
如何用minist神经网络识别自己写在纸上的数字
前言
这里分两个程序来完成,第一个程序训练并且保存字体识别模型;第二个程序是输入自己的手写数字在纸上的照片并处理然后识别。minist跟tensorflow官网的介绍大同小易,这里只简要介绍。
背景
神经网络是一种仿生的结果,通过模仿神经元对人类的储存记忆的作用,演化成为利用样本训练模型,并用模型预测新的样本。
模型训练和保存
minst.py,完整可视化代码可以在这里下载。
from __future__ import absolute_import, division, print_function, unicode_literals
# 用matplotlib可以画图
import matplotlib.pyplot as plt
import numpy as np
# from tensorflow.examples.tutorials.mnist import input_data
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# old_v = tf.logging.get_verbosity()
# tf.logging.set_verbosity(tf.logging.ERROR)
print(tf.__version__)# tensorflow版本
# 显示函数
# 直接下载mnist如果没有的话
mnist = keras.datasets.mnist
(train_data, train_labels), (eval_data, eval_labels) = mnist.load_data()
# load_data函数有问题
# tf.logging.set_verbosity(old_v)
class_names = ['zero', 'one', 'two', 'three', 'four', 'five',
'six', 'seven', 'eight', 'night']
# train_data.shape
train_data = train_data / 255.0
eval_data = eval_data / 255.0
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
# reformates data
keras.layers.Dense(128, activation='relu'),
# 128个神经元
keras.layers.Dense(10, activation='softmax')
# 10个神经元
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 更新方式
# 准确率
model.fit(train_data, train_labels, epochs=10)
# 训练
test_loss, test_acc = model.evaluate(eval_data, eval_labels, verbose=2)
# 测试
print('\nTest accuracy:', test_acc)
model.save('mnistnum.h5')
读取并识别自己的手写数字
这里主要讲如何对图片进行尺寸和维度的调整以适应模型的输入样本的格式。
首先要重设图片的大小,我们模型输入样本的大小包含纬度的话,实际上是(1,28,28),现在先重设图片规格为(28,28)
new_image = cv2.resize(dilate_img,(28,28),cv2.INTER_CUBIC)
print(new_image.shape)
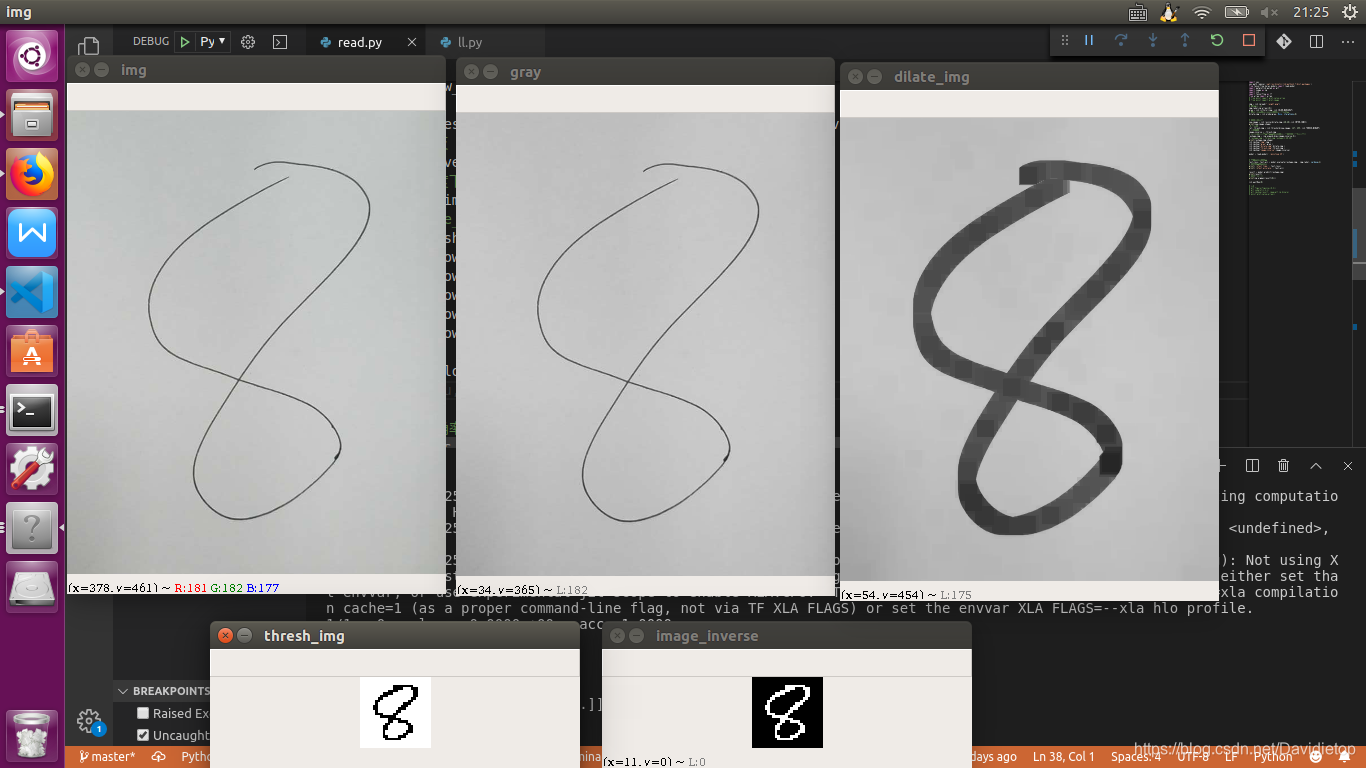
二值化后取反,二值化是为了等下取反,二值化是将图片完全转换成为黑白图片,亮的部分为白色。但是输入的样本数字应该是黑底白字的,你不可能用白色的笔在黑色纸上写字把(一般是白底黑字),所以对二值化后的图像取反即可得到想要的黑底白字的图像效果。
ret, thresh_img = cv2.threshold(new_image, 127, 255, cv2.THRESH_BINARY)
image_inverse = ~thresh_img
最后是图像的增维,这里更多来讲是图像的类型,一般来讲,灰度图使用二维(矩阵)来表示的,然后彩色图包含了比如R、G、B三个元素,所以用三维矩阵表示。这里最终处理成为了(1,28,28),应该是出于更加便于数据处理角度考虑的。
reshape_img = (np.expand_dims(image_inverse,0))
每个过程的效果图:
read.py完整代码:
from tensorflow.keras.models import load_model
import matplotlib.pylab as plt
import numpy as np
import cv2
import tensorflow as tf
from array import array
img = cv2.imread("./eight.png")
# 给img打标签
img_label=np.array([8])
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 联通黑色区域或去除白色噪点(黑笔白底)
dilate_img = cv2.erode(img, None, iterations=8)
# 重设图片大小
new_image = cv2.resize(dilate_img,(28,28),cv2.INTER_CUBIC)
print(new_image.shape)
# 二值化
ret, thresh_img = cv2.threshold(new_image, 127, 255, cv2.THRESH_BINARY)
# 图像取反
image_inverse = ~thresh_img
# 增加维度
reshape_img = (np.expand_dims(image_inverse,0))
print(reshape_img.shape)
model = load_model('./mnistnum.h5')
# 获取正确率和时间
test_loss, test_acc = model.evaluate(reshape_img, img_label, verbose=2)
# 输出时间和正确率
print('\nTest time:', test_loss)
print('\nTest accuracy:', test_acc)
result = model.predict(reshape_img)
print(result)
# 输出预测数字
print(np.argmax(result[0]))


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)