
实践详细篇-Windows下使用VS2015编译的Caffe训练mnist数据集
上一篇记录的是学习caffe前的环境准备以及如何创建好自己需要的caffe版本。这一篇记录的是如何使用编译好的caffe做训练mnist数据集,步骤编号延用上一篇 《实践详细篇-Windows下使用VS2015编译安装Caffe环境(CPU ONLY) 》的顺序。
二:使用caffe做图像分类识别训练测试mnist数据集
1、下载MNIST数据集,MNIST数据集包含四个文件信息,见表格:
|
文件 |
内容 |
|
训练集图片 - 55000 张 训练图片, 5000 张 验证图片 |
|
|
训练集图片对应的数字标签 |
|
|
测试集图片 - 10000 张 图片 |
|
|
测试集图片对应的数字标签 |
下载完MNIST数据集包后打开\caffe根目录\examples\mnist并在其中创建一个文件夹mnist_data。并将其四个数据包进行解压到这个目录中。
注意:这四个文件不能直接用于caffe的训练和测试。需要使用编译好的caffe项目中的convert_mnist_data-d.exe文件来把四个文件转换为caffe所支持的leveldb或lmdb文件。convert_mnist_data-d.exe文件存在于caffe根目录\scripts\build\examples\mnist\Debug或Release目录下。选择区分取决于编译时是选择的Debug还是Release。
2、创建命令脚本来调用convert_mnist_data.exe数据转换工具
2.1 在caffe根目录下,新建一个convert-mnist-data-train.bat文件用于做转换训练数据,并在文件中添加如下代码:
scripts\build\examples\mnist\Debug\convert_mnist_data-d.exe --backend=lmdb examples\mnist\mnist_data\train-images.idx3-ubyte examples\mnist\mnist_data\train-labels.idx1-ubyte examples\mnist\mnist_data\mnist_train_lmdb pause
注意:scripts\build\examples\mnist\Debug\convert_mnist_data-d.exe 这个文件就是数据转换的工具,如果是使用Debug编译的 那文件将是convert_mnist_data-d.exe 如是Release编译的将是convert_mnist_data.exe 这个文件 。其中--backend=lmdb 表示转换为lmdb格式,这里设置的转换数据格式决定了后期使用时修改配置文件对应的格式。若要转换为leveldb将其改写为--backend=leveldb 即可。backend=leveldb后面的参数就是解压出来的数据集的文件路径。
leveldb和lmdb格式区别:
它们都是键/值对(Key/Value Pair)嵌入式数据库管理系统编程库。
虽然lmdb的内存消耗是leveldb的1.1倍,但是lmdb的速度比leveldb快10%至15%,更重要的是lmdb允许多种训练模型同时读取同一组数据集。
因此lmdb取代了leveldb成为Caffe默认的数据集生成格式。
2.2 再新建一个convert-mnist-data-test.bat转换测试数据,并在文件中添加如下代码:
scripts\build\examples\mnist\Debug\convert_mnist_data-d.exe --backend=lmdb examples\mnist\mnist_data\t10k-images.idx3-ubyte examples\mnist\mnist_data\t10k-labels.idx1-ubyte examples\mnist\mnist_data\mnist_test_lmdb Pause
2.3 运行两个脚本文件进行调用转换测试/训练数据
2.3.1 运行转换测试数据-convert-mnist-data-test.bat
切入到caffe根目录并Shift+鼠标右键选择“在此处打开命令窗口” 然后输入
start convert-mnist-data-test.bat
调用异常:
如出现以上情况,多数是因为文件夹的编码格式导致的,因为UTF-8的原因导致自动在文本最开始添加了一个空格内容导致的,解决方法很简单,重新编辑该文件并保存的时候将格式修改为 ANSI格式即可。
D:\DeepLearning\caffe\caffe>锘縮cripts\build\examples\mnist\Debug\convert_mnist_ data-d.exe --backend=lmdb examples\mnist\mnist_data\t10k-images.idx3-ubyte examp les\mnist\mnist_data\t10k-labels.idx1-ubyte examples\mnist\mnist_data\mnist_test _lmdb 系统找不到指定的路径。 D:\DeepLearning\caffe\caffe>Pause
调用成功:
以下代码就是命令反馈的转换成功示例
D:\DeepLearning\caffe\caffe>scripts\build\examples\mnist\Debug\convert_mnist_dat a-d.exe --backend=lmdb examples\mnist\mnist_data\t10k-images.idx3-ubyte examples \mnist\mnist_data\t10k-labels.idx1-ubyte examples\mnist\mnist_data\mnist_test_lm db I0427 09:47:11.591769 8508 db_lmdb.cpp:40] Opened lmdb examples\mnist\mnist_dat a\mnist_test_lmdb I0427 09:47:11.593770 8508 convert_mnist_data.cpp:93] A total of 10000 items. I0427 09:47:11.593770 8508 convert_mnist_data.cpp:94] Rows: 28 Cols: 28 I0427 09:47:11.983791 8508 db_lmdb.cpp:112] Doubling LMDB map size to 2MB ... I0427 09:47:12.180804 8508 db_lmdb.cpp:112] Doubling LMDB map size to 4MB ... I0427 09:47:12.514822 8508 db_lmdb.cpp:112] Doubling LMDB map size to 8MB ... I0427 09:47:13.059854 8508 db_lmdb.cpp:112] Doubling LMDB map size to 16MB ... I0427 09:47:13.225862 8508 convert_mnist_data.cpp:113] Processed 10000 files. D:\DeepLearning\caffe\caffe>Pause
2.3.2 运行转换训练数据
start convert-mnist-data-train.bat
调用成功:
D:\DeepLearning\caffe\caffe>scripts\build\examples\mnist\Debug\convert_mnist_dat a-d.exe --backend=lmdb examples\mnist\mnist_data\train-images.idx3-ubyte example s\mnist\mnist_data\train-labels.idx1-ubyte examples\mnist\mnist_data\mnist_train _lmdb I0427 09:50:03.852622 8384 db_lmdb.cpp:40] Opened lmdb examples\mnist\mnist_dat a\mnist_train_lmdb I0427 09:50:03.854622 8384 convert_mnist_data.cpp:93] A total of 60000 items. I0427 09:50:03.854622 8384 convert_mnist_data.cpp:94] Rows: 28 Cols: 28 I0427 09:50:03.942627 8384 db_lmdb.cpp:112] Doubling LMDB map size to 2MB ... I0427 09:50:04.006631 8384 db_lmdb.cpp:112] Doubling LMDB map size to 4MB ... I0427 09:50:04.131639 8384 db_lmdb.cpp:112] Doubling LMDB map size to 8MB ... I0427 09:50:04.398653 8384 db_lmdb.cpp:112] Doubling LMDB map size to 16MB ... I0427 09:50:05.002688 8384 db_lmdb.cpp:112] Doubling LMDB map size to 32MB ... I0427 09:50:06.283761 8384 db_lmdb.cpp:112] Doubling LMDB map size to 64MB ... I0427 09:50:08.547890 8384 convert_mnist_data.cpp:113] Processed 60000 files. D:\DeepLearning\caffe\caffe>pause
所有数据转换完成后可以在存放数据集文件目录下发现多出来了两个文件夹,并文件夹中都各有两个文件 分别lock.mdb和data.mdb
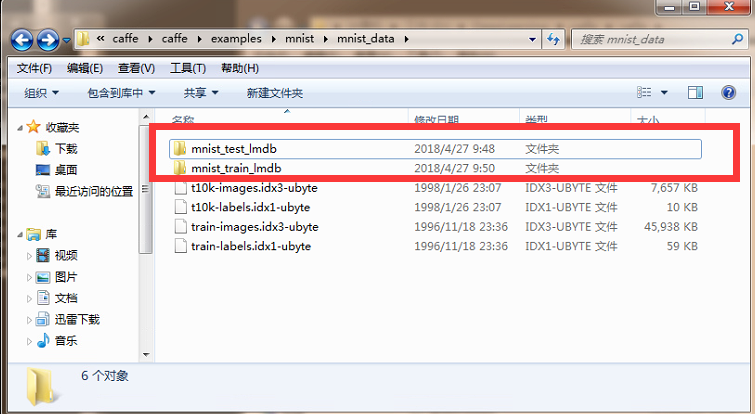
3、运行测试
3.1 拷贝转换好的测试文件以及训练文件到 caffe根目录\examples\mnist文件夹中 如图:

3.2 编写调用脚本
在caffe根目录下新建一个run.bat文件,文件中代码:
D:\DeepLearning\caffe\caffe\scripts\build\tools\Debug\caffe-d.exe train --solver=examples\mnist\lenet_solver.prototxt pause
注意:D:\DeepLearning\caffe\caffe\scripts\build\tools\Debug\caffe-d.exe 最好填写的是使用绝对路径。使用caffe-d.exe还是caffe.exe取决与你编译时选择的方式。caffe-d.exe存放于Debug下,caffe.exe存放Release目录下。
3.3 运行文件
确保万一,之前有提到过,在2.1步骤的时候说过,设置的转换数据格式决定后期调用文件的格式,所以我们需要先确认lenet_train_test.prototxt文件中的格式是否一致。
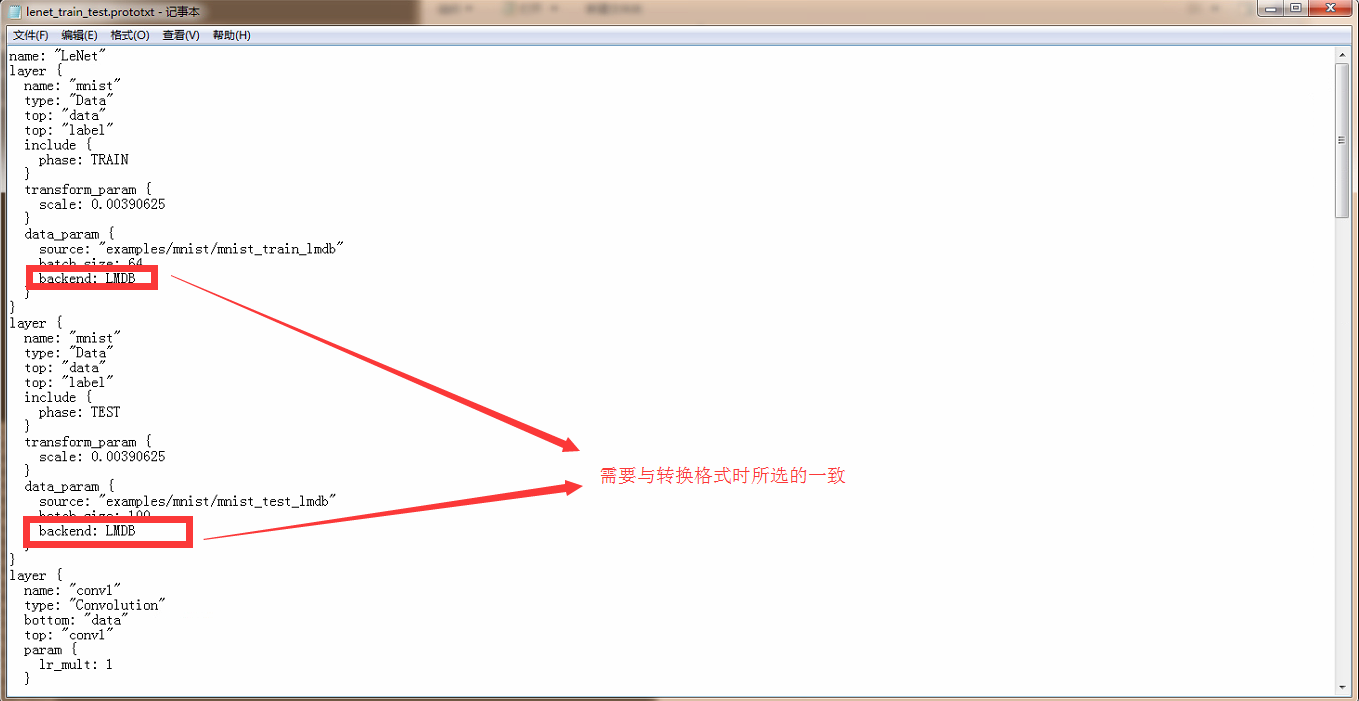
如这里的格式和在转换数据集的时候不一致 将需要修改为一致,简单的就是直接修改这里的配置文件格式改为leveldb或lmdb。不然就是在转换的时候修改为和这里一致。没问题的话我们直接运行:
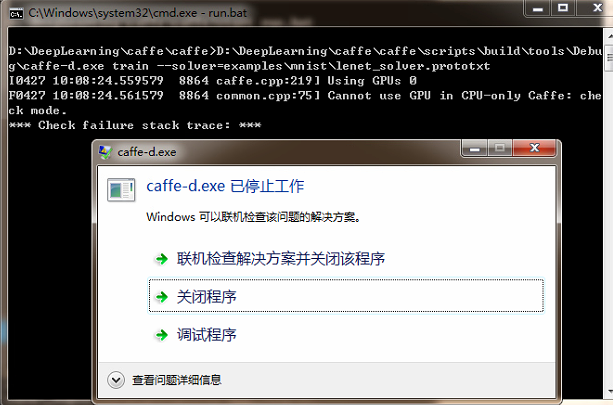
发现运行出现错误了,看错误反馈大致是因为选择的训练方式有问题,不能使用GPU。我们安装caffe时就说过,我们使用的是CPU训练。所以这里出现异常肯定是因为配置出问题了。我们打开 lenet_solver.prototxt文件看看:
# The train/test net protocol buffer definition net: "examples/mnist/lenet_train_test.prototxt" # test_iter specifies how many forward passes the test should carry out. # In the case of MNIST, we have test batch size 100 and 100 test iterations, # covering the full 10,000 testing images. test_iter: 100 # Carry out testing every 500 training iterations. test_interval: 500 # The base learning rate, momentum and the weight decay of the network. base_lr: 0.01 momentum: 0.9 weight_decay: 0.0005 # The learning rate policy lr_policy: "inv" gamma: 0.0001 power: 0.75 # Display every 100 iterations display: 100 # The maximum number of iterations max_iter: 10000 --指定了最大迭代次数 默认为10000次 # snapshot intermediate results snapshot: 5000 是输出中间结果,默认为迭代到5000次时输出中间结果。 snapshot_prefix: "examples/mnist/lenet" # solver mode: CPU or GPU solver_mode: GPU --此处应该应该为CPU 因为我们使用的是CPU训练
可以通过代码注释发现文本显示 “# solver mode: CPU or GPU” 意思是可以选择CPU或GPU,但是由于我们前期配置的是CPU,所以我们这里应该修改为CPU来训练。修改完成后我们继续执行run.bat
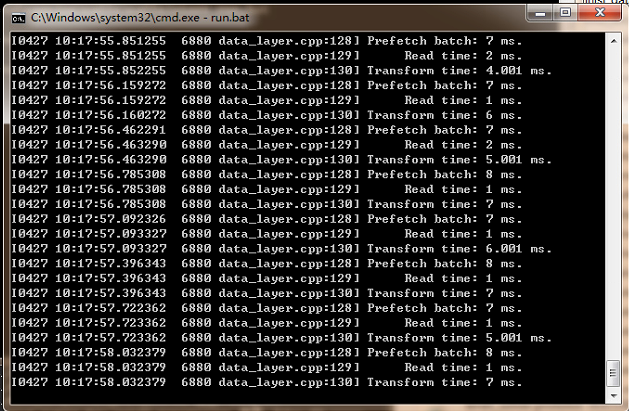
通过运行后的命令窗口反馈是已经正在训练提取特征了了,没报错表示成功了。
总结:
历经几天的学习和尝试,一路磕磕碰碰也总算是将caffe给弄起来了,虽然只是表面使用,并没有真正的达到“深度学习”,但是也是值的欣慰的。两篇博客下来会发现我完全没有提及任何枯燥乏味的理论知识,因为我深知有些牛逼的东西对于我们这种初学者而言不是要记住长篇大论的理论,而是在于自己能动手实践从中先获取到成就感,这样才会有兴趣学下去。我在某课堂也看了一点课程,发现整节课下来都是讲的理论知识,讲的卷积神经网络和循环神经网络等等,这些过于专业的理论知识有些时候反而会让我们这种新人无法理解,导致在一定程度上打压了兴趣。所以可见caffe可以让一个完全不懂卷及神经网络原理的人通过阅读相关编译、搭建知识来实现caffe图像分类识别等效果。当然这种效果只是适合初学者来提高兴趣爱好,真正的大牛还是需要不断的学习,更深入的了解深度学习的理论知识看来提升自我达到取得实质性的突破。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号