从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Streaming process层是底层实现。
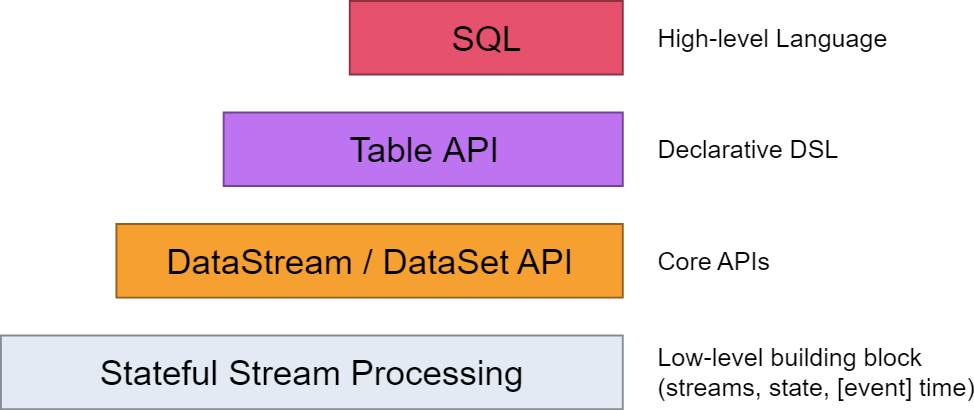
其中,
flink dataset api使用及原理 介绍了DataSet Api
flink DataStream API使用及原理介绍了DataStream Api
flink中的时间戳如何使用?---Watermark使用及原理 介绍了底层实现的基础Watermark
flink window实例分析 介绍了window的概念及使用原理
Flink中的状态与容错 介绍了State的概念及checkpoint,savepoint的容错机制
0. 基本概念:
0.1 TableEnvironment
TableEnvironment是Table API和SQL集成的核心概念,它主要负责:
2、注册一个外部目录Catalog
3、执行SQL查询
4、注册一个用户自定义函数UDF
5、将DataStream或者DataSet转换成Table
6、持有BatchTableEnvironment或者StreamTableEnvironment的引用
/** * The base class for batch and stream TableEnvironments. * * <p>The TableEnvironment is a central concept of the Table API and SQL integration. It is * responsible for: * * <ul> * <li>Registering a Table in the internal catalog</li> * <li>Registering an external catalog</li> * <li>Executing SQL queries</li> * <li>Registering a user-defined scalar function. For the user-defined table and aggregate * function, use the StreamTableEnvironment or BatchTableEnvironment</li> * </ul> */
0.2 Catalog
Catalog:所有对数据库和表的元数据信息都存放再Flink CataLog内部目录结构中,其存放了flink内部所有与Table相关的元数据信息,包括表结构信息/数据源信息等。
/** * This interface is responsible for reading and writing metadata such as database/table/views/UDFs * from a registered catalog. It connects a registered catalog and Flink's Table API. */
其结构如下:

0.3 TableSource
在使用Table API时,可以将外部的数据源直接注册成Table数据结构。此结构称之为TableSource
/** * Defines an external table with the schema that is provided by {@link TableSource#getTableSchema}. * * <p>The data of a {@link TableSource} is produced as a {@code DataSet} in case of a {@code BatchTableSource} * or as a {@code DataStream} in case of a {@code StreamTableSource}. The type of ths produced * {@code DataSet} or {@code DataStream} is specified by the {@link TableSource#getProducedDataType()} method. * * <p>By default, the fields of the {@link TableSchema} are implicitly mapped by name to the fields of * the produced {@link DataType}. An explicit mapping can be defined by implementing the * {@link DefinedFieldMapping} interface. * * @param <T> The return type of the {@link TableSource}. */
0.4 TableSink
数据处理完成后需要将结果写入外部存储中,在Table API中有对应的Sink模块,此模块为TableSink
/** * A {@link TableSink} specifies how to emit a table to an external * system or location. * * <p>The interface is generic such that it can support different storage locations and formats. * * @param <T> The return type of the {@link TableSink}. */
0.5 Table Connector
在Flink1.6版本之后,为了能够让Table API通过配置化的方式连接外部系统,且同时可以在sql client中使用,flink 提出了Table Connector的概念,主要目的时将Table Source和Table Sink的定义和使用分离。
通过Table Connector将不同内建的Table Source和TableSink封装,形成可以配置化的组件,在Table Api和Sql client能够同时使用。
/** * Creates a table source and/or table sink from a descriptor. * * <p>Descriptors allow for declaring the communication to external systems in an * implementation-agnostic way. The classpath is scanned for suitable table factories that match * the desired configuration. * * <p>The following example shows how to read from a connector using a JSON format and * register a table source as "MyTable": * * <pre> * {@code * * tableEnv * .connect( * new ExternalSystemXYZ() * .version("0.11")) * .withFormat( * new Json() * .jsonSchema("{...}") * .failOnMissingField(false)) * .withSchema( * new Schema() * .field("user-name", "VARCHAR").from("u_name") * .field("count", "DECIMAL") * .registerSource("MyTable"); * } *</pre> * * @param connectorDescriptor connector descriptor describing the external system */ TableDescriptor connect(ConnectorDescriptor connectorDescriptor);
本篇主要聚焦于sql和Table Api。
1.sql
1.1 基于DataSet api的sql
示例:
package org.apache.flink.table.examples.java; import org.apache.flink.api.java.DataSet; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.java.BatchTableEnvironment; /** * Simple example that shows how the Batch SQL API is used in Java. * * <p>This example shows how to: * - Convert DataSets to Tables * - Register a Table under a name * - Run a SQL query on the registered Table */ public class WordCountSQL { // ************************************************************************* // PROGRAM // ************************************************************************* public static void main(String[] args) throws Exception { // set up execution environment ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); BatchTableEnvironment tEnv = BatchTableEnvironment.create(env); DataSet<WC> input = env.fromElements( new WC("Hello", 1), new WC("Ciao", 1), new WC("Hello", 1)); // register the DataSet as table "WordCount" tEnv.registerDataSet("WordCount", input, "word, frequency"); // run a SQL query on the Table and retrieve the result as a new Table Table table = tEnv.sqlQuery( "SELECT word, SUM(frequency) as frequency FROM WordCount GROUP BY word"); DataSet<WC> result = tEnv.toDataSet(table, WC.class); result.print(); } // ************************************************************************* // USER DATA TYPES // ************************************************************************* /** * Simple POJO containing a word and its respective count. */ public static class WC { public String word; public long frequency; // public constructor to make it a Flink POJO public WC() {} public WC(String word, long frequency) { this.word = word; this.frequency = frequency; } @Override public String toString() { return "WC " + word + " " + frequency; } } }
其中,BatchTableEnvironment
/** * The {@link TableEnvironment} for a Java batch {@link ExecutionEnvironment} that works * with {@link DataSet}s. * * <p>A TableEnvironment can be used to: * <ul> * <li>convert a {@link DataSet} to a {@link Table}</li> * <li>register a {@link DataSet} in the {@link TableEnvironment}'s catalog</li> * <li>register a {@link Table} in the {@link TableEnvironment}'s catalog</li> * <li>scan a registered table to obtain a {@link Table}</li> * <li>specify a SQL query on registered tables to obtain a {@link Table}</li> * <li>convert a {@link Table} into a {@link DataSet}</li> * <li>explain the AST and execution plan of a {@link Table}</li> * </ul> */
BatchTableSource
/** Defines an external batch table and provides access to its data. * * @param <T> Type of the {@link DataSet} created by this {@link TableSource}. */
BatchTableSink
/** Defines an external {@link TableSink} to emit a batch {@link Table}. * * @param <T> Type of {@link DataSet} that this {@link TableSink} expects and supports. */
1.2 基于DataStream api的sql
示例代码
package org.apache.flink.table.examples.java; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.java.StreamTableEnvironment; import java.util.Arrays; /** * Simple example for demonstrating the use of SQL on a Stream Table in Java. * * <p>This example shows how to: * - Convert DataStreams to Tables * - Register a Table under a name * - Run a StreamSQL query on the registered Table * */ public class StreamSQLExample { // ************************************************************************* // PROGRAM // ************************************************************************* public static void main(String[] args) throws Exception { // set up execution environment StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); StreamTableEnvironment tEnv = StreamTableEnvironment.create(env); DataStream<Order> orderA = env.fromCollection(Arrays.asList( new Order(1L, "beer", 3), new Order(1L, "diaper", 4), new Order(3L, "rubber", 2))); DataStream<Order> orderB = env.fromCollection(Arrays.asList( new Order(2L, "pen", 3), new Order(2L, "rubber", 3), new Order(4L, "beer", 1))); // convert DataStream to Table Table tableA = tEnv.fromDataStream(orderA, "user, product, amount"); // register DataStream as Table tEnv.registerDataStream("OrderB", orderB, "user, product, amount"); // union the two tables Table result = tEnv.sqlQuery("SELECT * FROM " + tableA + " WHERE amount > 2 UNION ALL " + "SELECT * FROM OrderB WHERE amount < 2"); tEnv.toAppendStream(result, Order.class).print(); env.execute(); } // ************************************************************************* // USER DATA TYPES // ************************************************************************* /** * Simple POJO. */ public static class Order { public Long user; public String product; public int amount; public Order() { } public Order(Long user, String product, int amount) { this.user = user; this.product = product; this.amount = amount; } @Override public String toString() { return "Order{" + "user=" + user + ", product='" + product + '\'' + ", amount=" + amount + '}'; } } }
其中,StreamTableEnvironment
/** * The {@link TableEnvironment} for a Java {@link StreamExecutionEnvironment} that works with * {@link DataStream}s. * * <p>A TableEnvironment can be used to: * <ul> * <li>convert a {@link DataStream} to a {@link Table}</li> * <li>register a {@link DataStream} in the {@link TableEnvironment}'s catalog</li> * <li>register a {@link Table} in the {@link TableEnvironment}'s catalog</li> * <li>scan a registered table to obtain a {@link Table}</li> * <li>specify a SQL query on registered tables to obtain a {@link Table}</li> * <li>convert a {@link Table} into a {@link DataStream}</li> * <li>explain the AST and execution plan of a {@link Table}</li> * </ul> */
StreamTableSource
/** Defines an external stream table and provides read access to its data. * * @param <T> Type of the {@link DataStream} created by this {@link TableSource}. */
StreamTableSink
/** * Defines an external stream table and provides write access to its data. * * @param <T> Type of the {@link DataStream} created by this {@link TableSink}. */
2. table api
示例
package org.apache.flink.table.examples.java; import org.apache.flink.api.java.DataSet; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.java.BatchTableEnvironment; /** * Simple example for demonstrating the use of the Table API for a Word Count in Java. * * <p>This example shows how to: * - Convert DataSets to Tables * - Apply group, aggregate, select, and filter operations */ public class WordCountTable { // ************************************************************************* // PROGRAM // ************************************************************************* public static void main(String[] args) throws Exception { ExecutionEnvironment env = ExecutionEnvironment.createCollectionsEnvironment(); BatchTableEnvironment tEnv = BatchTableEnvironment.create(env); DataSet<WC> input = env.fromElements( new WC("Hello", 1), new WC("Ciao", 1), new WC("Hello", 1)); Table table = tEnv.fromDataSet(input); Table filtered = table .groupBy("word") .select("word, frequency.sum as frequency") .filter("frequency = 2"); DataSet<WC> result = tEnv.toDataSet(filtered, WC.class); result.print(); } // ************************************************************************* // USER DATA TYPES // ************************************************************************* /** * Simple POJO containing a word and its respective count. */ public static class WC { public String word; public long frequency; // public constructor to make it a Flink POJO public WC() {} public WC(String word, long frequency) { this.word = word; this.frequency = frequency; } @Override public String toString() { return "WC " + word + " " + frequency; } } }
3.数据转换
3.1 DataSet与Table相互转换
DataSet-->Table
注册方式:
// register the DataSet as table "WordCount" tEnv.registerDataSet("WordCount", input, "word, frequency");
转换方式:
Table table = tEnv.fromDataSet(input);
Table-->DataSet
DataSet<WC> result = tEnv.toDataSet(filtered, WC.class);
3.2 DataStream与Table相互转换
DataStream-->Table
注册方式:
tEnv.registerDataStream("OrderB", orderB, "user, product, amount");
转换方式:
Table tableA = tEnv.fromDataStream(orderA, "user, product, amount");
Table-->DataStream
DataSet<WC> result = tEnv.toDataSet(filtered, WC.class);
参考资料
【1】https://ci.apache.org/projects/flink/flink-docs-release-1.8/concepts/programming-model.html
【2】Flink原理、实战与性能优化

微信公众号: 架构师日常笔记 欢迎关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号