Solr8安装及整合Ikanalyzer7分词器
一、搜索功能的流行方案
由于搜索引擎功能在门户社区中对提高用户体验有着重在门户社区中涉及大量需要搜索引擎的功能需求,目前在实现搜索引擎的方案上有集中方案可供选择:
1、基于Lucene自己进行封装实现站内搜索。工作量及扩展性都较大,不采用。
2、调用Google、Baidu的API实现站内搜索。同第三方搜索引擎绑定太死,无法满足后期业务扩展需要,暂时不采用。
3、基于Compass+Lucene实现站内搜索。适合于对数据库驱动的应用数据进行索引,尤其是替代传统的like ‘%expression%’来实现对varchar或clob等字段的索引,对于实现站内搜索是一种值得采纳的方案。但在分布式处理、接口封装上尚需要自己进行一定程度的封装,暂时不采用。
4、基于Solr实现站内搜索。封装及扩展性较好,提供了较为完备的解决方案,因此在门户社区中采用此方案,后期加入Compass方案。
二、Solr简介
Solr是一个基于Lucene的Java搜索引擎服务器。Solr 提供了层面搜索、命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式)。它易于安装和配置,而且附带了一个基于 HTTP 的管理界面。Solr已经在众多大型的网站中使用,较为成熟和稳定。Solr 包装并扩展了 Lucene,所以Solr的基本上沿用了Lucene的相关术语。更重要的是,Solr 创建的索引与 Lucene 搜索引擎库完全兼容。通过对Solr 进行适当的配置,某些情况下可能需要进行编码,Solr 可以阅读和使用构建到其他 Lucene 应用程序中的索引。此外,很多 Lucene 工具(如Nutch、 Luke)也可以使用Solr 创建的索引。
三、安装
1、到官网下载solr:http://lucene.apache.org/solr/downloads.html
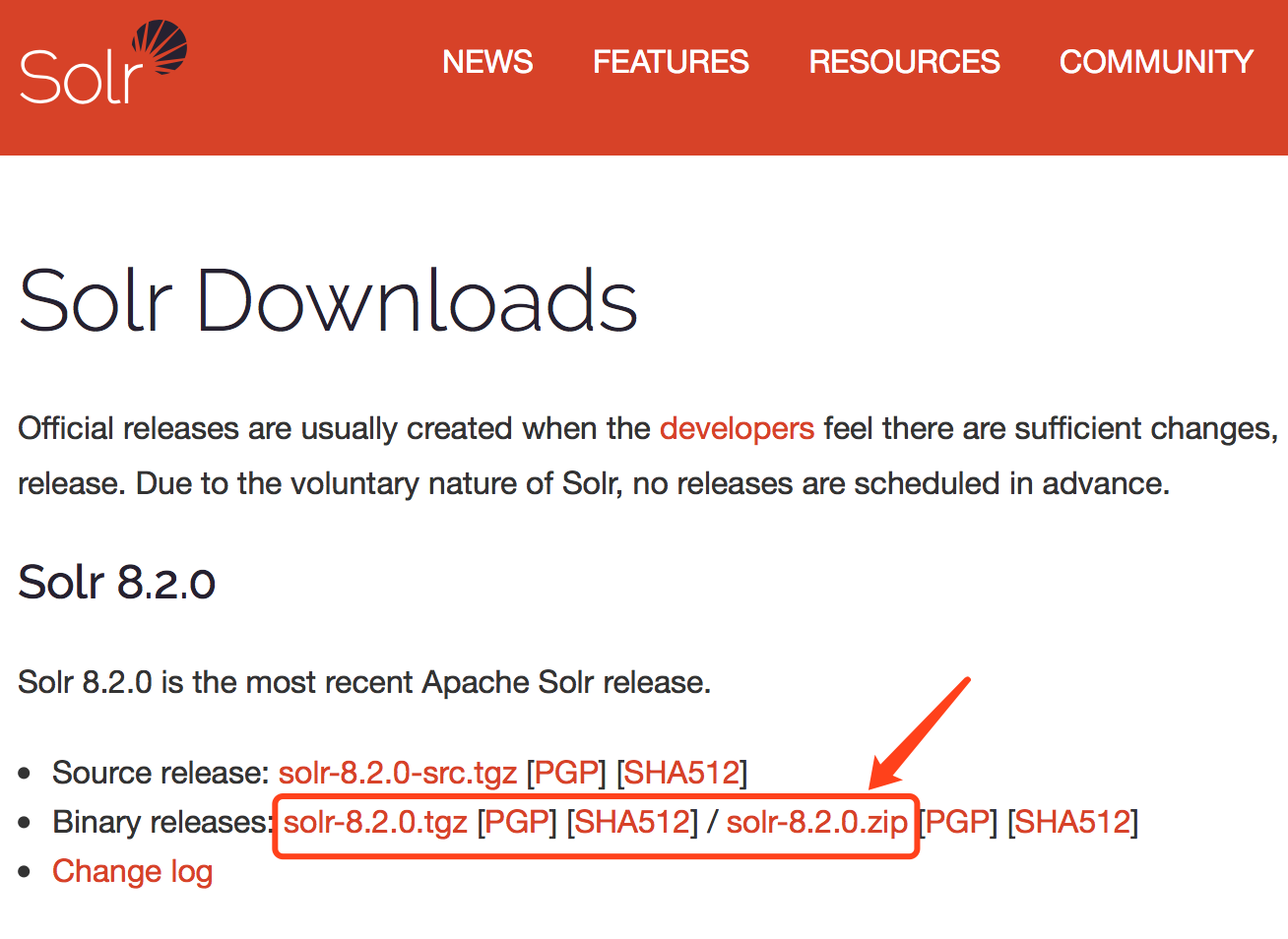
2、运行Solr程序
解压后打开目录:/solr-8.2.0/bin (在终端使用命令cd到该目录)
Mac/Linux运行命令:
./solr start
windows运行命令:
solr.cmd start
关闭命令分别为:
./solr stop -all
solr.cmd stop -all
命令运行后可以看到类似如下界面,说明solr服务器已经正常启动。
注意:Solr内置web容器为Jetty,所以必须先配置JAVA_HOME才可以正常启动Jetty。
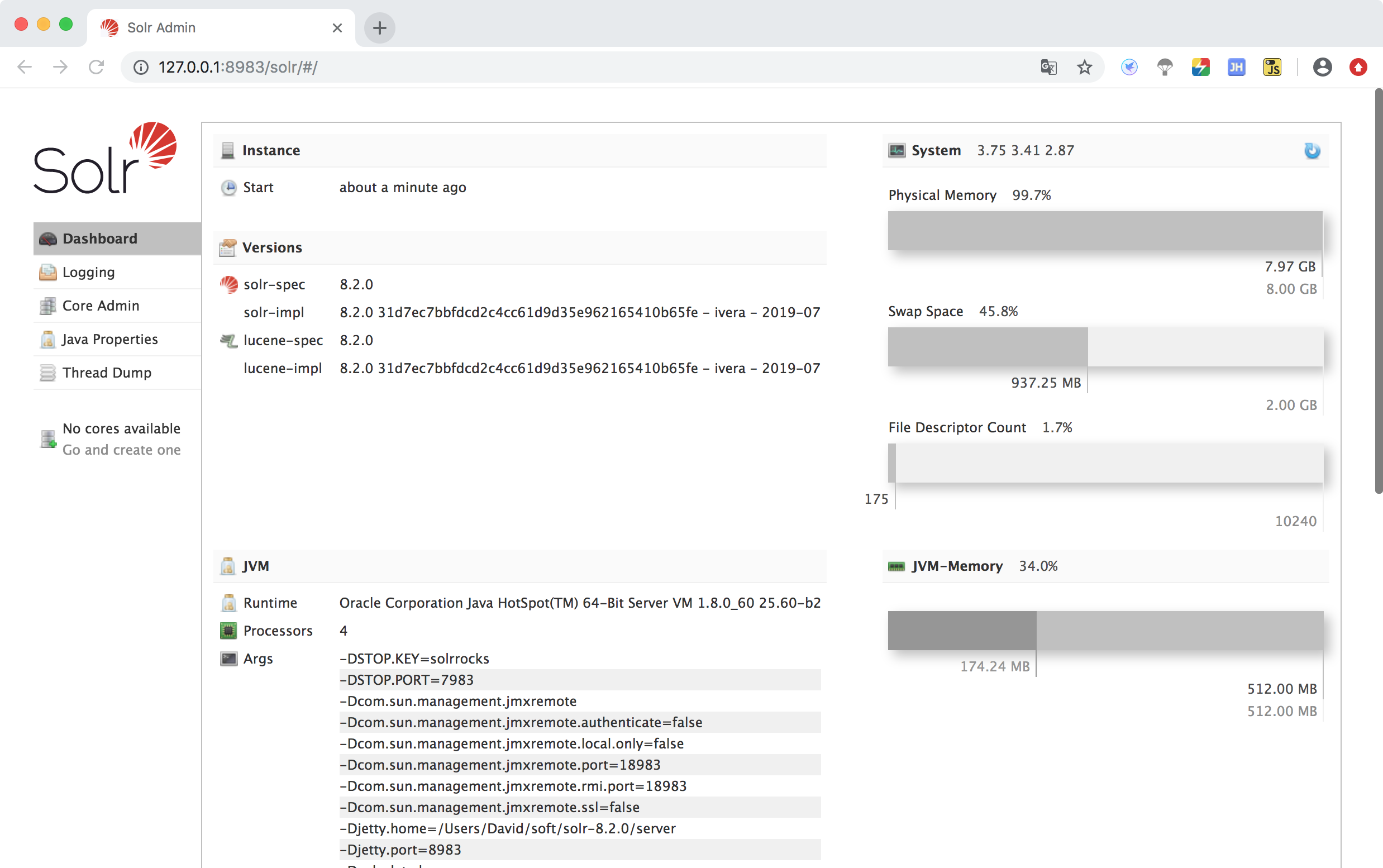
打开浏览器,访问页面:http://127.0.0.1:8983/solr
3、创建分词库collection/core
方法一:使用命令:solr.cmd create -c articles(官方推荐)
方法二:在/solr-8.2.0/server/solr/路径下创建文件夹articles(或任意名字)
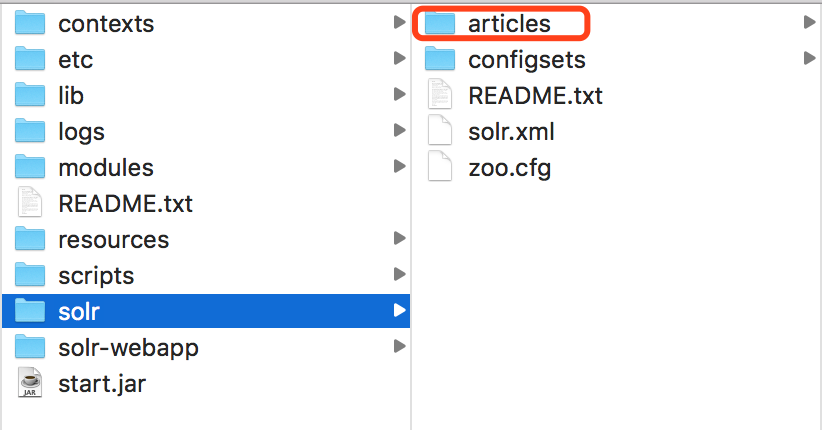
再把/solr-8.2.0/server/solr/configsets/_default/conf文件夹复制到新建的articles文件夹下
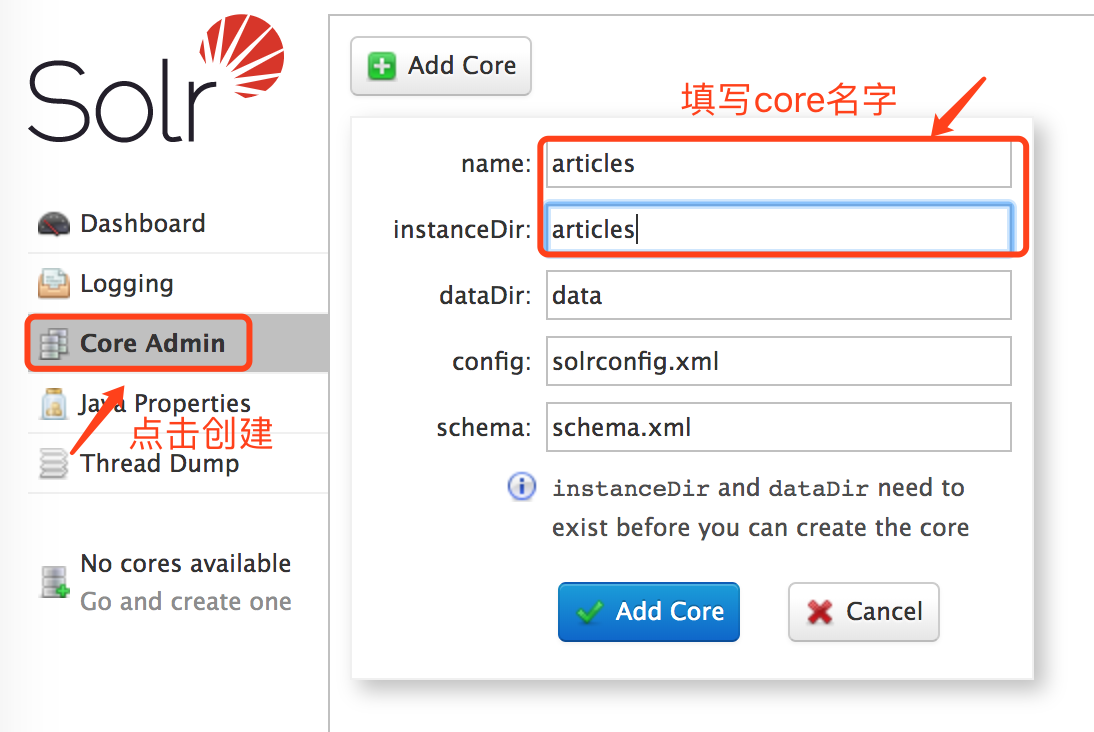
最后在浏览器的管理页面中创建core,注意名字和上一步创建的名字一直(articles)。
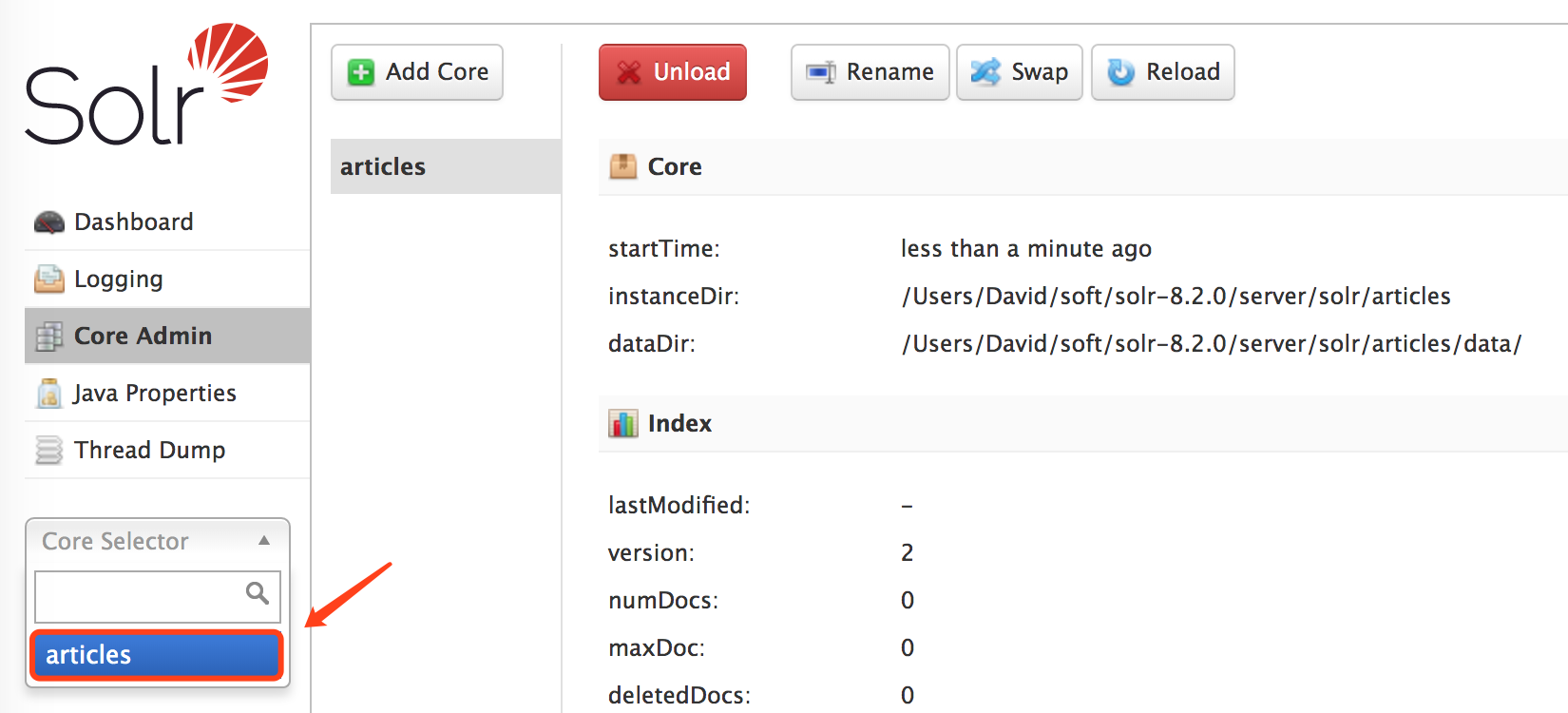
最后在下拉列表中选中创建的分词库即可开始使用Solr分词操作。
分词操作如下图所示:

由此可见分词的结果并不准确,原因是因为我们没有合适的中文分词库。
四、安装中文分词库
中文词库有两个常用的。ik-analyzer和mmeseg4j。这里使用ik-analyzer。另外此词库可以自己定义词库,例如可以用搜狗的词库。
分词库区别可以参考大神文章:https://www.2cto.com/kf/201611/569317.html
1、下载Ikanalyzer7.x分词器的jar文件,下载地址:https://search.maven.org/search?q=com.github.magese

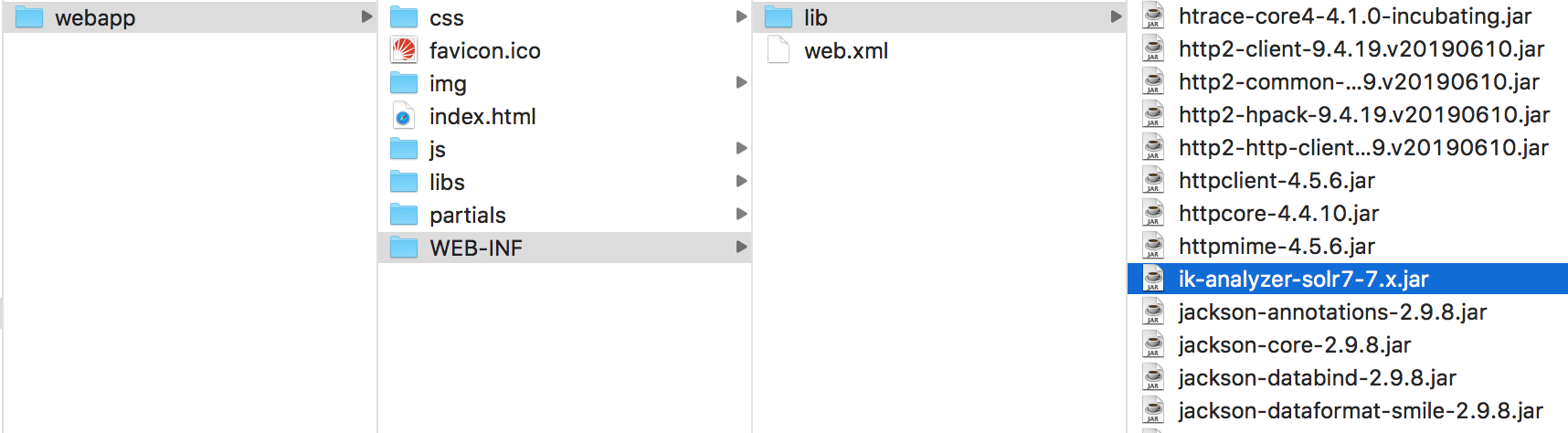
2、将分词库拷贝到Solr路径下:/solr-8.2.0/server/solr-webapp/webapp/WEB-INF/lib
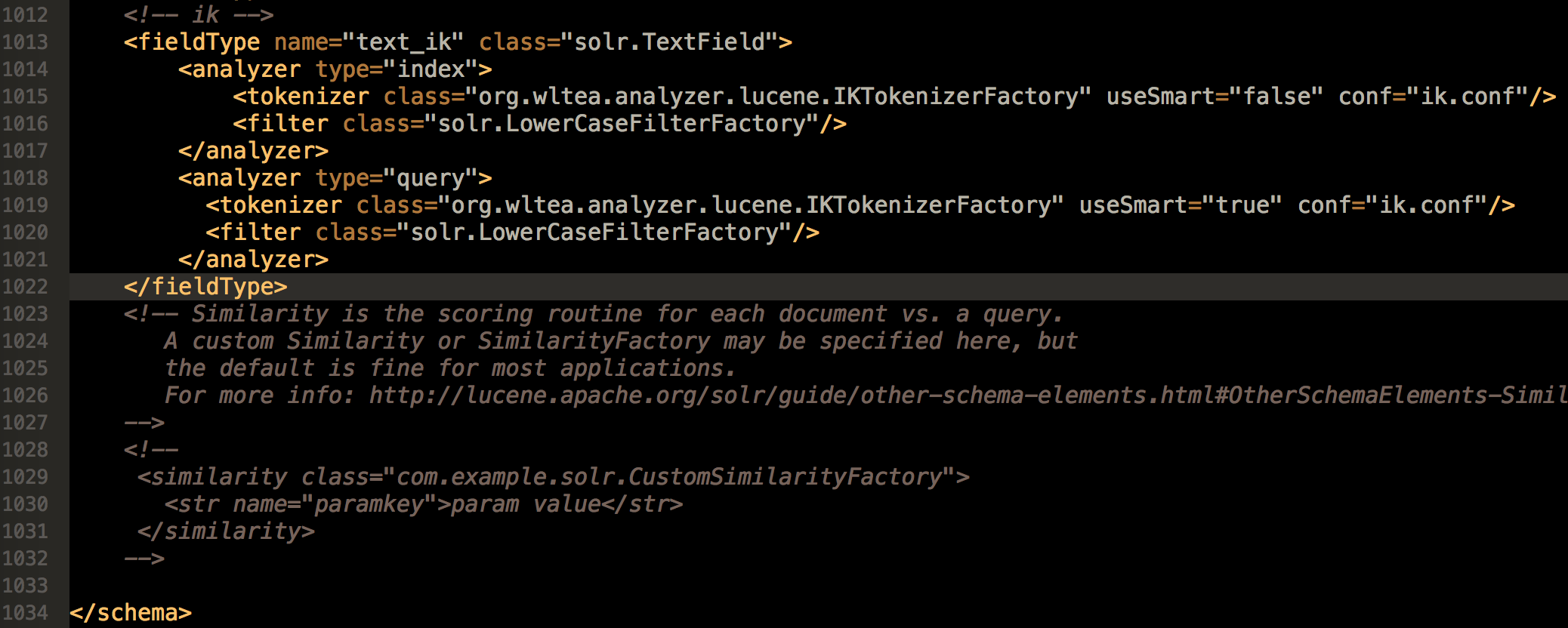
3、打开/solr-8.2.0/server/solr/articles/managed-schema 文件,在文件最后添加以下代码:
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
重启Solr服务
./solr restart
再次在浏览器中进行分词操作,可以看到结果:
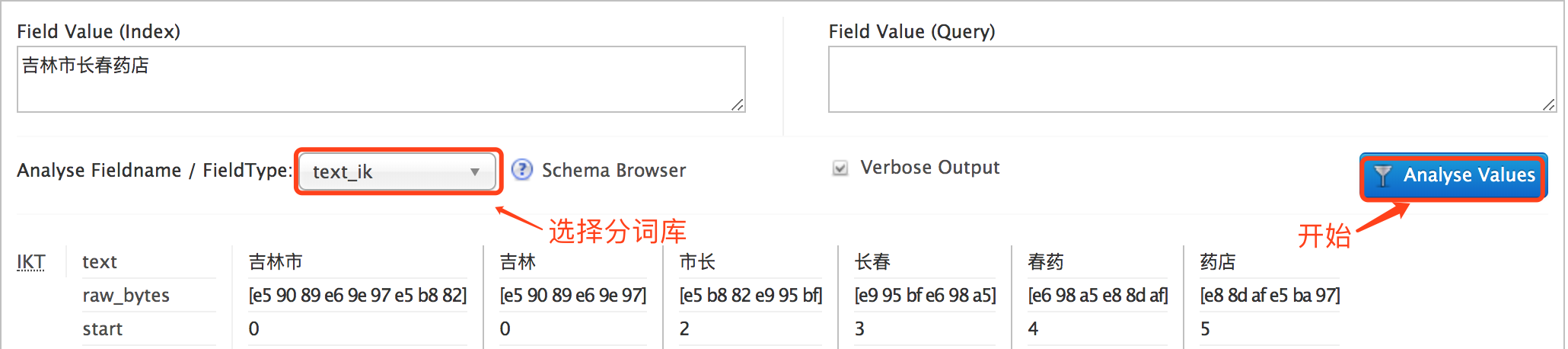
至此Solr中文分词库配置完毕。
参考大神文章:
https://blog.csdn.net/xiaokang123456kao/article/details/72844729
https://blog.csdn.net/zhouzhiwengang/article/details/90519320

 浙公网安备 33010602011771号
浙公网安备 33010602011771号