Amazon DynamoDB 概览
1. 什么是Amazon DynamoDB
DynamoDB 是一种快速、全面受管的 NoSQL 数据库服务,它能让用户以简单并且经济有效地方式存储和检索任何数据量,同时服务于任何程度的请求流量。所有的数据项都存储在固态驱动器 (SSD) 中,同时在 3 个可用区域间进行复制,确保达到较高的可用性和持久性。
通过 DynamoDB,您可以卸下由于运行和扩展高可用性的分布式集群而带来的管理负担,而且只需以较低的价格为您使用的部分付费。
服务亮点
可扩展 – Amazon DynamoDB 旨在实现吞吐量和存储容量高效无缝扩展。
- 配置吞吐量 – 创建表时,只需指定所需的请求容量即可。DynamoDB 会为您的表分配专用资源以满足性能要求,并自动将数据分区到足够多的服务器以满足请求容量。如果您的应用吞吐量需求发生变化,只需使用 AWS 管理控制台或 Amazon DynamoDB API 调用更新表的请求容量即可。在扩展过程,仍然能够保证之前的吞吐量水平没有下降。
- 自动存储扩展 – 您在 DynamoDB 表中可存储数据量没有限制,而且随着您使用 DynamoDB 写入 API 存储数据量加大,该服务会自动分配更多存储。
- 完全分布式的无共享架构 – Amazon DynamoDB 可水平扩展并在数百台服务器中无缝扩展单个表。
快速、可预测的性能 – Amazon DynamoDB 的服务端平均延迟通常不超过十毫秒。该服务在固态硬盘中运行,其构建方式旨在任何规模均能保证服务性能持续优良,降低延迟。
轻松管理 – Amazon DynamoDB 是完全托管的服务,您只需创建数据库表,其余事情都交由该服务来代劳。您无需担心硬件或软件配置、创建设置和配置、软件更新、操作可靠的分布式数据库集群,或者随着扩展需要在多个实例间对数据进行分区等问题,您只需尽享 Amazon DynamoDB 服务之大成。
内置容错能力 – Amazon DynamoDB 内置容错能力,可在某个地区三个可用区域之间自动同步备份数据,以实现高效可访问性,即使单台机器甚至设施出现死机,防护措施保证数据万无一失。
灵活 – Amazon DynamoDB 没有固定模式。相反,每个数据项目可能有不同数量的属性。多种数据类型(字符串、数字、二进制数据和集)使数据模型更加丰富。
强一致性、原子计数器 – 与许多非关系数据库不同,Amazon DynamoDB 允许您对读取操作使用强一致性检验以确保始终读取最新的值,从而使开发更加便捷。Amazon DynamoDB 支持多种本地数据类型(数字、字符串、二进制数据和多值属性)。该服务还支持本地原子计数器,允许您通过调用单个 API 调用自动递增或递减数值属性。
经济高效 – Amazon DynamoDB 能轻松应对任何规模的工作负载强度,费用低廉,经济高效。您也可以开始使用免费套餐,允许您每月执行 4 000 万次数据库操作,并且在超出该限制后只需为使用的资源支付少许小时费率。凭借便捷管理和高效请求定价,相较于亲力而为管理关系或非关系数据库,DynamoDB 工作负载总拥有成本 (TCO)大大降低。
安全 – Amazon DynamoDB 采用经过验证的加密方法验证用户身份,以防未授权数据访问。此外,它还能与 AWS Identity and Access Management (IAM) 集成,对组织内的用户实现精细的访问控制。
集成监控 – Amazon DynamoDB 在 AWS 管理控制台中为您的表显示关键操作指标。该服务还能与 Amazon CloudWatch 结合使用,以便您查看每个 Amazon DynamoDB 表的请求吞吐量和延迟,并轻松跟踪您的资源开销。
Elastic MapReduce 集成 – Amazon DynamoDB 与 Amazon Elastic MapReduce (Amazon EMR) 无缝集成。Amazon EMR 允许企业在 AWS 上使用托管的即用即付计费 Hadoop 框架对大型数据集执行复杂分析。依赖 Amazon DynamoDB 强大服务能力,客户可轻松使用 Amazon EMR 来分析 DynamoDB 中存储的数据集并在 Amazon Simple Storage Service (Amazon S3) 中存档结果,同时在 DynamoDB 中保存完整原始数据集。此外,企业还可使用 Amazon EMR 访问多个存储(即 Amazon DynamoDB、Amazon RDS 和 Amazon S3)中的数据、对这一组合的数据集执行复杂分析,并在 Amazon S3 中存储工作结果。
2. 数据模型概览
Amazon DynamoDB 将数据组织到包含项目的表,每个项目有一个或多个属性。
属性
属性是一个名称-值对。名称必须是字符串,但值可以是字符串、数字、二进制数据、字符串集、数字集或二进制数据集。以下均为属性的实例:
"ImageID" = 1
"Title" = "flower"
"Tags" = "flower", "jasmine", "white"
"Ratings" = 3, 4, 2
项目
属性的集合构成项目,项目由其主键标识。项目的属性是名称-值对的集合,顺序不限。项目属性可以是稀疏型,与同一表中其他项目的属性无关,并且是可选的(主键属性除外)。与传统数据库不同,该表除依赖于主键外没有其他模式。项目存储在表中。要将项目放入表中,必须至少指定其中一个属性为主键。主键唯一标识 DynamoDB 表的某个项目。在以下图表中,ImageID 即为指定为主键的属性:
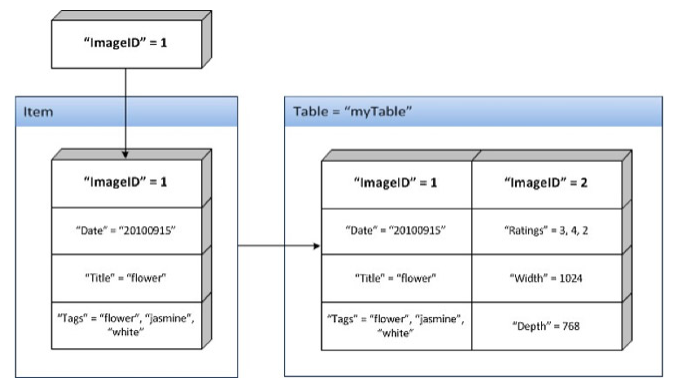
表有名称“my table”,但项目没有名称。主键定义项目;包含主键 "ImageID"=1 的项目
表
表包含项目,并将信息组织到离散区域。表中的所有项目具有相同的主键模式。在创建表时,需指定用于主键的一个或多个属性名称,并且要求表中每个项目具有唯一的主键值。要向 DynamoDB 写入数据,第一步是创建表,并使用主键指定表名称。以下是一个较大的表,它也采用 ImageID 作为标识项目的主键。
| 表:My Images | |||||||
| 主键 | 其他属性 | ||||||
| ImageID = 1 | ImageLocation = https://s3.amazonaws.com/bucket/img_1.jpg | Date = 1260653179 | Title = flower | Tags = Flower, Jasmine | Width = 1024 | Depth = 768 | |
| ImageID = 2 | ImageLocation = https://s3.amazonaws.com/bucket/img_2.jpg | Date = 1252617979 | Rated = 3, 4, 2 | Tags = Work, Seattle, Office | Width = 1024 | Depth = 768 | |
| ImageID = 3 | ImageLocation = https://s3.amazonaws.com/bucket/img_3.jpg | Date = 1285277179 | Price = 10.25 | Tags = Seattle, Grocery, Store | Author = you | Camera = phone | |
| ImageID = 4 | ImageLocation = https://s3.amazonaws.com/bucket/img_4.jpg | Date = 1282598779 | Title = Hawaii | Author = Joe | Colors = orange, blue, yellow | Tags = beach, blanket, ball | |
3. 访问模型和 API 概览
主键
DynamoDB 要求每个表具有定义好的主键用来访问数据。
主键唯一标识每个项目(如 ID =1、ID = 2、ID = 3 等)。
主键是表中唯一被索引的部分,也用来在多个服务器之间对数据进行哈希分区。您在创建表时指定主键。
换句话说,每个项目都是名称/值对的集合。在创建表的项目时,您需指定一个名称/值对作为主键。表中所有项目的主键属性必须具有值,Amazon DynamoDB 会确保该名称值的唯一性,并根据主键创建一个索引。
范围查询使用的复合主键
复合主键指定了表中的两个属性,共同构成唯一的主索引。表中的所有项目必须具有这两个属性。一个用作“哈希分区属性”,另一个用作“范围属性”。例如,您可能有一个“Status Updates”表,复合主键由“UserID”(哈希属性,用于在多台服务器间为工作负载分区)和“Time”(范围属性)构成。然后,您可以运行查询来提取:1) 由 UserID 和 Time 值组合唯一标识的特定项目;2) 特定哈希“存储段”(此例中为 UserID)的所有项目;或 3) 特定时间范围内特定 UserID 的所有项目。仅在指定了 UserID 哈希存储段的情况下,才支持针对“Time”的范围查询。
DynamoDB API
- CreateTable – 创建表并指定用于数据访问的主键。
- UpdateTable – 更新特定表的 配置吞吐量值。
- DeleteTable – 删除表。
- DescribeTable – 返回表大小、状态和索引信息。
- PutItem – 创建新项目,或将旧项目替换为新项目(包括所有属性)。如果项目已存在于具有相同主键的指定表中,则新项目将会完全替换现有项目。您还可以使用条件运算符实现条件替换,即仅在项目的属性值符合特定条件时才替换项目,或仅在项目尚未存在时才插入新项目。
- BatchWriteItem – 通过单个请求(而不是单个事务)插入、替换和删除多个表中的多个项目。支持对最多 25 个项目批量执行 Put 或 Delete 操作,最大总请求大小为 1 MB。
- UpdateItem – 编辑现有项目的属性。您还可以使用条件运算符实现条件更新,即仅在项目的属性值符合特定条件时才进行更新。
- DeleteItem – 按主键删除表中的单个项目。您还可以使用条件运算符实现条件删除,即仅在项目的属性值符合特定条件时才删除项目。
- GetItem – GetItem 运算符可为匹配主键的项目返回一组属性。默认情况下,GetItem 操作提供最终一致性读取。如果最终一致性读取不适用于您的应用程序,请使用 ConsistentRead。
- BatchGetItem – BatchGetItem 操作可为使用主键的多个表中的多个项目返回属性。单个响应的大小限制为 1 MB,最多返回 100 个项目。支持强一致性和最终一致性。
- Query – 获得一个或更多基于主键的项目。支持强一致性和最终一致性。此 API 在具有复合哈希-范围键的表中使用。
- Scan – 通过在表中执行完全扫描,获取一个或多个项目和属性。可以通过指定针对一个或多个属性的筛选条件,限制返回的项目。然后可以使用此 API,针对不是表主键的属性,启用表的即席查询。但是,由于它是没有索引的完全表扫描,因此不适用于需要可预测性能的任何应用程序查询使用案例。Scan API 请求的结果集最终将是一致的。您可将 Scan API 视为迭代器。一旦特定 Scan API 请求的扫描项目的总大小超过 1 MB 限制,则该特定请求将被终止,提取的结果将与 LastEvaluatedKey 一同返回(以便在后续操作中继续扫描)。
4. Amazon Elastic MapReduce 集成
Amazon DynamoDB 还可与 Amazon Elastic MapReduce (Amazon EMR) 集成。Amazon EMR 允许企业在 AWS 上使用托管的即用即付 Hadoop 架购对大型数据集执行复杂的分析。EMR 可采用如下所示的某些方式与 DynamoDB 结合使用:
-
客户可以使用 EMR 分析 DynamoDB 中存储的数据,将分析结果存储在 S3 中,同时在 DynamoDB 中保留原始数据。
例如,如果您使用 Amazon DynamoDB 来存储客户订单,可以每月创建一个新的订单表,而使用 EMR 的多表查询功能,您可以联接 DynamoDB 中不同的表来回答“特定客户在过去 3 个月下达了哪些订单”之类的问题。然后,可以使用 EMR 在 S3 中存储这些问题的查询结果以供将来检索,同时在 DynamoDB 中完整保留月度客户订单表中的数据。
-
客户可以使用 EMR 将数据从 DynamoDB 备份到 S3。
借用以上关于客户订单的示例,一旦您不再频繁写入数据到月度订单表,则可以将此表备份到 S3,并从 DynamoDB 中删除此表,以便享受 S3 较低存储费用。S3 中存储的数据仍然可以很方便地用于下述分析过程。
-
此外,客户还可使用 Amazon EMR 访问多个存储(即 Amazon DynamoDB、Amazon RDS 和 Amazon S3)中的数据、对这一组合的数据集执行复杂分析,并在 Amazon S3 中存储此工作的结果。
例如,如果您使用 Amazon DynamoDB 存储客户订单,则可以每月创建一个新的订单表,并在月末时使用 Amazon EMR 在 Amazon S3 中存档 6 个多月的旧订单。这使您能够在 Amazon S3 中存档不常访问的订单以降低费用,并仅在 DynamoDB 中保存经常访问的订单。您可以使用 EMR 跨越 DynamoDB 中存储的当前订单及 Amazon S3 中存储的存档订单表来执行分析,以回答“客户 Y 在过去 48 个月内对产品小组件 X 下达了多少订单”之类的查询。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号