
【译】eBPF 概述:第 3 部分:软件开发生态
本系列导航:
- eBPF 概述:第 1 部分:介绍
- eBPF 概述:第 2 部分:机器和字节码
- eBPF 概述:第 3 部分:软件开发生态
- eBPF 概述:第 4 部分:在嵌入式系统运行
- eBPF 概述:第 5 部分:追踪用户进程
首发地址:https://ebpf.tophttps://www.ebpf.top/post/ebpf-overview-part-3/
发布时间: 2019-04-26
作者:Adrian Ratiu
翻译: 狄卫华
1. 前言
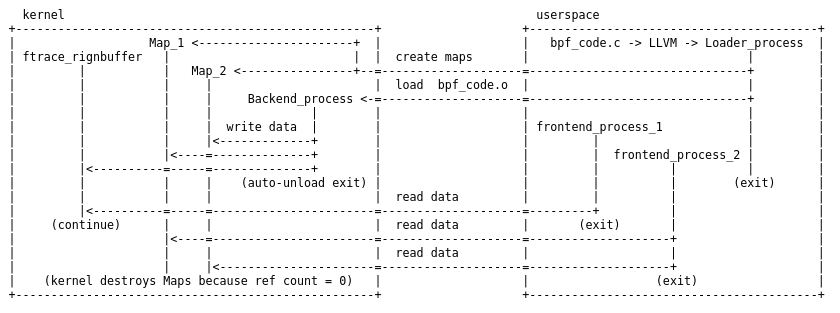
在本系列的第 1 部分和第 2 部分中,我们对 eBPF 虚拟机进行了简洁的深入研究。阅读上述部分并不是理解第 3 部分的必修课,尽管很好地掌握了低级别的基础知识确实有助于更好地理解高级别的工具。为了理解这些工具是如何工作的,我们先定义一下 eBPF 程序的高层次组件:
- 后端:这是在内核中加载和运行的 eBPF 字节码。它将数据写入内核 map 和环形缓冲区的数据结构中。
- 加载器:它将字节码后端加载到内核中。通常情况下,当加载器进程终止时,字节码会被内核自动卸载。
- 前端:从数据结构中读取数据(由后端写入)并将其显示给用户。
- 数据结构:这些是后端和前端之间的通信手段。它们是由内核管理的 map 和环形缓冲区,可以通过文件描述符访问,并需要在后端被加载之前创建。它们会持续存在,直到没有更多的后端或前端进行读写操作。
在第 1 部分和第 2 部分研究的 sock_example.c 中,所有的组件都被放置在一个 C 文件中,所有的动作都由用户进程完成。
eBPF 程序可以更加复杂:多个后端可以由一个(或单独的多个!)加载器进程加载,写入多个数据结构,然后由多个前端进程读取,所有这些都可以发生在一个跨越多个进程的用户 eBPF 应用程序中。
2. 层级 1:容易编写的后端:LLVM eBPF 编译器
我们在前面的文章中看到,在内核中编写原始的 eBPF 字节码是不仅困难而且低效,这非常像用处理器的汇编语言编写程序,所以很自然地开发了一个能够将 LLVM 中间表示编译成 eBPF 程序的模块,并从 2015 年的 v3.7 开始发布(GCC 到现在为止仍然不支持 eBPF)。这使得多种高级语言如 C、Go 或 Rust 的子集可以被编译到 eBPF。最成熟和最流行的是基于 C 语言编写的方式,因为内核也是用 C 写的,这样就更容易复用现有的内核头文件。
LLVM 将 "受限制的 C" 语言(记住,没有无界循环,最大 4096 条指令等等,见第 1 部分开始)编译成 ELF 对象文件,其中包含特殊区块(section),并可基于 bpf()系统调用,使用 libbpf 等库加载到内核中。这种设计有效地将后端定义从加载器和前端中分离出来,因为 eBPF 字节码包含在 ELF 文件中。
内核还在 samples/bpf/ 下提供了使用这种模式的例子:*_kern.c 文件被编译为 *_kern.o(后端代码),被 *_user.c(装载器和前端)加载。
将本系列第 1 和第 2 部分的 sock_exapmle.c 原始字节码 转换为 "受限的 C" 代码“ sockex1_kern.c,这比原始字节码更容易理解和修改。
#include <uapi/linux/bpf.h>
#include <uapi/linux/if_ether.h>
#include <uapi/linux/if_packet.h>
#include <uapi/linux/ip.h>
#include "bpf_helpers.h"
struct bpf_map_def SEC("maps") my_map = {
.type = BPF_MAP_TYPE_ARRAY,
.key_size = sizeof(u32),
.value_size = sizeof(long),
.max_entries = 256,
};
SEC("socket1")
int bpf_prog1(struct __sk_buff *skb)
{int index = load_byte(skb, ETH_HLEN + offsetof(struct iphdr, protocol));
long *value;
value = bpf_map_lookup_elem(&my_map, &index);
if (value)
__sync_fetch_and_add(value, skb->len);
return 0;
}
char _license[] SEC("license") = "GPL";
产生的 eBPF ELF 对象 sockex1_kern.o,包含了分离的后端和数据结构定义。加载器和前端sockex1_user.c,用于解析 ELF 文件、创建所需的 map 和加载字节码中内核函数 bpf_prog1(),然后前端像以前一样继续运行。
引入这个 "受限的 C" 抽象层所做的权衡是使 eBPF后端代码更容易用高级语言编写,代价是增加加载器的复杂性(现在需要解析 ELF 对象),而前端大部分不受影响。
3. 层级 2:自动化后端/加载器/前端的交互:BPF 编译器集合(BCC)
并不是每个人手头都有内核源码,特别是在生产中,而且一般来说,将基于 eBPF 工具与特定的内核源码版本捆绑在一起并不是一个好主意。设计和实现 eBPF 程序的后端,前端,加载器和数据结构之间的相互作用可能是非常复杂,这也比较容易出错和耗时(特别是在 C 语言中),这被认为是一种危险的低级语言。除了这些风险之外,开发人员还经常为常见问题重新造轮子,会造成无尽的设计变化和实现。为了减轻这些痛苦,社区创建了 BCC 项目:其为编写、加载和运行 eBPF 程序提供了一个易于使用的框架,除了上面举例的 "限制性 C" 之外,还可以通过编写简单的 python 或 lua 脚本来实现。
BCC 项目有两个部分。
- 编译器集合(BCC 本身):这是用于编写 BCC 工具的框架,也是我们文章的重点。请继续阅读。
- BCC-tools:这是一个不断增长的基于 eBPF 且经过测试的程序集,提供了使用的例子和手册。更多信息见本教程。
BCC 的安装包很大:它依赖于 LLVM/clang 将 "受限的 C"、python/lua 等编译成 eBPF,它还包含像 libbcc(用 C++ 编写)、libbpf 等库实现【译者注:原文 python/lua 顺序有错,另外 libcc 是 BCC 项目,libbpf 目前已经是内核代码一部分】。部分内核代码的也被复制到 BCC 代码中,所以它不需要基于完整的内核源(只需要头文件)进行构建。它可以很容易地占用数百 MB 的空间,这对于小型嵌入式设备来说不友好,我们希望这些设备也可以从 eBPF 的力量中受益。探索嵌入式设备由于大小限制问题的解决方案,将是我们在第 4 部分的重点。
eBPF 程序组件在 BCC 组织方式如下:
-
后端和数据结构:用 "限制性 C" 编写。可以在单独的文件中,或直接作为多行字符串存储在加载器/前端的脚本中,以方便使用。参见:语言参考。【译者注:在 BCC 实现中,后端代码采用面向对象的做法,真正生成字节码的时候,BCC 会进行一次预处理,转换成真正的 C 语言代码方式,这也包括 map 等数据结构的定义方面】。
-
加载器和前端:可用非常简单的高级 python/lua 脚本编写。参见:语言参考。
因为 BCC 的主要目的是简化 eBPF 程序的编写,因此它尽可能地标准化和自动化:在后台完全自动化地通过 LLVM 编译 "受限的 C"后端,并产生一个标准的 ELF 对象格式类型,这种方式允许加载器对所有 BCC 程序只实现一次,并将其减少到最小的 API(2 行 python)。它还将数据结构的 API 标准化,以便于通过前端访问。简而言之,它将开发者的注意力集中在编写前端上,而不必担心较低层次的细节问题。
为了最好地说明它是如何工作的,我们来看一个简单的具体例子,它是对前面文章中的 sock_example.c 的重新实现。该程序统计回环接口上收到了 TCP、UDP 和 ICMP 数据包的数量。

与此前直接用 C 语言编写的方式不同,用 BCC 实现具有以下优势:
- 忘掉原始字节码:你可以用更方便的 "限制性 C" 编写所有后端。
- 不需要维护任何 LLVM 的 "限制性 C" 构建逻辑。代码被 BCC 在脚本执行时直接编译和加载。
- 没有危险的 C 代码:对于编写前端和加载器来说,Python 是一种更安全的语言,不会出现像空解引用(null dereferences)的错误。
- 代码更简洁,你可以专注于应用程序的逻辑,而不是具体的机器问题。
- 脚本可以被复制并在任何地方运行(假设已经安装了 BCC),它不会被束缚在内核的源代码目录中。
- 等等。
在上面的例子中,我们使用了 BPF.SOCKET_FILTER 程序类型,其结果是我们挂载的 C 函数得到一个网络数据包缓冲区作为 context 上下文参数【译者注:本例中为 struct _sk_buff *skb】。我们还可以使用 BPF.KPROBE 程序类型来探测任意的内核函数。我们继续优化,不再使用与上面相同的接口,而是使用一个特殊的 kprobe_* 函数名称前缀,以描述一个更高级别的 BCC API。

这个例子来自于 bcc/examples/tracing/bitehist.py。它通过挂载在 blk_account_io_completion() 内核函数来打印一个 I/O 块大小的直方图。
请注意:eBPF 的加载是根据 kprobe__blk_account_io_completion() 函数的名称自动发生的(加载器隐含实现)! 【译者注:kprobe__ 前缀会被 BCC 编译代码过程中自动识别并转换成对应的附加函数调用】从用 libbpf 在 C 语言中编写和加载字节码以来,我们已经走了很远。
4. 层级 3:Python 太低级了:BPFftrace
在某些用例中,BCC 仍然过于底层,例如在事件响应中检查系统时,时间至关重要,需要快速做出决定,而编写 python/"限制性 C" 会花费太多时间,因此 BPFtrace 建立在 BCC 之上,通过特定领域语言(受 AWK 和 C 启发)提供更高级别的抽象。根据声明帖,该语言类似于 DTrace 语言实现,也被称为 DTrace 2.0,并提供了良好的介绍和例子。
BPFtrace 在一个强大而安全(但与 BCC 相比仍有局限性)的语言中抽象出如此多的逻辑,是非常让人惊奇的。这个单行 shell 程序统计了每个用户进程系统调用的次数(访问内置变量、map 函数 和count()文档获取更多信息)。
bpftrace -e 'tracepoint:raw_syscalls:sys_enter {@[pid, comm] = count();}'
BPFtrace 在某些方面仍然是一个正在进行的工作。例如,目前还没有简单的方法来定义和运行一个套接字过滤器来实现像我们之前所列举的 sock_example 这样的工具。它可能通过在 BPFtrace 中用 kprobe:netif_receive_skb 钩子完成,但这种情况下 BCC 仍然是一个更好的套接字过滤工具。在任何情况下(即使在目前的状态下),BPFTrace 对于在寻求 BCC 的全部功能之前的快速分析/调试仍然非常有用。
5. 层级 4:云环境中的 eBPF:IOVisor
IOVisor 是 Linux 基金会的一个合作项目,基于本系列文章中介绍的 eBPF 虚拟机和工具。它使用了一些非常高层次的热门概念,如 "通用输入/输出",专注于向云/数据中心开发人员和用户提供 eBPF 技术。
- 内核 eBPF 虚拟机成为 "IO Visor 运行时引擎"
- 编译器后端成为 "IO Visor 编译器后端"
- 一般的 eBPF 程序被重新命名为 "IO 模块"
- 实现包过滤器的特定 eBPF 程序成为 "IO 数据平面模块/组件"
- 等等。
考虑到原来的名字(扩展的伯克利包过滤器),并没有代表什么意义,也许所有这些重命名都是受欢迎和有价值的,特别是如果它能使更多的行业利用 eBPF 的力量。
IOVisor 项目创建了 Hover 框架,也被称为 "IO 模块管理器",它是一个管理 eBPF 程序(或 IO 模块)的用户空间后台服务程序,能够将 IO 模块推送和拉取到云端,这类似于 Docker daemon 发布/获取镜像的方式。它提供了一个 CLI,Web-REST 接口,也有一个花哨的 Web UI。Hover 的重要部分是用 Go 编写的,因此,除了正常的 BCC 依赖性外,它还依赖于 Go 的安装,这使得它体积变得很大,这并不适合我们最终在第 4 部分中的提及的小型嵌入式设备。
6. 总结
在这一部分,我们研究了建立在 eBPF 虚拟机之上的用户空间生态系统,以提高开发人员的工作效率和简化 eBPF 程序部署。这些工具使得使用 eBPF 非常容易,用户只需 "apt-get install bpftrace" 就可以运行单行程序,或者使用 Hover 守护程序将 eBPF 程序(IO 模块)部署到 1000 台机器上。然而,所有这些工具,尽管它们给开发者和用户提供了所有的力量,但却需要很大的磁盘空间,甚至可能无法在 32 位 ARM 系统上运行,这使得它们不是很适合小型嵌入式设备,所以这就是为什么在第 4 部分我们将探索其他项目,试图缓解运行针对嵌入式设备生态系统的 eBPF 程序。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号