1. 在跟踪源代码的时候,要追着源代码打断点,不然不知道每一步执行到那里。
有时候有的方法被多个地方调用,这时无法确认走哪个方法,改怎么办呢?
可以提前通过打调用栈的方式把整个流程弄通,然后在关键点打断点,这样效率更高。
2.打印方法的调用链(堆栈)两种方式:
正常方式
@Override public SimWeight computeWeight(float boost, CollectionStatistics collectionStats, TermStatistics... termStats) { /* Exception e=new Exception(); e.printStackTrace();*/ java.util.Map<Thread, StackTraceElement[]> ts = Thread.getAllStackTraces(); StackTraceElement[] ste = ts.get(Thread.currentThread()); for (StackTraceElement s : ste) { System.out.println("###################################"+s.getClassName()+"$"+s.getMethodName()); } //业务逻辑 return new DavidStats(field,K_length,KE_length, termStats) ; }
打印结果
###################################java.lang.Thread$dumpThreads ###################################java.lang.Thread$getAllStackTraces ###################################org.apache.lucene.search.similarities.DavidSimilarity$computeWeight ###################################org.apache.lucene.search.SynonymQuery$SynonymWeight$<init> ###################################org.apache.lucene.search.SynonymQuery$createWeight ###################################org.apache.lucene.search.IndexSearcher$createWeight ###################################org.apache.lucene.search.IndexSearcher$createNormalizedWeight ###################################org.apache.lucene.search.IndexSearcher$search ###################################org.apache.solr.search.SolrIndexSearcher$buildAndRunCollectorChain ###################################org.apache.solr.search.SolrIndexSearcher$getDocListNC ###################################org.apache.solr.search.SolrIndexSearcher$getDocListC ###################################org.apache.solr.search.SolrIndexSearcher$search ###################################org.apache.solr.handler.component.QueryComponent$doProcessUngroupedSearch ###################################org.apache.solr.handler.component.QueryComponent$process ###################################org.apache.solr.handler.component.SearchHandler$handleRequestBody ###################################org.apache.solr.handler.RequestHandlerBase$handleRequest ###################################org.apache.solr.core.SolrCore$execute ###################################org.apache.solr.servlet.HttpSolrCall$execute ###################################org.apache.solr.servlet.HttpSolrCall$call ###################################org.apache.solr.servlet.SolrDispatchFilter$doFilter ###################################org.apache.solr.servlet.SolrDispatchFilter$doFilter ###################################org.eclipse.jetty.servlet.ServletHandler$CachedChain$doFilter ###################################org.eclipse.jetty.servlet.ServletHandler$doHandle ###################################org.eclipse.jetty.server.handler.ScopedHandler$handle ###################################org.eclipse.jetty.security.SecurityHandler$handle ###################################org.eclipse.jetty.server.session.SessionHandler$doHandle ###################################org.eclipse.jetty.server.handler.ContextHandler$doHandle ###################################org.eclipse.jetty.servlet.ServletHandler$doScope ###################################org.eclipse.jetty.server.session.SessionHandler$doScope ###################################org.eclipse.jetty.server.handler.ContextHandler$doScope ###################################org.eclipse.jetty.server.handler.ScopedHandler$handle ###################################org.eclipse.jetty.server.handler.HandlerWrapper$handle ###################################org.eclipse.jetty.server.Server$handle ###################################org.eclipse.jetty.server.HttpChannel$handle ###################################org.eclipse.jetty.server.HttpConnection$onFillable ###################################org.eclipse.jetty.io.AbstractConnection$ReadCallback$succeeded ###################################org.eclipse.jetty.io.FillInterest$fillable ###################################org.eclipse.jetty.io.SelectChannelEndPoint$2$run ###################################org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume$executeProduceConsume ###################################org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume$produceConsume ###################################org.eclipse.jetty.util.thread.strategy.ExecuteProduceConsume$run ###################################org.eclipse.jetty.util.thread.QueuedThreadPool$runJob ###################################org.eclipse.jetty.util.thread.QueuedThreadPool$2$run ###################################java.lang.Thread$run
异常方式
Exception e=new Exception(); e.printStackTrace();
举例:
@Override public SimWeight computeWeight(float boost, CollectionStatistics collectionStats, TermStatistics... termStats) { Exception e=new Exception(); e.printStackTrace(); /* java.util.Map<Thread, StackTraceElement[]> ts = Thread.getAllStackTraces(); StackTraceElement[] ste = ts.get(Thread.currentThread()); for (StackTraceElement s : ste) { System.out.println("###################################"+s.getClassName()+"$"+s.getMethodName()); } */ //业务逻辑 return new DavidStats(field,K_length,KE_length, termStats) ; }
打印情况
java.lang.Exception at org.apache.lucene.search.similarities.DavidSimilarity.computeWeight(DavidSimilarity.java:91) at org.apache.lucene.search.TermQuery$TermWeight.<init>(TermQuery.java:75) at org.apache.lucene.search.TermQuery.createWeight(TermQuery.java:205) at org.apache.lucene.search.IndexSearcher.createWeight(IndexSearcher.java:738) at org.apache.lucene.search.BooleanWeight.<init>(BooleanWeight.java:56) at org.apache.lucene.search.BooleanQuery.createWeight(BooleanQuery.java:208) at org.apache.lucene.search.IndexSearcher.createWeight(IndexSearcher.java:738) at org.apache.lucene.search.IndexSearcher.createNormalizedWeight(IndexSearcher.java:727) at org.apache.lucene.search.IndexSearcher.search(IndexSearcher.java:462) at org.apache.solr.search.SolrIndexSearcher.buildAndRunCollectorChain(SolrIndexSearcher.java:215) at org.apache.solr.search.SolrIndexSearcher.getDocListNC(SolrIndexSearcher.java:1602) at org.apache.solr.search.SolrIndexSearcher.getDocListC(SolrIndexSearcher.java:1417) at org.apache.solr.search.SolrIndexSearcher.search(SolrIndexSearcher.java:584) at org.apache.solr.handler.component.QueryComponent.doProcessUngroupedSearch(QueryComponent.java:1435) at org.apache.solr.handler.component.QueryComponent.process(QueryComponent.java:375) at org.apache.solr.handler.component.SearchHandler.handleRequestBody(SearchHandler.java:295) at org.apache.solr.handler.RequestHandlerBase.handleRequest(RequestHandlerBase.java:177) at org.apache.solr.core.SolrCore.execute(SolrCore.java:2503) at org.apache.solr.core.QuerySenderListener.newSearcher(QuerySenderListener.java:74) at org.apache.solr.core.SolrCore.lambda$17(SolrCore.java:2275) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at org.apache.solr.common.util.ExecutorUtil$MDCAwareThreadPoolExecutor.lambda$0(ExecutorUtil.java:188) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745)
3.通过时序图将上面的调用链路画出来(示例,非严格按照上面的逻辑)
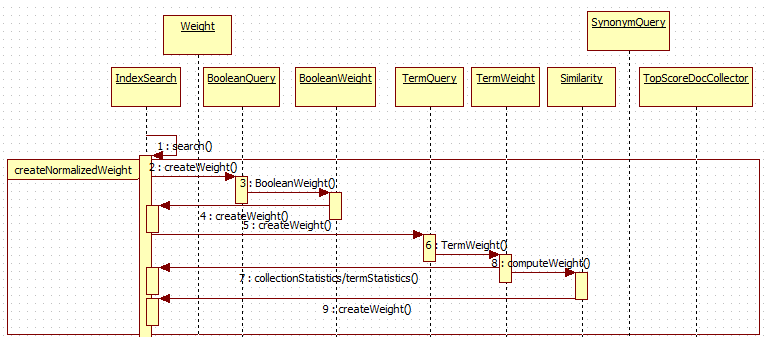
总结:
阅读源码总体上是一个长期的过程,每次阅读想要有所收获,就需要留下一些东西,比如有人写博客,有人记日志等等,如果不做任何准备,盲目的去阅读代码,往往今天读明天忘,浪费了大量的时间反而没有相应的收获。
通过梳理调用链的方式可以加深对源码的理解,通过流程图的梳理,让下次源码阅读更有效率,有图有真相。

微信公众号: 架构师日常笔记 欢迎关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号