Flink从入门到精通(一) - 简介
1. 什么是Flink?
官网的定义如下:
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
从官网的定义我们可以看出
1. 首先,它是一个分布式处理引擎和框架
2. 其次,它进行有状态的计算,针对有界和无界的数据流式计算
这里有几点我想详细解释一下:
2-1) 什么叫有界和无界数据?
有界数据集:有限不会改变的数据集合
无界数据(无穷数据集): 无穷的持续集成的数据集合
那么那些常见的无穷数据集有哪些呢?
用户与客户端的实时交互数据(用户行为)
应用实时产生的日志
金融市场的实时交易记录
2-2) 什么是流式计算?
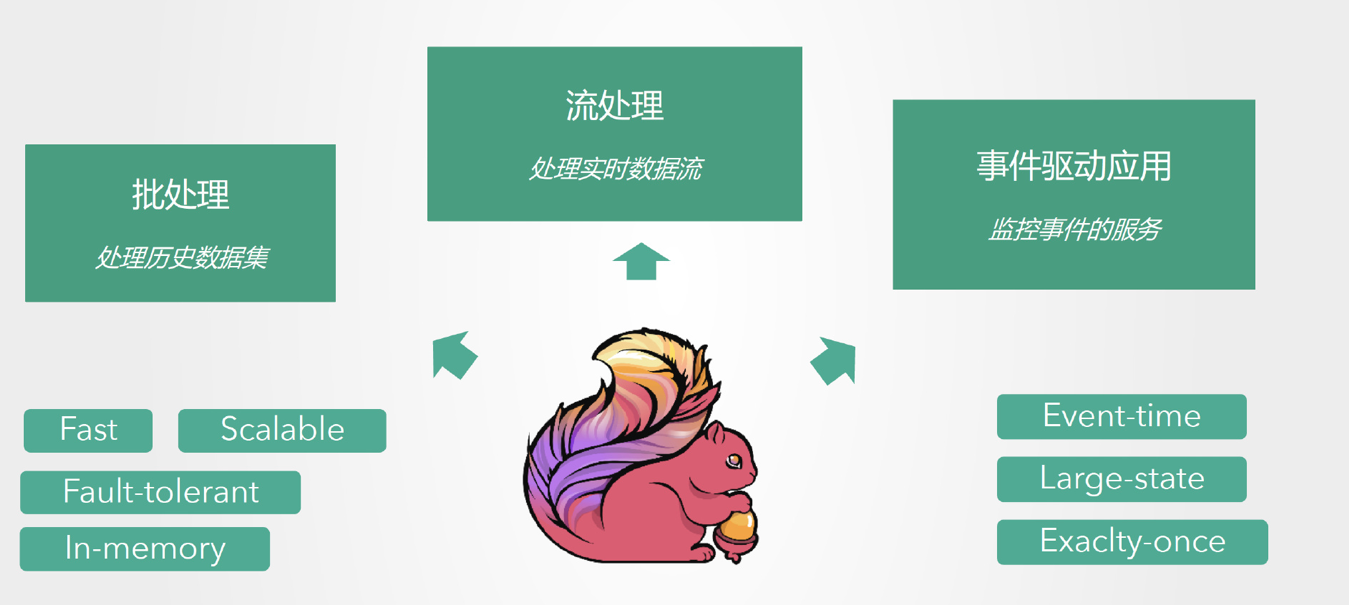
说到流式计算我们就不得不提一下批处理计算,因为它们是不同的东西。
批处理:在预先定义的时间内运行计算,当完成时释放计算机资源
流式:只要数据一直在产生,计算就持续地进行
3. Flink提供内存级的计算速度和高可扩展性
2. Flink图解重点


技术改变世界

 浙公网安备 33010602011771号
浙公网安备 33010602011771号