
https://blog.csdn.net/johnson_moon/article/details/78457543
HtmlUnit简介
- 官网介绍
HtmlUnit is a "GUI-Less browser for Java programs". It models HTML documents and provides an API that allows you to invoke pages, fill out forms, click links, etc... just like you do in your "normal" browser.
It has fairly good JavaScript support (which is constantly improving) and is able to work even with quite complex AJAX libraries, simulating Chrome, Firefox or Internet Explorer depending on the configuration used.
It is typically used for testing purposes or to retrieve information from web sites.
HtmlUnit is not a generic unit testing framework. It is specifically a way to simulate a browser for testing purposes and is intended to be used within another testing framework such as JUnit or TestNG. Refer to the document "Getting Started with HtmlUnit" for an introduction.
HtmlUnit is used as the underlying "browser" by different Open Source tools like Canoo WebTest, JWebUnit, WebDriver, JSFUnit, WETATOR, Celerity, Spring MVC Test HtmlUnit, ...
HtmlUnit was originally written by Mike Bowler of Gargoyle Software and is released under the Apache 2 license. Since then, it has received many contributions from other developers, and would not be where it is today without their assistance.- 中文翻译
HtmlUnit是一个无界面浏览器Java程序。它为HTML文档建模,提供了调用页面、填写表单、单击链接等操作的API。就跟你在浏览器里做的操作一样。
HtmlUnit不错的JavaScript支持(不断改进),甚至可以使用相当复杂的AJAX库,根据配置的不同模拟Chrome、Firefox或Internet Explorer等浏览器。
HtmlUnit通常用于测试或从web站点检索信息。HtmlUnit使用场景
- httpClient的局限性
对于使用java实现的网页爬虫程序,我们一般可以使用apache的HttpClient组件进行HTML页面信息的获取,HttpClient实现的http请求返回的响应一般是纯文本的document页面,即最原始的html页面。
对于一个静态的html页面来说,使用httpClient足够将我们所需要的信息爬取出来了。但是对于现在越来越多的动态网页来说,更多的数据是通过异步JS代码获取并渲染到的,最开始的html页面是不包含这部分数据的。
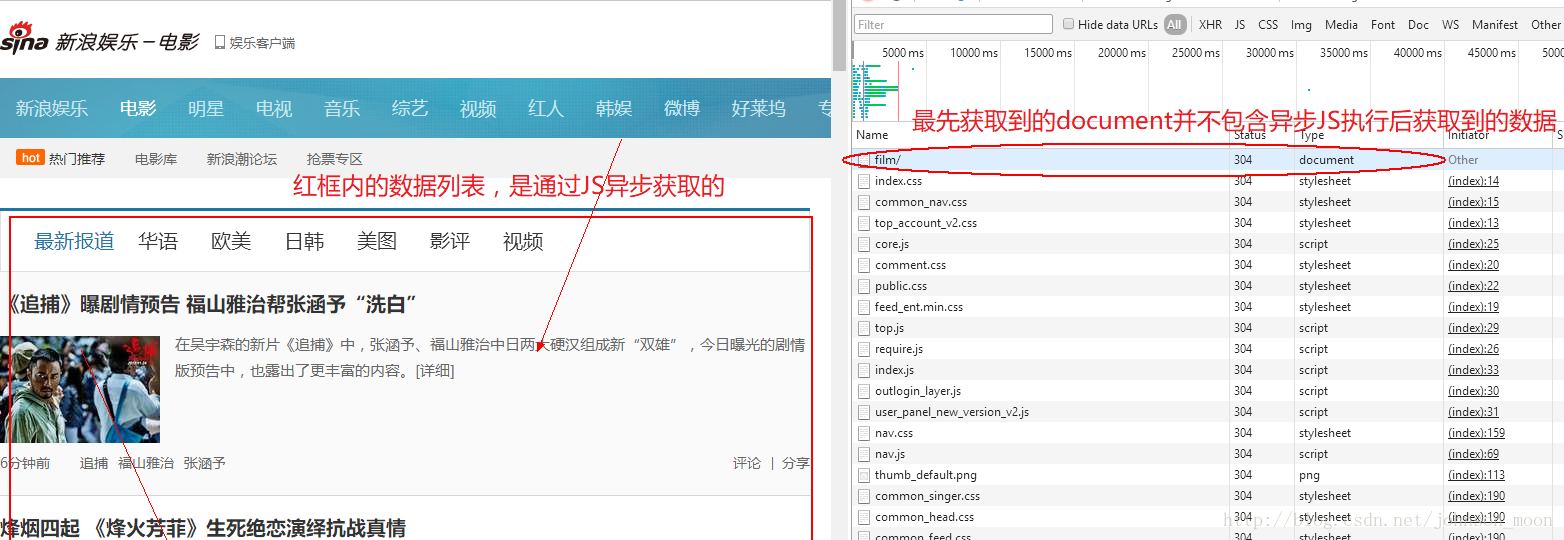
上图我们所见到的网页,在最初的document加载完成之后,并不会看到红框中的数据列表。浏览器通过执行异步JS请求,将获取到的动态数据,渲染到最初的document页面中,才最终变成了我们看到的网页。而对于这部分需要执行JS代码获取的数据,httpClient就显得无能为力了。虽然我们可以通过研究拿到JS执行的请求路径再用java代码获取我们需要的这部分数据,且不说我们能不能够从JS脚本中分析到这个请求路径和请求参数,光是分析这部分源码的代价就已经很高了。
- HtmlUnit来解决
通过上面的介绍,我们了解了现在很大一部分动态网页,展现的数据都是通过异步JS请求获取,然后再通过JS对页面进行渲染得到的。那我们是不是可以进行这么一个假设,假设我们的爬虫程序模拟了一个浏览器,在获取html页面之后,像浏览器一样执行异步JS代码,等到JS将html页面渲染完成之后,就可以愉快的获取页面上的节点信息了。那么有没有这样的java程序呢?
答案是有的。
HtmlUnit就是这么一个程序库,用来做出了界面展示意外所有的异步工作。由于没有了展示这一块耗时的工作,HtmlUnit加载完成一个完整的网页要比实际的浏览器块多了。并且根据不同配置,HtmlUnit可以模拟市面上常用的浏览器如Chrome、Firefox、IE浏览器等。
通过HtmlUnit库,加载一个完整的Html页面(图片视频除外),然后就可以将其转换成我们常用的字串格式,用其他工具如Jsoup来获取其中的元素了。当然也可以直接在HtmlUnit提供的对象中获取网页元素,甚至是操作如按钮、表单等控件。除了不能像可见浏览器一样用鼠标键盘浏览网页之外,我们可以用HtmlUnit来模拟操作其他的一切操作,像登录网站,撰写博客等等都是可以完成的。当然网页内容爬取是最简单的一个应用了。
HtmlUnit使用方法
1.新建maven工程,添加HtmlUnit依赖:
<dependencies>
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.27</version>
</dependency>
</dependencies>- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.新建一个Junit TestCase来尝试一下程序库的使用
程序代码注释如下:
package xuyihao.util.depend;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.junit.Test;
import java.util.List;
/**
* Created by xuyh at 2017/11/6 14:03.
*/
public class HtmlUtilTest {
@Test
public void test() {
final WebClient webClient = new WebClient(BrowserVersion.CHROME);//新建一个模拟谷歌Chrome浏览器的浏览器客户端对象
webClient.getOptions().setThrowExceptionOnScriptError(false);//当JS执行出错的时候是否抛出异常, 这里选择不需要
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//当HTTP的状态非200时是否抛出异常, 这里选择不需要
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);//是否启用CSS, 因为不需要展现页面, 所以不需要启用
webClient.getOptions().setJavaScriptEnabled(true); //很重要,启用JS
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//很重要,设置支持AJAX
HtmlPage page = null;
try {
page = webClient.getPage("http://ent.sina.com.cn/film/");//尝试加载上面图片例子给出的网页
} catch (Exception e) {
e.printStackTrace();
}finally {
webClient.close();
}
webClient.waitForBackgroundJavaScript(30000);//异步JS执行需要耗时,所以这里线程要阻塞30秒,等待异步JS执行结束
String pageXml = page.asXml();//直接将加载完成的页面转换成xml格式的字符串
//TODO 下面的代码就是对字符串的操作了,常规的爬虫操作,用到了比较好用的Jsoup库
Document document = Jsoup.parse(pageXml);//获取html文档
List<Element> infoListEle = document.getElementById("feedCardContent").getElementsByAttributeValue("class", "feed-card-item");//获取元素节点等
infoListEle.forEach(element -> {
System.out.println(element.getElementsByTag("h2").first().getElementsByTag("a").text());
System.out.println(element.getElementsByTag("h2").first().getElementsByTag("a").attr("href"));
});
}
}上面的例子将获取到的页面中消息列表的标题和超链接URL打印到控制台,操作HTML文档的库是Jsoup,需要添加依赖:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.8.3</version>
</dependency>- 1
- 2
- 3
- 4
- 5
经过三十秒的等待,控制台输出的结果是这样的:
十一月 06, 2017 2:17:05 下午 com.gargoylesoftware.htmlunit.IncorrectnessListenerImpl notify
警告: Obsolete content type encountered: 'application/x-javascript'.
十一月 06, 2017 2:17:06 下午 com.gargoylesoftware.htmlunit.javascript.StrictErrorReporter runtimeError
严重: runtimeError: message=[An invalid or illegal selector was specified (selector: '*,:x' error: Invalid selector: :x).] sourceName=[http://n.sinaimg.cn/lib/core/core.js] line=[1] lineSource=[null] lineOffset=[0]
十一月 06, 2017 2:17:06 下午 com.gargoylesoftware.htmlunit.IncorrectnessListenerImpl notify
警告: Obsolete content type encountered: 'application/x-javascript'.
2017-11-06 14:17:11.003:INFO::JS executor for com.gargoylesoftware.htmlunit.WebClient@618c5d94: Logging initialized @7179ms to org.eclipse.jetty.util.log.StdErrLog
十一月 06, 2017 2:17:11 下午 com.gargoylesoftware.htmlunit.javascript.host.WebSocket run
严重: WS connect error
java.util.concurrent.ExecutionException: org.eclipse.jetty.websocket.api.UpgradeException: 0 null
at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1895)
at com.gargoylesoftware.htmlunit.javascript.host.WebSocket$1.run(WebSocket.java:151)
at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:672)
at org.eclipse.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:590)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.eclipse.jetty.websocket.api.UpgradeException: 0 null
at org.eclipse.jetty.websocket.client.WebSocketUpgradeRequest.onComplete(WebSocketUpgradeRequest.java:513)
at org.eclipse.jetty.client.ResponseNotifier.notifyComplete(ResponseNotifier.java:193)
at org.eclipse.jetty.client.ResponseNotifier.notifyComplete(ResponseNotifier.java:185)
at org.eclipse.jetty.client.HttpExchange.notifyFailureComplete(HttpExchange.java:269)
at org.eclipse.jetty.client.HttpExchange.abort(HttpExchange.java:240)
at org.eclipse.jetty.client.HttpConversation.abort(HttpConversation.java:141)
at org.eclipse.jetty.client.HttpRequest.abort(HttpRequest.java:748)
at org.eclipse.jetty.client.HttpDestination.abort(HttpDestination.java:444)
at org.eclipse.jetty.client.HttpDestination.failed(HttpDestination.java:224)
at org.eclipse.jetty.client.AbstractConnectionPool$1.failed(AbstractConnectionPool.java:122)
at org.eclipse.jetty.util.Promise$Wrapper.failed(Promise.java:136)
at org.eclipse.jetty.client.HttpClient$1$1.failed(HttpClient.java:588)
at org.eclipse.jetty.client.AbstractHttpClientTransport.connectFailed(AbstractHttpClientTransport.java:154)
at org.eclipse.jetty.client.AbstractHttpClientTransport$ClientSelectorManager.connectionFailed(AbstractHttpClientTransport.java:199)
at org.eclipse.jetty.io.ManagedSelector$Connect.failed(ManagedSelector.java:655)
at org.eclipse.jetty.io.ManagedSelector$Connect.access$1300(ManagedSelector.java:622)
at org.eclipse.jetty.io.ManagedSelector$1.failed(ManagedSelector.java:364)
at org.eclipse.jetty.io.ManagedSelector$CreateEndPoint.run(ManagedSelector.java:604)
... 3 more
Caused by: java.lang.NullPointerException
at org.eclipse.jetty.io.ssl.SslClientConnectionFactory.newConnection(SslClientConnectionFactory.java:59)
at org.eclipse.jetty.client.AbstractHttpClientTransport$ClientSelectorManager.newConnection(AbstractHttpClientTransport.java:191)
at org.eclipse.jetty.io.ManagedSelector.createEndPoint(ManagedSelector.java:420)
at org.eclipse.jetty.io.ManagedSelector.access$1600(ManagedSelector.java:61)
at org.eclipse.jetty.io.ManagedSelector$CreateEndPoint.run(ManagedSelector.java:599)
... 3 more
十一月 06, 2017 2:17:16 下午 com.gargoylesoftware.htmlunit.IncorrectnessListenerImpl notify
警告: Obsolete content type encountered: 'application/x-javascript'.
十一月 06, 2017 2:17:21 下午 com.gargoylesoftware.htmlunit.IncorrectnessListenerImpl notify
警告: Obsolete content type encountered: 'text/javascript'.
十一月 06, 2017 2:17:21 下午 com.gargoylesoftware.htmlunit.IncorrectnessListenerImpl notify
警告: Obsolete content type encountered: 'text/javascript'.
时隔17年重温《EUREKA》 宫崎葵:这次哭得很凶
http://ent.sina.com.cn/m/f/2017-11-06/doc-ifynmzrs7411439.shtml
模式单一成审美疲劳 超级英雄电影该如何突围?
http://ent.sina.com.cn/m/f/2017-11-06/doc-ifynmnae2196060.shtml
组图:《天生不对》首映 薛凯琪不规则红裙优雅可人 13
http://slide.ent.sina.com.cn/film/slide_4_704_247725.html
电影资料馆达成线上售票合作 影迷不必排队买票
http://ent.sina.com.cn/m/c/2017-11-06/doc-ifynmvuq8917282.shtml
组图:詹妮弗加纳去教堂路遇好友 白裙清新心情靓 4
http://slide.ent.sina.com.cn/film/h/slide_4_704_247702.html
《东方快车》发幕后特辑 唯美复古凸显品质
http://ent.sina.com.cn/m/f/2017-11-06/doc-ifynnnsc7188105.shtml
组图:梅根福克斯穿紧身衣身材火辣 踩拖鞋抱瑜伽垫 4
http://slide.ent.sina.com.cn/film/slide_4_704_247699.html忽略HtmlUnit执行时候的报错信息,可以看到最后还是成功的将结果打印了出来了。
3.编写工具类
尝试了一下HtmlUnit加载网页并解析之后,我们可以编写一个工具类为之后的爬虫程序的使用铺路了,代码如下:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
/**
* <pre>
* Http工具,包含:
* 高级http工具(使用net.sourceforge.htmlunit获取完整的html页面,即完成后台js代码的运行)
* </pre>
* Created by xuyh at 2017/7/17 19:08.
*/
public class HttpUtils {
/**
* 请求超时时间,默认20000ms
*/
private int timeout = 20000;
/**
* 等待异步JS执行时间,默认20000ms
*/
private int waitForBackgroundJavaScript = 20000;
private static HttpUtils httpUtils;
private HttpUtils() {
}
/**
* 获取实例
*
* @return
*/
public static HttpUtils getInstance() {
if (httpUtils == null)
httpUtils = new HttpUtils();
return httpUtils;
}
public int getTimeout() {
return timeout;
}
/**
* 设置请求超时时间
*
* @param timeout
*/
public void setTimeout(int timeout) {
this.timeout = timeout;
}
public int getWaitForBackgroundJavaScript() {
return waitForBackgroundJavaScript;
}
/**
* 设置获取完整HTML页面时等待异步JS执行的时间
*
* @param waitForBackgroundJavaScript
*/
public void setWaitForBackgroundJavaScript(int waitForBackgroundJavaScript) {
this.waitForBackgroundJavaScript = waitForBackgroundJavaScript;
}
/**
* 将网页返回为解析后的文档格式
*
* @param html
* @return
* @throws Exception
*/
public static Document parseHtmlToDoc(String html) throws Exception {
return removeHtmlSpace(html);
}
private static Document removeHtmlSpace(String str) {
Document doc = Jsoup.parse(str);
String result = doc.html().replace(" ", "");
return Jsoup.parse(result);
}
/**
* 获取页面文档字串(等待异步JS执行)
*
* @param url 页面URL
* @return
* @throws Exception
*/
public String getHtmlPageResponse(String url) throws Exception {
String result = "";
final WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setThrowExceptionOnScriptError(false);//当JS执行出错的时候是否抛出异常
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//当HTTP的状态非200时是否抛出异常
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);//是否启用CSS
webClient.getOptions().setJavaScriptEnabled(true); //很重要,启用JS
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//很重要,设置支持AJAX
webClient.getOptions().setTimeout(timeout);//设置“浏览器”的请求超时时间
webClient.setJavaScriptTimeout(timeout);//设置JS执行的超时时间
HtmlPage page;
try {
page = webClient.getPage(url);
} catch (Exception e) {
webClient.close();
throw e;
}
webClient.waitForBackgroundJavaScript(waitForBackgroundJavaScript);//该方法阻塞线程
result = page.asXml();
webClient.close();
return result;
}
/**
* 获取页面文档Document对象(等待异步JS执行)
*
* @param url 页面URL
* @return
* @throws Exception
*/
public Document getHtmlPageResponseAsDocument(String url) throws Exception {
return parseHtmlToDoc(getHtmlPageResponse(url));
}
}可以通过这样的方式调用本工具:
import org.jsoup.nodes.Document;
import org.junit.Test;
public class HttpUtilsTest {
private static final String TEST_URL = "http://www.google.com/";
@Test
public void testGetHtmlPageResponse() {
HttpUtils httpUtils = HttpUtils.getInstance();
httpUtils.setTimeout(30000);
httpUtils.setWaitForBackgroundJavaScript(30000);
try {
String htmlPageStr = httpUtils.getHtmlPageResponse(TEST_URL);
//TODO
System.out.println(htmlPageStr);
} catch (Exception e) {
e.printStackTrace();
}
}
@Test
public void testGetHtmlPageResponseAsDocument() {
HttpUtils httpUtils = HttpUtils.getInstance();
httpUtils.setTimeout(30000);
httpUtils.setWaitForBackgroundJavaScript(30000);
try {
Document document = httpUtils.getHtmlPageResponseAsDocument(TEST_URL);
//TODO
System.out.println(document);
} catch (Exception e) {
e.printStackTrace();
}
}
}源码地址
https://github.com/johnsonmoon/HttpUtils.git
微信公众号: 架构师日常笔记 欢迎关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号