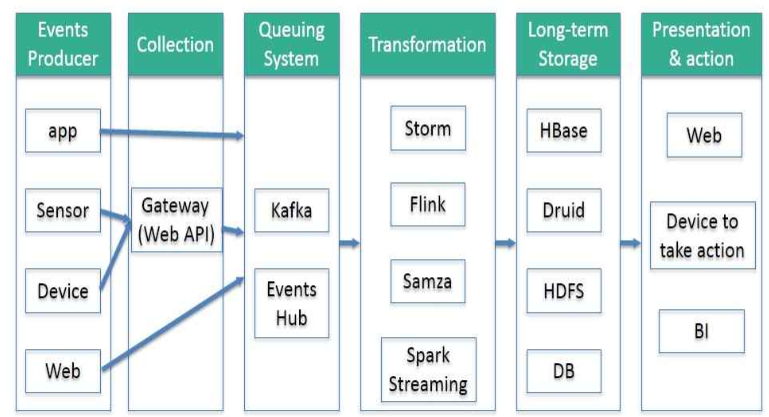
随着大数据技术在各行各业的广泛应用,要求能对海量数据进行实时处理的需求越来越多,同时数据处理的业务逻辑也越来越复杂,传统的批处理方式和早期的流式处理框架也越来越难以在延迟性、吞吐量、容错能力以及使用便捷性等方面满足业务日益苛刻的要求。
在这种形势下,新型流式处理框架Flink通过创造性地把现代大规模并行处理技术应用到流式处理中来,极大地改善了以前的流式处理框架所存在的问题。
1.概述:
flink提供DataSet Api用户处理批量数据。flink先将接入数据转换成DataSet数据集,并行分布在集群的每个节点上;然后将DataSet数据集进行各种转换操作(map,filter等),最后通过DataSink操作将结果数据集输出到外部系统。
2.数据接入
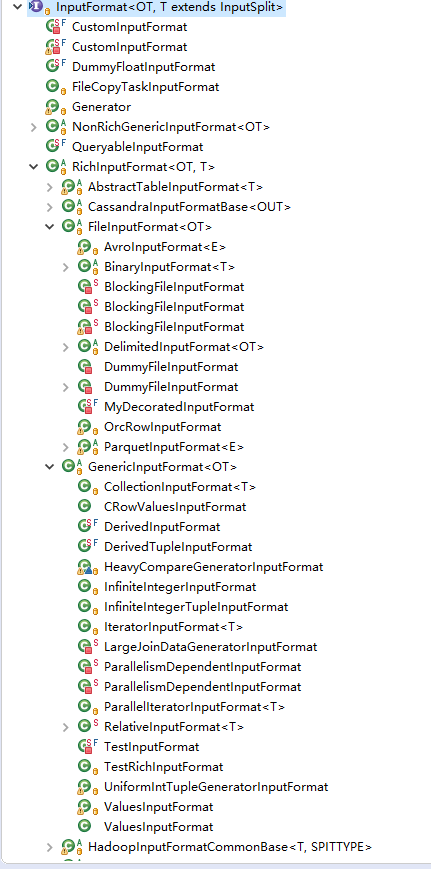
输入InputFormat
/**
* The base interface for data sources that produces records.
* <p>
* The input format handles the following:
* <ul>
* <li>It describes how the input is split into splits that can be processed in parallel.</li>
* <li>It describes how to read records from the input split.</li>
* <li>It describes how to gather basic statistics from the input.</li>
* </ul>
* <p>
* The life cycle of an input format is the following:
* <ol>
* <li>After being instantiated (parameterless), it is configured with a {@link Configuration} object.
* Basic fields are read from the configuration, such as a file path, if the format describes
* files as input.</li>
* <li>Optionally: It is called by the compiler to produce basic statistics about the input.</li>
* <li>It is called to create the input splits.</li>
* <li>Each parallel input task creates an instance, configures it and opens it for a specific split.</li>
* <li>All records are read from the input</li>
* <li>The input format is closed</li>
* </ol>
* <p>
* IMPORTANT NOTE: Input formats must be written such that an instance can be opened again after it was closed. That
* is due to the fact that the input format is used for potentially multiple splits. After a split is done, the
* format's close function is invoked and, if another split is available, the open function is invoked afterwards for
* the next split.
*
* @see InputSplit
* @see BaseStatistics
*
* @param <OT> The type of the produced records.
* @param <T> The type of input split.
*/
3.数据转换
DataSet:一组相同类型的元素。DataSet可以通过transformation转换成其它的DataSet。示例如下:
DataSet#map(org.apache.flink.api.common.functions.MapFunction)
DataSet#reduce(org.apache.flink.api.common.functions.ReduceFunction)
DataSet#join(DataSet)
DataSet#coGroup(DataSet)
其中,Function:用户定义的业务逻辑,支持java 8 lambda表达式
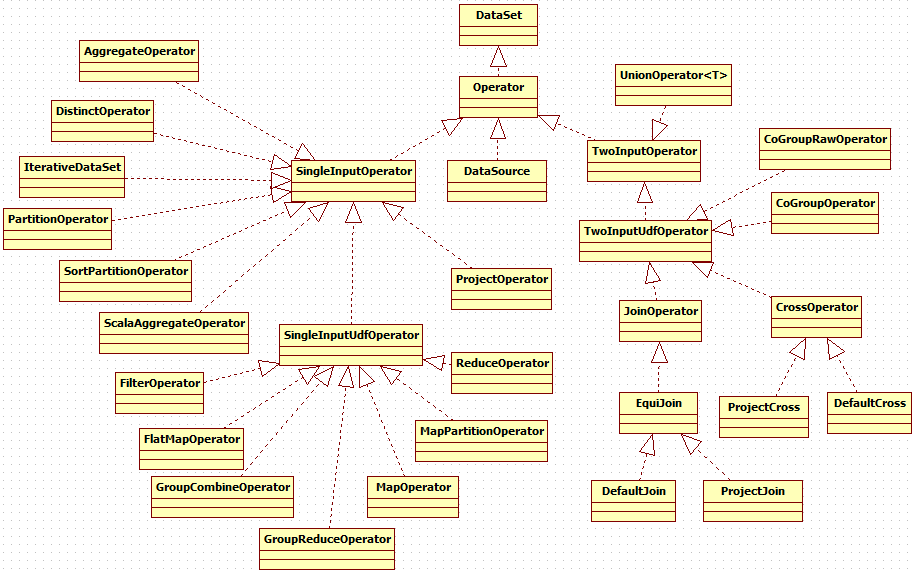
function的实现通过operator来做的,以map为例
/** * Applies a Map transformation on this DataSet. * * <p>The transformation calls a {@link org.apache.flink.api.common.functions.MapFunction} for each element of the DataSet. * Each MapFunction call returns exactly one element. * * @param mapper The MapFunction that is called for each element of the DataSet. * @return A MapOperator that represents the transformed DataSet. * * @see org.apache.flink.api.common.functions.MapFunction * @see org.apache.flink.api.common.functions.RichMapFunction * @see MapOperator */ public <R> MapOperator<T, R> map(MapFunction<T, R> mapper) { if (mapper == null) { throw new NullPointerException("Map function must not be null."); } String callLocation = Utils.getCallLocationName(); TypeInformation<R> resultType = TypeExtractor.getMapReturnTypes(mapper, getType(), callLocation, true); return new MapOperator<>(this, resultType, clean(mapper), callLocation); }
其中,Operator
4.数据输出
DataSink:一个用来存储数据结果的操作。
输出OutputFormat
例如,可以csv输出
/** * Writes a {@link Tuple} DataSet as CSV file(s) to the specified location with the specified field and line delimiters. * * <p><b>Note: Only a Tuple DataSet can written as a CSV file.</b> * For each Tuple field the result of {@link Object#toString()} is written. * * @param filePath The path pointing to the location the CSV file is written to. * @param rowDelimiter The row delimiter to separate Tuples. * @param fieldDelimiter The field delimiter to separate Tuple fields. * @param writeMode The behavior regarding existing files. Options are NO_OVERWRITE and OVERWRITE. * * @see Tuple * @see CsvOutputFormat * @see DataSet#writeAsText(String) Output files and directories */ public DataSink<T> writeAsCsv(String filePath, String rowDelimiter, String fieldDelimiter, WriteMode writeMode) { return internalWriteAsCsv(new Path(filePath), rowDelimiter, fieldDelimiter, writeMode); } @SuppressWarnings("unchecked") private <X extends Tuple> DataSink<T> internalWriteAsCsv(Path filePath, String rowDelimiter, String fieldDelimiter, WriteMode wm) { Preconditions.checkArgument(getType().isTupleType(), "The writeAsCsv() method can only be used on data sets of tuples."); CsvOutputFormat<X> of = new CsvOutputFormat<>(filePath, rowDelimiter, fieldDelimiter); if (wm != null) { of.setWriteMode(wm); } return output((OutputFormat<T>) of); }
5.总结
1. flink通过InputFormat对各种数据源的数据进行读取转换成DataSet数据集
2. flink提供了丰富的转换操作,DataSet可以通过transformation转换成其它的DataSet,内部的实现是Function和Operator。
3. flink通过OutFormat将DataSet转换成DataSink,最终将数据写入到不同的存储介质。
参考资料:

微信公众号: 架构师日常笔记 欢迎关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号