: /* Case 2. */ 386: else if (mCurrIndex != mCurrCell.mElems.length - 1) { 387: /* 388: * Back up a step, and remove the element at this position. 389: * After the remove completes, the element here should be the 390: * next element to visit. 391: */ 392: ++mCurrIndex; 393: removeAtPosition(new VListLocation<T>(mCurrCell, mCurrIndex)); 394: } 395: /* Case 3. */ 396: else { 397: /* 398: * Back up a step to the top of the previous list. We know that 399: * the top will be at position 0, since all internal blocks are 400: * completely full. We also know that we aren't at the very 401: * front of the list, since if we were, then the call to next() 402: * that enabled this call would have pushed us to the next 403: * location. 404: */ 405: mCurrCell = mCurrCell.mNext; 406: mCurrIndex = 0; 407: removeAtPosition(new VListLocation<T>(mCurrCell, mCurrIndex)); 408: } 409: } 410: } 411: 412: /** 413: * Returns a custom iterator rather than the default. 414: */ 415: @Override 416: public Iterator<T> iterator() { 417: return new VListIterator(); 418: } 419: 420: }
参考资料:

微信公众号: 架构师日常笔记 欢迎关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号